
Maison >Périphériques technologiques >IA >Neuf méthodes d'analyse de l'importance des fonctionnalités Python couramment utilisées
Neuf méthodes d'analyse de l'importance des fonctionnalités Python couramment utilisées

- 王林avant
- 2023-09-22 12:09:031083parcourir
L'analyse de l'importance des fonctionnalités est utilisée pour comprendre l'utilité ou la valeur de chaque fonctionnalité (variable ou entrée) pour faire des prédictions. L'objectif est d'identifier les fonctionnalités les plus importantes qui ont le plus grand impact sur les résultats du modèle. Il s'agit d'une méthode souvent utilisée en apprentissage automatique.
Pourquoi l'analyse de l'importance des fonctionnalités est-elle importante ?
Si vous disposez d'un ensemble de données contenant des dizaines, voire des centaines de fonctionnalités, chaque fonctionnalité peut contribuer aux performances de votre modèle d'apprentissage automatique. Mais toutes les fonctionnalités ne sont pas égales. Certains peuvent être redondants ou non pertinents, ce qui augmente la complexité de la modélisation et peut conduire à un surajustement.
L'analyse de l'importance des fonctionnalités peut identifier et se concentrer sur les fonctionnalités les plus informatives, ce qui entraîne les avantages suivants : 1. Fournir des informations : en analysant l'importance des fonctionnalités, nous pouvons mieux comprendre quelles fonctionnalités des données ont le plus grand impact sur les résultats, nous aidant ainsi à mieux comprendre la nature des données. 2. Optimiser le modèle : en identifiant les fonctionnalités clés, nous pouvons optimiser les performances du modèle, réduire les frais de calcul et de stockage inutiles et améliorer l'efficacité de la formation et de la prédiction du modèle. 3. Sélection des fonctionnalités : l'analyse de l'importance des fonctionnalités peut nous aider à sélectionner les fonctionnalités ayant le pouvoir prédictif le plus élevé, améliorant ainsi la précision et la capacité de généralisation du modèle. 4. Expliquer le modèle : l'analyse de l'importance des fonctionnalités peut également nous aider à expliquer les résultats de prédiction du modèle, à révéler les modèles et les relations causales derrière le modèle et à améliorer l'interprétabilité du modèle. Ensemble
- Formation et inférence plus rapides .
- Interprétabilité améliorée
- Examinons de plus près certaines méthodes d'analyse de l'importance des fonctionnalités en Python.
- Méthode d'analyse de l'importance des fonctionnalités
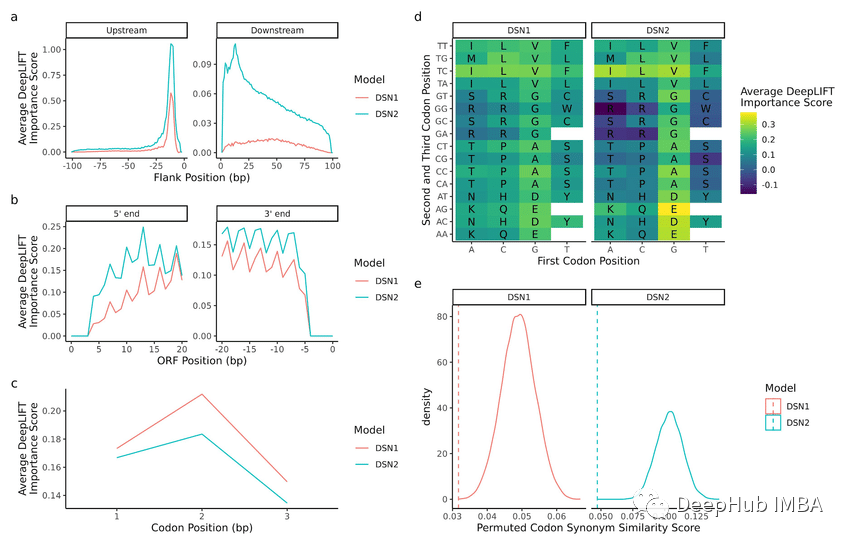
1. Permutation Importance PermutationImportance
Cette méthode organise de manière aléatoire les valeurs de chaque fonctionnalité, puis surveille le degré de dégradation des performances du modèle. Si la diminution est plus importante, cela signifie que la fonctionnalité est plus importantefrom sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier from sklearn.inspection import permutation_importance from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=1) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) baseline = rf.score(X_test, y_test) result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=1, scoring='accuracy') importances = result.importances_mean # Visualize permutation importances plt.bar(range(len(importances)), importances) plt.xlabel('Feature Index') plt.ylabel('Permutation Importance') plt.show()
2. Importance de la fonctionnalité intégrée (coef_ ou feature_importances_)
Certains modèles, tels que la régression linéaire et la forêt aléatoire, peuvent le faire. Sortez directement les scores d’importance des fonctionnalités. Ceux-ci montrent la contribution de chaque fonctionnalité à la prédiction finale.
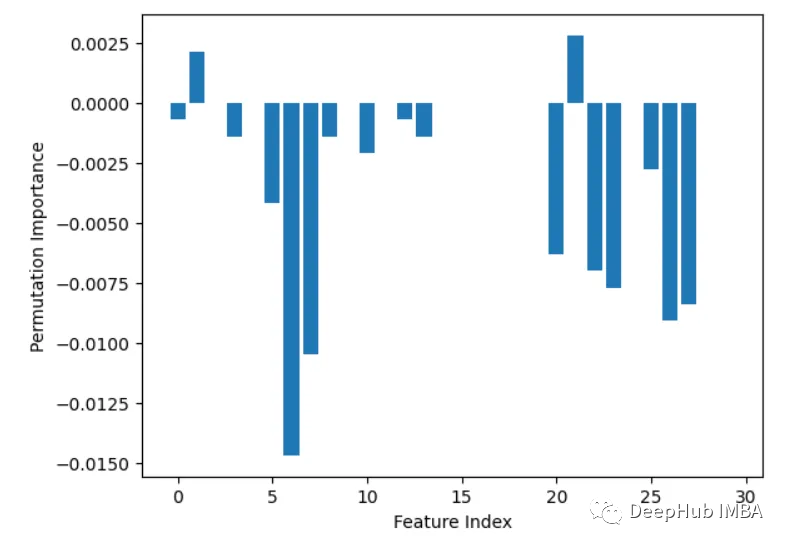
from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier X, y = load_breast_cancer(return_X_y=True) rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X, y) importances = rf.feature_importances_ # Plot importances plt.bar(range(X.shape[1]), importances) plt.xlabel('Feature Index') plt.ylabel('Feature Importance') plt.show()
3, Leave-one-out
Supprimez itérativement une fonctionnalité à la fois et évaluez la précision.
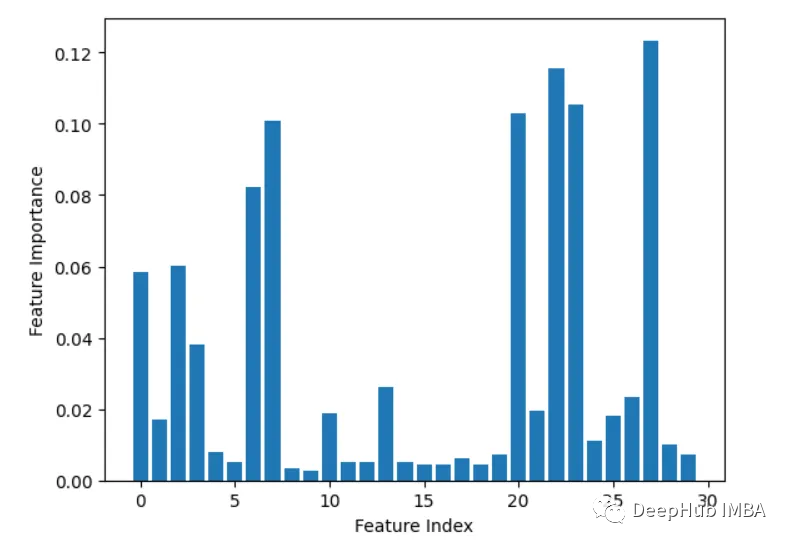
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import numpy as np # Load sample data X, y = load_breast_cancer(return_X_y=True) # Split data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # Train a random forest model rf = RandomForestClassifier(n_estimators=100, random_state=1) rf.fit(X_train, y_train) # Get baseline accuracy on test data base_acc = accuracy_score(y_test, rf.predict(X_test)) # Initialize empty list to store importances importances = [] # Iterate over all columns and remove one at a time for i in range(X_train.shape[1]):X_temp = np.delete(X_train, i, axis=1)rf.fit(X_temp, y_train)acc = accuracy_score(y_test, rf.predict(np.delete(X_test, i, axis=1)))importances.append(base_acc - acc) # Plot importance scores plt.bar(range(len(importances)), importances) plt.show()
4. Analyse de corrélation
Ce qui doit être réécrit est : Calculer la corrélation entre les caractéristiques et les variables cibles. Plus la corrélation est élevée, plus la fonctionnalité est importante
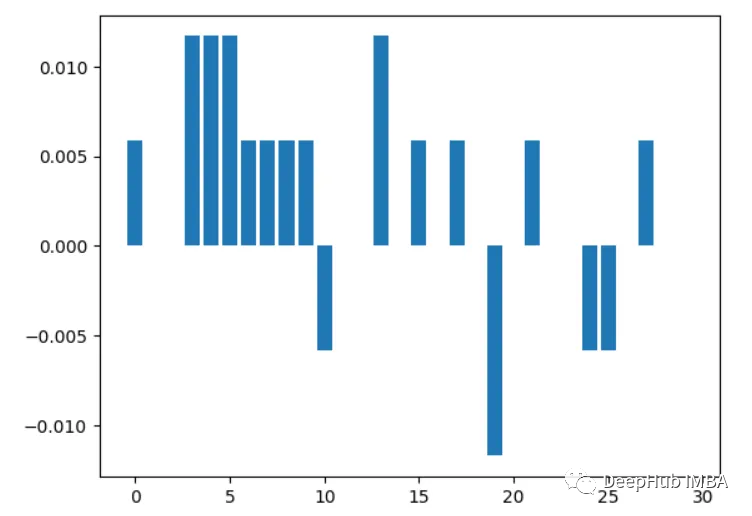
import pandas as pd from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y correlations = df.corrwith(df.y).abs() correlations.sort_values(ascending=False, inplace=True) correlations.plot.bar()
. 5. Élimination récursive des fonctionnalités
Supprimez de manière récursive les fonctionnalités et voyez comment cela affecte les performances du modèle. Les caractéristiques qui entraînent des chutes plus importantes une fois supprimées sont plus importantes.
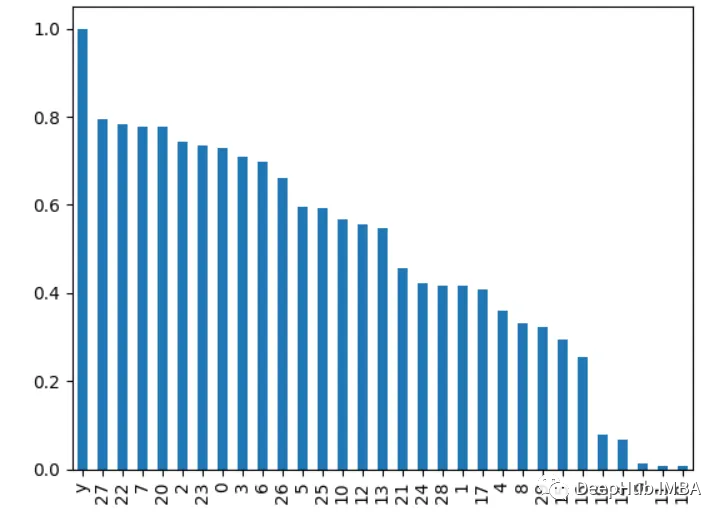
from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y rf = RandomForestClassifier() rfe = RFE(rf, n_features_to_select=10) rfe.fit(X, y) print(rfe.ranking_)
La sortie est [6 4 11 12 7 11 18 21 8 16 10 3 15 14 19 17 20 13 11 11 12 9 11 5 11]
6.
Calculer un Le nombre de fois que la fonctionnalité est utilisée dans toutes les arborescences lors du fractionnement des données. Plus de divisions signifie plus importantimport xgboost as xgb import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y model = xgb.XGBClassifier() model.fit(X, y) importances = model.feature_importances_ importances = pd.Series(importances, index=range(X.shape[1])) importances.plot.bar()
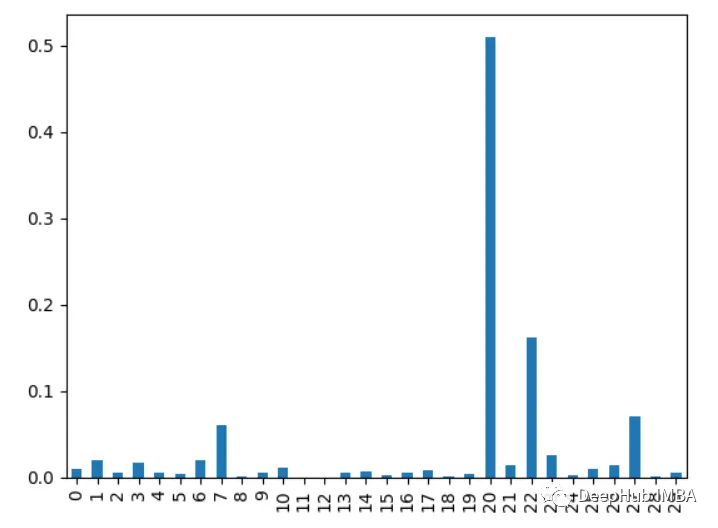
7. Analyse en composantes principales PCA
Effectuez une analyse en composantes principales sur les caractéristiques et examinez le rapport de variance expliqué de chaque composante principale. Les caractéristiques avec des charges plus élevées sur les premiers composants sont plus importantes.
from sklearn.decomposition import PCA import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y pca = PCA() pca.fit(X) plt.bar(range(pca.n_components_), pca.explained_variance_ratio_) plt.xlabel('PCA components') plt.ylabel('Explained Variance')
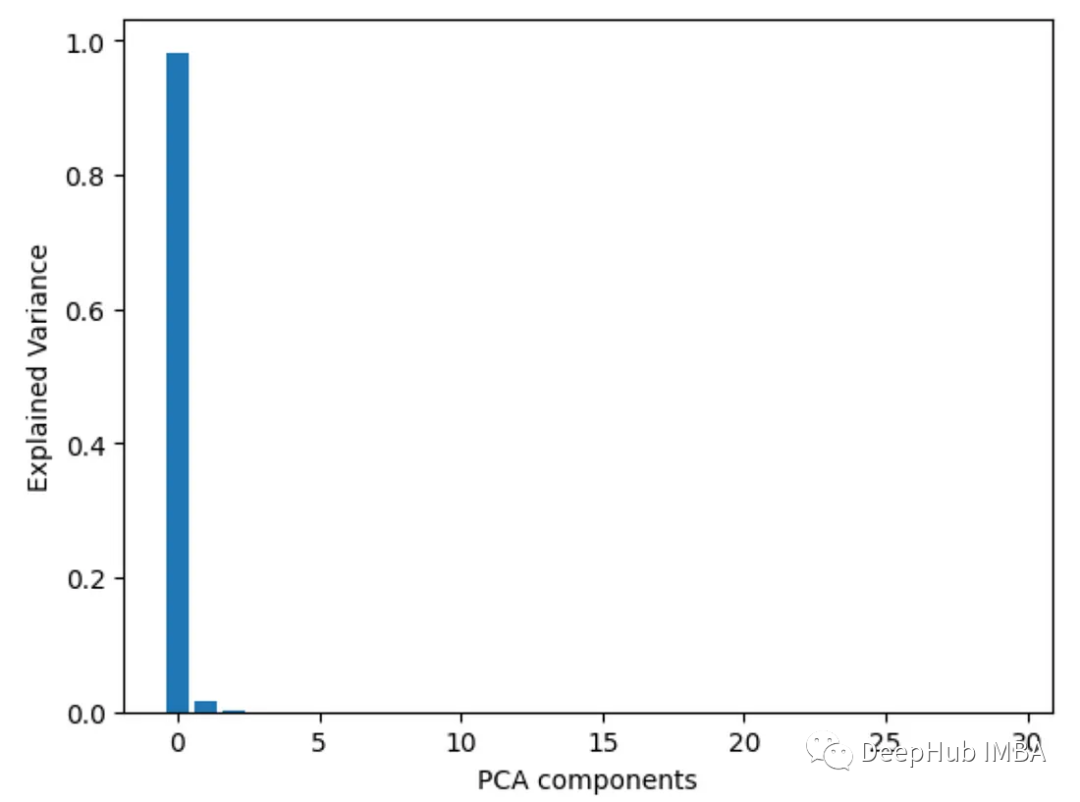
8. Analyse de la variance ANOVA
Utilisez f_classif() pour obtenir l'analyse de la valeur f de la variance de chaque caractéristique. Plus la valeur f est élevée, plus la corrélation entre la caractéristique et la cible est forte.
from sklearn.feature_selection import f_classif import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y fval = f_classif(X, y) fval = pd.Series(fval[0], index=range(X.shape[1])) fval.plot.bar()
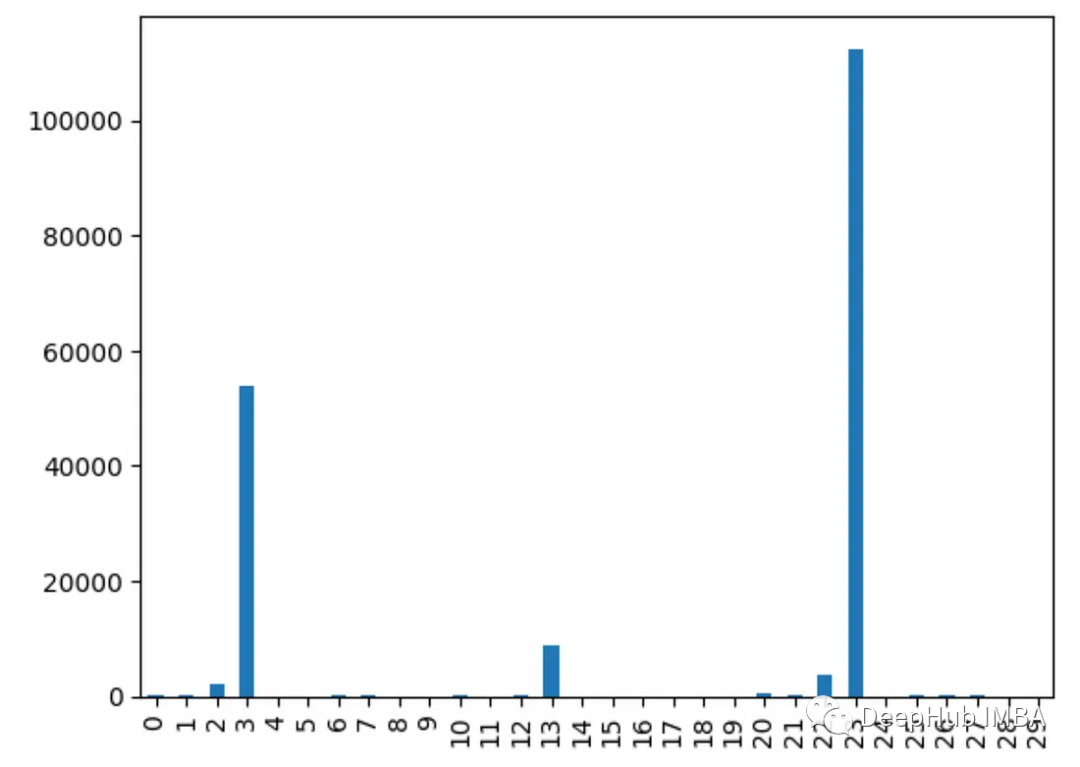
9. Test du chi carré
Utilisez la fonction chi2() pour obtenir les statistiques du chi carré de chaque caractéristique. Les fonctionnalités avec des scores plus élevés sont plus susceptibles d'être indépendantes de la variable cible
from sklearn.feature_selection import chi2 import pandas as pd from sklearn.datasets import load_breast_cancer import matplotlib.pyplot as plt X, y = load_breast_cancer(return_X_y=True) df = pd.DataFrame(X, columns=range(30)) df['y'] = y chi_scores = chi2(X, y) chi_scores = pd.Series(chi_scores[0], index=range(X.shape[1])) chi_scores.plot.bar()
为什么不同的方法会检测到不同的特征?
由于不同的特征重要性方法,有时可以确定哪些特征是最重要的
1、他们用不同的方式衡量重要性:
有的使用不同特特征进行预测,监控精度下降
像XGBOOST或者回归模型使用内置重要性来进行特征的重要性排序
而PCA着眼于方差解释
2、不同模型有不同模型的方法:
线性模型偏向于处理线性关系,而树模型则更倾向于捕捉接近根节点的特征
3、交互作用:
有些方法可以获取特征之间的相互关系,而有些方法则不行,这会导致结果的不同
3、不稳定:
使用不同的数据子集,重要性值可能在同一方法的不同运行中有所不同,这是因为数据差异决定的
4、Hyperparameters:
通过调整超参数,例如主成分分析(PCA)组件或决策树的深度,也会对结果产生影响
所以不同的假设、偏差、数据处理和方法的可变性意味着它们并不总是在最重要的特征上保持一致。
选择特征重要性分析方法的一些最佳实践
- 尝试多种方法以获得更健壮的视图
- 聚合结果的集成方法
- 更多地关注相对顺序,而不是绝对值
- 差异并不一定意味着有问题,检查差异的原因会对数据和模型有更深入的了解
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment empaqueter des fichiers Python dans des fichiers exe
- ce que python peut faire
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?
- Qu'est-ce que l'apprentissage automatique et où est-il couramment utilisé ?
- Quelle est la différence entre l'apprentissage profond et l'apprentissage automatique