
Maison >développement back-end >C++ >Qu'est-ce que le tri rapide en langage C ?
Qu'est-ce que le tri rapide en langage C ?

- DDDoriginal
- 2023-09-26 11:00:262000parcourir
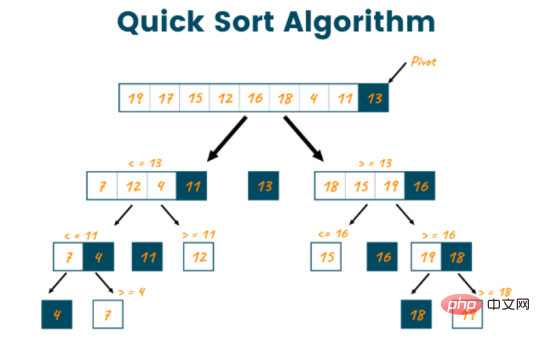
Quicksort est un algorithme de tri fréquemment utilisé en raison de sa popularité et de sa popularité par rapport aux autres algorithmes de tri. Il divise ensuite le tableau en deux groupes, l'un contenant des éléments plus petits que le pivot sélectionné et l'autre contenant des éléments plus grands que le pivot. Ensuite, l'algorithme répète ce processus pour chaque partition jusqu'à ce que l'ensemble du tableau soit trié.
Toute situation nécessitant un tri peut bénéficier du tri rapide, y compris les applications de bases de données, le calcul scientifique et les applications Web. Il est souvent utilisé lorsque de grands ensembles de données doivent être triés rapidement et efficacement. Voici quelques cas d'utilisation spécifiques où le tri rapide est souvent utilisé :
- Tri de tableaux dans des langages de programmation comme Python, Java et C.
- Tri des enregistrements de base de données pour les systèmes de gestion de bases de données.
- Triez de grands ensembles de données pour des applications de calcul scientifique telles que l'analyse de données et les simulations numériques.
- Organisez les résultats de recherche dans les applications en ligne et les paniers d'achat.
- Le tri rapide divise un tableau en deux parties en fonction de l'élément pivot (généralement le dernier élément du tableau).
- Divisez le tableau en deux partitions en plaçant tous les éléments plus petits que le pivot dans une partition et tous les éléments plus grands que le pivot dans une autre partition.
- L'algorithme répète ce processus pour chaque partition jusqu'à ce que l'ensemble du tableau soit trié.
- Si les données sont déjà triées ou si le pivot n'est pas soigneusement sélectionné, la complexité temporelle du tri rapide dans le pire des cas est O(n2).
- Le tri rapide est très efficace pour traiter de grands ensembles de données car sa complexité temporelle moyenne est de O(nlogn).
- Il s'agit d'un algorithme simple qui ne nécessite que quelques lignes de code pour être implémenté.
- Le tri rapide convient à une utilisation sur des systèmes multicœurs et distribués car il est facile à paralléliser.
- Comme il utilise le tri sur place, aucune mémoire supplémentaire n'est requise pour stocker des variables temporaires ou des structures de données.
- Si les données ont été triées ou si le pivot est mal sélectionné, la complexité temporelle dans le pire des cas du tri rapide est O(n2).
- L'ordre relatif des éléments égaux dans un tableau trié ne peut pas être garanti car il ne s'agit pas d'un algorithme de tri stable.
- Le tri rapide ne convient pas au tri de grands ensembles de données qui ne peuvent pas tenir en mémoire, car il nécessite plusieurs passages dans les données.
Caractéristiques
Avantages
Inconvénients
Conclusion
Quicksort est un algorithme de tri populaire et efficace qui fonctionne en divisant un tableau en deux parties et en effectuant le processus de manière itérative sur chaque partition jusqu'à ce que l'ensemble du tableau soit trié. Sa complexité temporelle moyenne et dans le meilleur des cas est O(nlogn), et sa complexité temporelle dans le pire des cas est O(n2). Malgré sa complexité temporelle plus élevée dans le pire des cas par rapport aux autres algorithmes de tri, le tri rapide est souvent privilégié pour ses performances, sa simplicité et sa facilité de mise en œuvre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!