
Maison >Périphériques technologiques >IA >Zhiyuan a ouvert 300 millions de données de formation de modèles vectoriels sémantiques et le modèle BGE continue d'être mis à jour de manière itérative.
Zhiyuan a ouvert 300 millions de données de formation de modèles vectoriels sémantiques et le modèle BGE continue d'être mis à jour de manière itérative.

- 王林avant
- 2023-09-21 21:33:111539parcourir
Avec le développement et l'application rapides des modèles à grande échelle, l'importance de l'intégration, qui est le composant de base des modèles à grande échelle, est devenue de plus en plus importante. Le modèle vectoriel sémantique chinois et anglais open source BGE (BAAI General Embedding), publié il y a un mois par la société Zhiyuan, a attiré l'attention de la communauté et a été téléchargé des centaines de milliers de fois sur la plateforme Hugging Face. Actuellement, BGE a lancé rapidement et de manière itérative la version 1.5 et annoncé plusieurs mises à jour. Parmi eux, BGE a pour la première fois ouvert 300 millions de données de formation à grande échelle, fournissant à la communauté une aide pour former des modèles similaires et promouvant le développement de la technologie dans ce domaine
- Lien de l'ensemble de données MTP : https://data.baai.ac.cn/details/BAAI-MTP
- Lien du modèle BGE : https://huggingface.co/BAAI
- Référentiel de code BGE : https: //www.php .cn / link / 8944871f1c9865a77a3d9c92cadf124d
300 millions de données de formation de modèle vectoriel chinois et de la première source open source Les données de formation vectorielle sémantique ont atteint 300 millions chinois et données anglaises
L'excellence de BGE Ses capacités proviennent en grande partie de ses données de formation diversifiées et à grande échelle. Auparavant, les pairs du secteur avaient rarement publié des ensembles de données similaires. Dans cette mise à jour, Zhiyuan ouvre pour la première fois les données de formation BGE à la communauté, jetant ainsi les bases du développement ultérieur de ce type de technologie.
L'ensemble de données MTP publié cette fois comprend un total de 300 millions de paires de textes liées au chinois et à l'anglais. Parmi eux, il y a 100 millions de documents en chinois et 200 millions de documents en anglais. Les sources de données incluent Wudao Corpora, Pile, DuReader, Sentence Transformer et d'autres corpus. Obtenu après échantillonnage, extraction et nettoyage nécessaires
Pour plus de détails, veuillez vous référer au Data Hub : https://data.baai.ac.cn
MTP est le plus grand ensemble de données open source sur les paires de textes chinois-anglais à ce jour, fournissant une base importante pour la formation de modèles vectoriels sémantiques chinois et anglais.
En réponse à la communauté des développeurs, mise à niveau de la fonction BGE
Sur la base des commentaires de la communauté, BGE a été encore optimisé sur la base de sa version 1.0 pour rendre ses performances plus stables et exceptionnelles. Le contenu spécifique de la mise à niveau est le suivant :
Mise à jour du modèle. BGE-*-zh-v1.5 atténue le problème de distribution de similarité en filtrant les données d'entraînement, en supprimant les données de mauvaise qualité et en augmentant le coefficient de température pendant l'entraînement à 0,02, ce qui rend la valeur de similarité plus stable.
- Nouveau modèle ajouté. Le modèle d'encodeur croisé BGE-reranker open source peut trouver le texte pertinent avec plus de précision et prend en charge les langues bilingues chinois et anglais. Différent du modèle vectoriel qui doit générer des vecteurs, BGE-reranker génère directement la similarité entre les paires de textes et a une précision de classement plus élevée. Il peut être utilisé pour réorganiser les résultats du rappel de vecteurs et améliorer la pertinence des résultats finaux.
- Nouvelles fonctionnalités. BGE1.1 ajoute un script d'exploration d'échantillons difficiles à négatifs. Les échantillons difficiles à négatifs peuvent améliorer efficacement l'effet de récupération après le réglage fin ; la fonction d'ajout d'instructions pendant le réglage fin est ajoutée au modèle de réglage fin ; la sauvegarde sera également automatiquement convertie au format de transformateur de phrase, ce qui facilitera le chargement du modèle.
- Il convient de mentionner que récemment, Zhiyuan et Hugging Face ont publié un rapport technique proposant d'utiliser C-Pack pour améliorer le modèle vectoriel sémantique universel chinois.
"C-Pack : ressources packagées pour faire progresser l'intégration du chinois général"
Lien : https://arxiv.org/pdf/2309.07597.pdf
Gagner une grande popularité dans la communauté des développeurs
BGE a attiré l'attention d'une large communauté de développeurs de modèles depuis sa sortie. Actuellement, Hugging Face a été téléchargé des centaines de milliers de fois et a été intégré et utilisé par des projets open source bien connus tels que LangChain, LangChain-Chachat, llama_index, etc.
Les responsables de Langchain, le co-fondateur et PDG de LangChain, Harrison Chase, le fondateur de Deep trading, Yam Peleg, et d'autres influenceurs de la communauté ont exprimé leur inquiétude à propos de BGE.
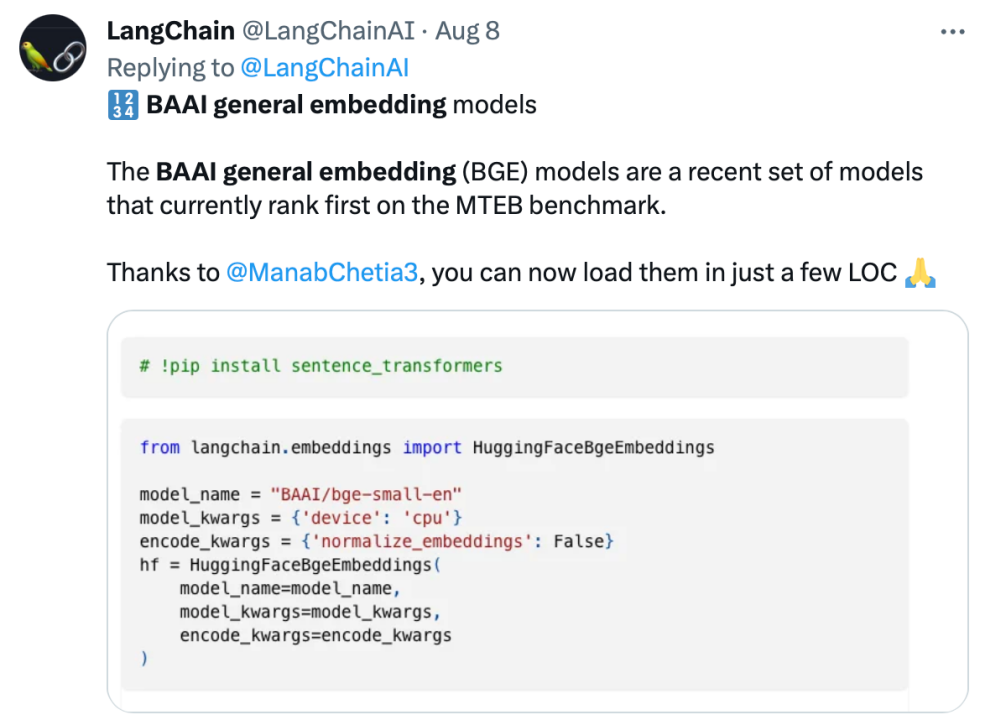
Adhérant à l'open source et à l'ouverture, promouvant l'innovation collaborative, le système de développement technologique de grands modèles de Zhiyuan, FlagOpen BGE, a ajouté une nouvelle section FlagEmbedding, axée sur la technologie et les modèles d'intégration. BGE est l'un des projets open source de haut niveau. FlagOpen s'engage à construire une infrastructure technologique d'intelligence artificielle à l'ère des grands modèles et continuera à ouvrir des technologies full-stack de grands modèles plus complètes au monde universitaire et à l'industrie à l'avenir
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel logiciel est le plugin Tencent Qqmail ?
- Quelle est la touche de raccourci pour fusionner des calques dans AI ?
- Il y a des indices cachés dans l'article GPT-4 : GPT-5 pourrait terminer la formation et OpenAI approchera AGI d'ici deux ans
- Volcano Engine aide Shenzhen Technology à lancer le premier modèle de pré-entraînement moléculaire 3D du secteur, Uni-Mol
- NUS et Byte ont collaboré de manière intersectorielle pour obtenir une formation 72 fois plus rapide grâce à l'optimisation des modèles, et ont remporté le prix AAAI2023 Outstanding Paper.