
Maison >Périphériques technologiques >IA >Nouveau titre : TextDiffuser : aucune crainte du texte dans les images, offrant un rendu de texte de meilleure qualité
Nouveau titre : TextDiffuser : aucune crainte du texte dans les images, offrant un rendu de texte de meilleure qualité

- 王林avant
- 2023-09-26 23:53:081602parcourir
Le domaine du Text-to-Image a fait d'énormes progrès ces dernières années, notamment à l'ère du contenu généré par l'intelligence artificielle (AIGC). Avec l'essor du modèle DALL-E, de plus en plus de modèles Text-to-Image ont émergé dans la communauté universitaire, tels que Imagen, Stable Diffusion, ControlNet et d'autres modèles. Cependant, malgré le développement rapide du domaine Text-to-Image, les modèles existants sont encore confrontés à certains défis pour générer de manière stable des images contenant du texte
Après avoir essayé le modèle sota text-to-image existant, nous pouvons constater que la partie texte généré par le modèle est fondamentalement illisible et similaire à des caractères tronqués, ce qui affecte grandement l'esthétique globale de l'image.

Les informations textuelles générées par le modèle de génération de texte sota existant sont peu lisibles
Après enquête, il y a moins de recherches dans ce domaine dans la communauté universitaire. En fait, les images contenant du texte sont très courantes dans la vie quotidienne, comme les affiches, les couvertures de livres et les panneaux de signalisation. Si l’IA peut générer efficacement de telles images, elle aidera les concepteurs dans leur travail, inspirera l’inspiration en matière de conception et réduira le fardeau de la conception. De plus, les utilisateurs peuvent souhaiter uniquement modifier la partie texte des résultats du modèle de diagramme de Vincent et conserver les résultats dans d'autres zones non textuelles.
Afin de ne pas changer le sens original, le contenu doit être réécrit en chinois. La phrase originale n'a pas besoin d'apparaître

- Adresse papier : https://arxiv.org/abs/2305.10855
- Adresse du projet : https://jingyechen.github.io/ textdiffuser/
- Adresse de code : https://github.com/microsoft/unilm/tree/master/textdiffuser
- Adresse de démonstration : https://huggingface.co/spaces/microsoft/TextDiffuser
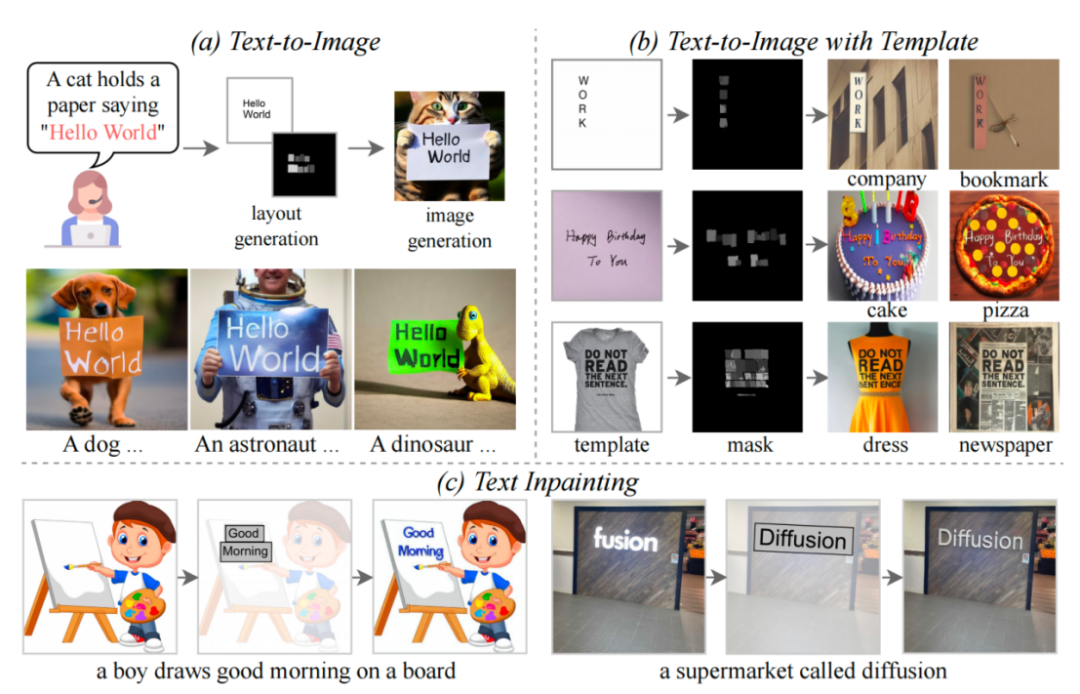
Trois fonctions de TextDiffuser
Cet article propose le modèle TextDiffuser, qui contient deux étapes, la première étape génère la mise en page et la deuxième étape génère des images.
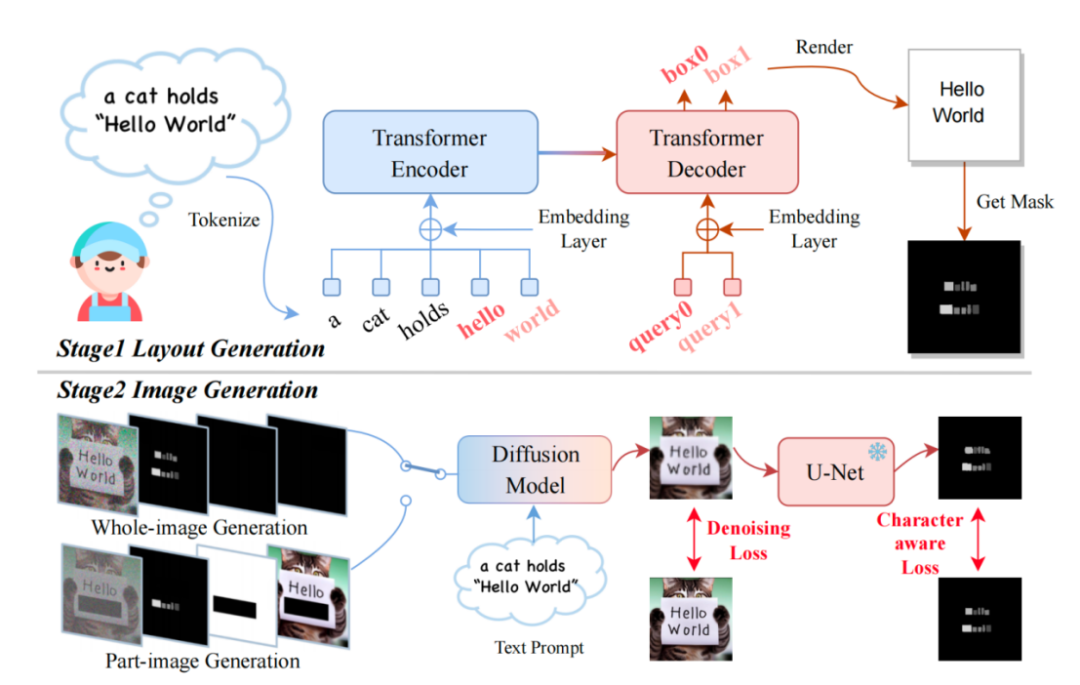
Ce qui doit être réécrit est : le diagramme du cadre TextDiffuser
Le modèle accepte une invite de texte, puis détermine la mise en page (c'est-à-dire la boîte de coordonnées) de chaque mot-clé en fonction des mots-clés dans l'invite. Les chercheurs ont utilisé Layout Transformer, un formulaire d'encodeur-décodeur pour afficher de manière autorégressive la boîte de coordonnées des mots-clés et la bibliothèque PILLOW de Python pour restituer le texte. Dans ce processus, vous pouvez également utiliser l'API prête à l'emploi de Pillow pour obtenir la boîte de coordonnées de chaque caractère, ce qui équivaut à obtenir le masque de segmentation au niveau de la boîte au niveau du caractère. Sur la base de ces informations, les chercheurs ont tenté d’affiner la diffusion stable.
Ils ont envisagé deux situations. La première est que l'utilisateur souhaite générer directement l'image entière (appelée génération d'image entière). Une autre situation est la génération d'images partielles, également appelée Text-inpainting dans le journal, ce qui signifie que l'utilisateur donne une image et doit modifier certaines zones de texte de l'image.
Afin d'atteindre les deux objectifs ci-dessus, les chercheurs ont repensé les caractéristiques d'entrée et augmenté la dimension des 4 dimensions d'origine à 17 dimensions. Ceux-ci incluent des caractéristiques d'image bruitée en 4 dimensions, des informations de caractères en 8 dimensions, un masque d'image en 1 dimension et des caractéristiques d'image non masquée en 4 dimensions. S’il s’agit d’une génération d’image entière, les chercheurs fixent la zone de masque à l’image entière ; à l’inverse, s’il s’agit d’une génération d’image partielle, seule une partie de l’image est masquée. Le processus de formation du modèle de diffusion est similaire à celui de LDM. Les amis qui sont intéressés par cela peuvent se référer à la description de la méthode dans l'article original
Dans la phase d'inférence, TextDiffuser a un mode d'utilisation très flexible, qui peut être divisé. en trois types :
- Générez des images basées sur les instructions données par l'utilisateur. De plus, si l'utilisateur n'est pas satisfait de la mise en page générée lors de la première étape de génération de mise en page, il peut modifier les coordonnées et le contenu du texte, ce qui augmente la contrôlabilité du modèle.
- Départ directement de la deuxième étape. Le résultat final est généré sur la base de l'image modèle, l'image modèle pouvant être une image de texte imprimée, une image de texte manuscrite ou une image de texte de scène. Les chercheurs ont spécialement formé un réseau de segmentation de jeux de caractères pour extraire la mise en page des images modèles.
- Commence également à partir de la deuxième étape. L'utilisateur donne l'image et précise la zone et le contenu du texte qui doivent être modifiés. Et cette opération peut être effectuée plusieurs fois jusqu'à ce que l'utilisateur soit satisfait des résultats générés.

Données MARIO construites
Afin de former TextDiffuser, les chercheurs ont collecté dix millions d'images texte, comme le montre la figure ci-dessus, dont trois sous-ensembles : MARIO-LAION, MARIO-TMDB et MARIO - OpenLibrary
Les chercheurs ont pris en compte plusieurs aspects lors du filtrage des données : par exemple, une fois l'image OCR, seules les images avec une quantité de texte de [1,8] sont conservées. Ils ont filtré les textes contenant plus de 8 textes, car ces textes contiennent souvent une grande quantité de texte dense et les résultats de l'OCR sont généralement moins précis, comme les journaux ou les dessins de conception complexes. De plus, ils définissent la zone de texte pour qu'elle soit supérieure à 10 %. Cette règle est définie pour éviter que la zone de texte ne soit trop petite dans l'image.
Après une formation sur l'ensemble de données MARIO-10M, les chercheurs ont mené des comparaisons quantitatives et qualitatives de TextDiffuser avec les méthodes existantes. Par exemple, dans la tâche globale de génération d'images, les images générées par notre méthode ont un texte plus clair et lisible, et la zone de texte est mieux intégrée à la zone d'arrière-plan, comme le montre la figure ci-dessous
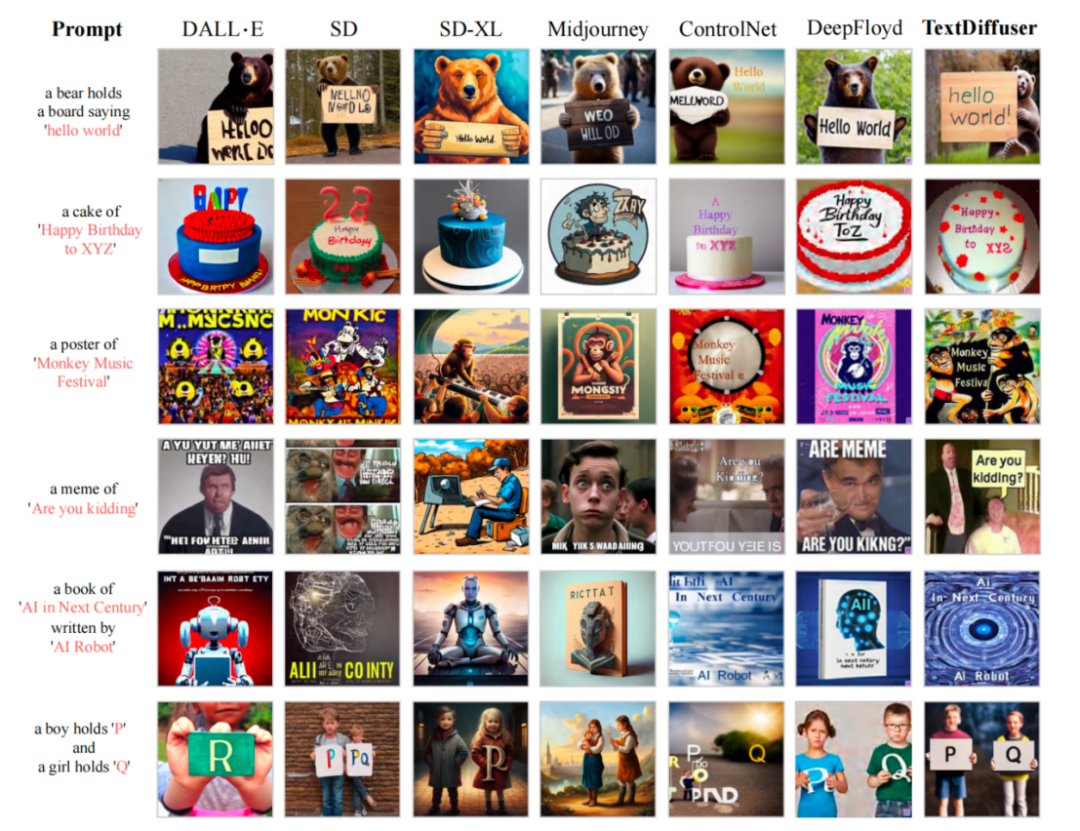
Comparaison du texte avec travaux existants Performances de rendu
Les chercheurs ont également mené une série d'expériences qualitatives et les résultats sont présentés dans le tableau 1. Les indicateurs d'évaluation incluent FID, CLIPScore et OCR. Surtout pour l'index OCR, cette méthode de recherche s'est considérablement améliorée par rapport à la méthode comparative
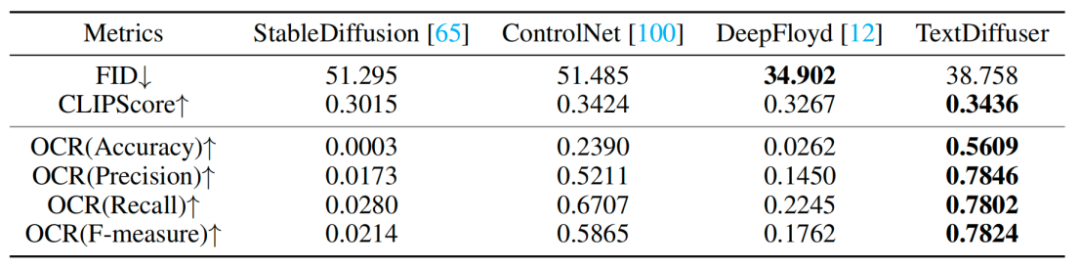
Contenu réécrit : Les résultats expérimentaux sont présentés dans le tableau 1 : Expérience qualitative
Pour la tâche de génération d'image partielle, le chercheur Essayez d'ajouter ou de modifier des caractères sur une image donnée, et les résultats expérimentaux montrent que TextDiffuser génère des résultats très naturels.

Visualisation de la fonction de réparation de texte
Dans l'ensemble, le modèle TextDiffuser proposé dans cet article a fait des progrès significatifs dans le domaine du rendu de texte et est capable de générer des images de haute qualité contenant du texte lisible. À l’avenir, les chercheurs amélioreront encore l’effet de TextDiffuser.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un modèle de développement logiciel et quels sont les modèles de développement logiciels courants ?
- Comment l'IA déplace-t-elle les graphiques ?
- Où est la superposition de l'IA ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?
- À quel modèle la structure du réseau à 7 couches fait-elle référence ?