Les modèles linguistiques à grande échelle ont montré des capacités de raisonnement surprenantes dans le traitement du langage naturel, mais leurs mécanismes sous-jacents ne sont pas encore clairs. Avec l’application généralisée des modèles de langage à grande échelle, l’élucidation des mécanismes de fonctionnement des modèles est cruciale pour la sécurité des applications, les limitations de performances et les impacts sociaux contrôlables. Récemment, de nombreux instituts de recherche en Chine et aux États-Unis (New Jersey Institute of Technology, Johns Hopkins University, Wake Forest University, University of Georgia, Shanghai Jiao Tong University, Baidu, etc.) ont publié conjointement l'interprétabilité des grands modèles technologie Cette revue examine de manière exhaustive les technologies d'interprétabilité des modèles de réglage fin traditionnels et des très grands modèles basés sur des invites, et discute des critères d'évaluation et des défis de recherche futurs pour l'interprétation des modèles. 
- Lien papier : https://arxiv.org/abs/2309.01029
-
Lien Github : https://github.com/hy-zhao23/Explainability-for-Large-Language-Models
Quelle est la difficulté d'interpréter les grands modèles ? Pourquoi est-il difficile d'expliquer les grands modèles ? Les performances étonnantes des grands modèles de langage sur les tâches de traitement du langage naturel ont attiré l’attention de la société. Dans le même temps, comment expliquer les performances étonnantes des grands modèles dans l’ensemble des tâches est l’un des défis urgents auxquels sont confrontés les universités. Différent des modèles traditionnels d'apprentissage automatique ou d'apprentissage profond, l'architecture de modèle ultra-large et le matériel d'apprentissage massif permettent aux grands modèles de disposer de puissantes capacités de raisonnement et de généralisation. Plusieurs difficultés majeures liées à l'interprétabilité des grands modèles de langage (LLM) incluent :
- Haute complexité du modèle. Différent des modèles d'apprentissage profond ou des modèles d'apprentissage automatique statistiques traditionnels avant l'ère LLM, les modèles LLM sont d'une ampleur considérable et contiennent des milliards de paramètres. Leurs processus de représentation et de raisonnement internes sont très complexes et il est difficile d'expliquer leurs résultats spécifiques.
- Forte dépendance aux données. Les LLM s'appuient sur un corpus de texte à grande échelle pendant le processus de formation. Les biais, les erreurs, etc. dans ces données de formation peuvent affecter le modèle, mais il est difficile de juger complètement l'impact de la qualité des données de formation sur le modèle.
- Boîte noire nature. Nous considérons généralement les LLM comme des modèles de boîte noire, même pour les modèles open source tels que Llama-2. Il nous est difficile de juger explicitement sa chaîne de raisonnement interne et son processus de prise de décision. Nous ne pouvons l'analyser qu'en fonction des entrées et des sorties, ce qui pose des difficultés d'interprétabilité.
- Incertitude de sortie. Le résultat des LLM est souvent incertain et différents résultats peuvent être produits pour le même intrant, ce qui augmente également la difficulté d’interprétabilité.
- Indicateurs d'évaluation insuffisants. Les indicateurs d’évaluation automatique actuels des systèmes de dialogue ne suffisent pas à refléter pleinement l’interprétabilité du modèle, et davantage d’indicateurs d’évaluation prenant en compte la compréhension humaine sont nécessaires.
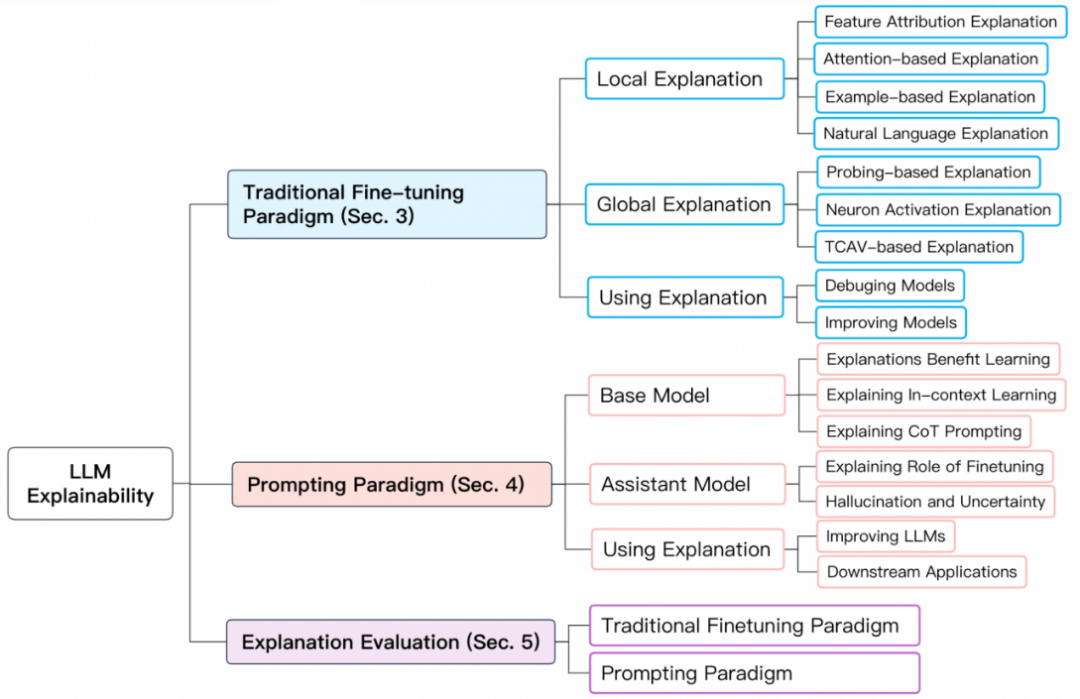
Paradigme de formation des grands modèlesAfin de mieux résumer l'interprétabilité des grands modèles, nous divisons les paradigmes de formation des grands modèles aux niveaux BERT et supérieurs en deux types : 1 ) Paradigme traditionnel de réglage fin ; 2) Paradigme basé sur l'incitation. Paradigme de réglage fin traditionnel Pour le paradigme de réglage fin traditionnel, pré-entraînez d'abord un modèle de langage de base sur une bibliothèque de texte non étiquetée plus grande, puis utilisez-le à partir d'un domaine spécifique Effectuez un réglage fin sur l’ensemble de données étiqueté. Ces modèles courants incluent BERT, RoBERTa, ELECTRA, DeBERTa, etc. Le paradigme basé sur les invites permet d'obtenir un apprentissage sans tir ou en quelques tirs en utilisant des invites. Comme pour le paradigme traditionnel de réglage fin, le modèle de base doit être pré-entraîné. Cependant, le réglage fin basé sur le paradigme d'incitation est généralement mis en œuvre par le réglage des instructions et l'apprentissage par renforcement à partir de la rétroaction humaine (RLHF). Ces modèles courants incluent GPT-3.5, GPT 4, Claude, LLaMA-2-Chat, Alpaca, Vicuna, etc. Le déroulement de la formation est le suivant : Explication du modèle basée sur le paradigme de réglage fin traditionnelL'explication du modèle basée sur le paradigme de réglage fin traditionnel comprend l'explication des prédictions individuelles (explication locale) et des composants de niveau structurel du modèle tels que les neurones, les couches de réseau, etc. .explication (explication globale). L'explication locale explique une prédiction d'un seul échantillon. Ses méthodes d'explication comprennent l'attribution de caractéristiques, l'explication basée sur l'attention, l'explication basée sur des exemples et l'explication en langage naturel.
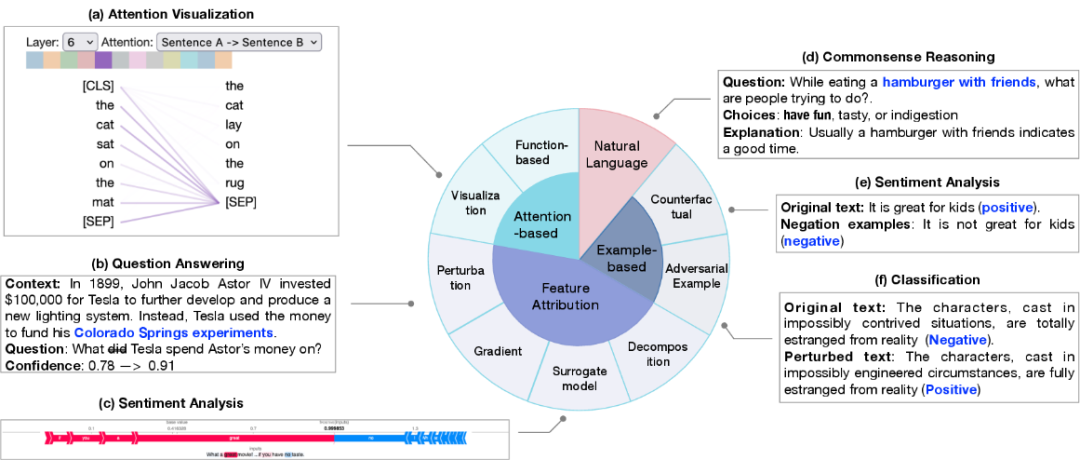
1. Le but de l'attribution de fonctionnalités est de mesurer la corrélation entre chaque fonctionnalité d'entrée (telle qu'un mot, une phrase, une plage de texte) et la prédiction du modèle. Les méthodes d'attribution de caractéristiques peuvent être divisées en :
Basée sur l'interprétation des perturbations, observation de l'impact sur le résultat de sortie en modifiant des caractéristiques d'entrée spécifiques
Basée sur l'interprétation du gradient, la différentielle partielle de la sortie vers l'entrée est utilisée comme l'entrée correspondante L'indice d'importance
-
2. Explication basée sur l'attention : l'attention est souvent utilisée comme un moyen de se concentrer sur les parties les plus pertinentes de l'entrée, de sorte que l'attention peut apprendre des informations pertinentes qui peuvent être utilisées pour expliquer les prédictions. Les méthodes courantes d'interprétation liées à l'attention comprennent :
- La technologie de visualisation de l'attention, qui observe intuitivement les changements dans les scores d'attention sur différentes échelles ;
- l'interprétation basée sur les fonctions, comme la sortie de l'effet de l'attention différentielle partielle. Cependant, l’utilisation de l’attention comme perspective de recherche reste controversée dans la communauté universitaire.
3. L'explication basée sur des échantillons détecte et explique le modèle du point de vue de cas individuels, qui est principalement divisé en : échantillons contradictoires et échantillons contrefactuels.
- Les échantillons contradictoires sont des données générées pour les caractéristiques du modèle qui sont très sensibles aux petits changements. Dans le traitement du langage naturel, ils sont généralement obtenus en modifiant le texte. conduisent à des prédictions différentes par le modèle.
- Les échantillons contrefactuels sont obtenus en déformant le texte comme la négation, qui est généralement un test de la capacité d'inférence causale du modèle.
4. L'explication en langage naturel utilise le texte original et des explications étiquetées manuellement pour la formation du modèle, afin que le modèle puisse générer des explications en langage naturel du processus de prise de décision du modèle. L'explication globale vise à fournir une compréhension d'ordre supérieur du mécanisme de fonctionnement des grands modèles à partir des niveaux du modèle, y compris les neurones, les couches cachées et les blocs plus grands. Il explore principalement les connaissances sémantiques apprises dans les différents composants du réseau.
- Interprétation basée sur une sonde La technologie d'interprétation de la sonde est principalement basée sur la détection d'un classificateur. Elle entraîne un classificateur superficiel sur un modèle pré-entraîné ou un modèle affiné, puis l'évalue sur un ensemble de données d'exclusion, de sorte que Les classificateurs sont capables d'identifier des caractéristiques du langage ou des capacités de raisonnement.
- Activation des neurones L'analyse traditionnelle de l'activation des neurones ne considère qu'une partie des neurones importants et apprend ensuite la relation entre les neurones et les caractéristiques sémantiques. Récemment, GPT-4 a également été utilisé pour expliquer les neurones. Au lieu de sélectionner certains neurones à expliquer, GPT-4 peut être utilisé pour expliquer tous les neurones.
- Interprétation basée sur les concepts : l'entrée est d'abord mappée à un ensemble de concepts, puis le modèle est interprété en mesurant l'importance des concepts pour la prédiction.
Explication du modèle basée sur le paradigme d'incitationL'explication du modèle basée sur le paradigme d'incitation nécessite des explications séparées du modèle de base et du modèle assistant pour distinguer les capacités des deux modèles et explorer l'apprentissage du modèle chemin. Les questions explorées comprennent principalement : les avantages de fournir des explications sur le modèle d'apprentissage en quelques étapes ; la compréhension de la source de l'apprentissage en quelques étapes et des capacités de la chaîne de réflexion. Explication de base du modèle
- Les avantages de l'explication pour l'apprentissage du modèle Découvrez si l'explication est utile pour l'apprentissage du modèle dans le cas d'un apprentissage en quelques étapes.
- Apprentissage situationnel Explorez le mécanisme de l'apprentissage contextuel dans les grands modèles et faites la distinction entre l'apprentissage contextuel dans les grands modèles et les modèles moyens.
- Invitation de la chaîne de réflexion Explorez les raisons pour lesquelles l'incitation de la chaîne de réflexion améliore les performances du modèle.
Explication du modèle d'assistant
- Le rôle des modèles d'assistant de réglage fin est généralement pré-entraîné pour acquérir des connaissances sémantiques générales, puis acquérir des connaissances du domaine par le biais d'un apprentissage supervisé et d'un renforcement apprentissage. Reste à étudier le stade d’où provient principalement la connaissance du modèle assistant.
- Illusion et incertitude L'exactitude et la crédibilité des prédictions des grands modèles restent des sujets importants de la recherche actuelle. Malgré les puissantes capacités d’inférence des grands modèles, leurs résultats souffrent souvent de désinformation et d’hallucinations. Cette incertitude dans la prévision pose d’énormes défis à son application généralisée.
Évaluation des explications du modèleLes indicateurs d'évaluation des explications du modèle incluent la plausibilité, la fidélité, la stabilité et la robustesse. L'article parle principalement de deux dimensions largement concernées : 1) la rationalité envers les humains ; 2) la fidélité à la logique interne du modèle ; L'évaluation des explications des modèles de mise au point traditionnels se concentre principalement sur les explications locales. La plausibilité nécessite souvent une évaluation des mesures des interprétations du modèle par rapport aux interprétations annotées par l'homme par rapport aux normes conçues. La fidélité accorde plus d'attention à la performance des indicateurs quantitatifs Étant donné que différents indicateurs se concentrent sur différents aspects du modèle ou des données, il manque encore des normes unifiées pour mesurer la fidélité. L’évaluation basée sur l’interprétation incitative du modèle nécessite des recherches plus approfondies.Défis futurs de la recherche 1. Manque d'explications valables et correctes. Le défi vient de deux aspects : 1) le manque de normes pour concevoir des explications efficaces ; 2) le manque d'explications efficaces conduit à un manque de soutien pour l'évaluation des explications. 2. L'origine du phénomène d'émergence est inconnue. L'exploration de la capacité d'émergence des grands modèles peut être réalisée respectivement du point de vue du modèle et des données, 1) la structure du modèle qui provoque le phénomène d'émergence 2) l'échelle minimale du modèle et ; complexité qui offre des performances supérieures dans les tâches multilingues. Du point de vue des données, 1) le sous-ensemble de données qui détermine une prédiction spécifique ; 2) la relation entre la capacité émergente et la formation du modèle et la contamination des données 3) l'impact de la qualité et de la quantité des données de formation sur les effets respectifs de la pré-formation ; formation et mise au point. 3. La différence entre le paradigme de réglage fin et le paradigme d'incitation. Les différentes performances de l'in-distribution et du hors-distribution impliquent des méthodes de raisonnement différentes. 1) Les différences dans les paradigmes de raisonnement lorsque les données sont distribuées ; 2) Les sources des différences dans la robustesse des modèles lorsque les données sont distribuées différemment. 4. Problème d'apprentissage des raccourcis pour les grands modèles. Sous les deux paradigmes, le problème de l'apprentissage raccourci du modèle existe sous différents aspects. Bien que les grands modèles disposent de sources de données abondantes, le problème de l’apprentissage rapide est relativement atténué. Élucider le mécanisme de formation de l’apprentissage raccourci et proposer des solutions restent importants pour la généralisation du modèle. 5. Attention redondance. Le problème de redondance des modules d'attention existe largement dans les deux paradigmes. L'étude de la redondance de l'attention peut fournir une solution pour la technologie de compression de modèles. 6.Sécurité et éthique. L'interprétabilité des grands modèles est essentielle pour contrôler le modèle et limiter l'impact négatif du modèle. Tels que les préjugés, l’injustice, la pollution de l’information, la manipulation sociale et d’autres problèmes. La création de modèles d'IA explicables peut efficacement éviter les problèmes ci-dessus et former des systèmes d'intelligence artificielle éthiques. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!