
Maison >Périphériques technologiques >IA >Comment DSA dépasse-t-il le GPU NVIDIA dans un coin ?
Comment DSA dépasse-t-il le GPU NVIDIA dans un coin ?

- 王林avant
- 2023-09-20 18:09:091777parcourir
Vous avez peut-être entendu les opinions pointues suivantes :
1. Si vous suivez la voie technique de NVIDIA, vous ne pourrez peut-être jamais rattraper NVIDIA.
2. DSA a peut-être une chance de rattraper NVIDIA, mais la situation actuelle est que DSA est sur le point de disparaître et il n'y a aucun espoir en vue
D'un autre côté, nous savons tous que les grands modèles sont désormais à l'avant-garde, et de nombreuses personnes dans l'industrie souhaitent fabriquer des puces de grands modèles, de nombreuses personnes souhaitent également investir dans des puces de grands modèles.
Mais quelle est la clé de la conception de puces grand modèle ? Tout le monde semble connaître l'importance d'une large bande passante et d'une grande mémoire, mais en quoi la puce est-elle différente de NVIDIA ?
Avec des questions, cet article tente de vous donner un peu d'inspiration.
Les articles purement basés sur des opinions semblent souvent formalistes. Nous pouvons illustrer cela à travers un exemple architectural
SambaNova Systems est connue comme l'une des dix plus grandes entreprises licornes aux États-Unis. En avril 2021, la société a reçu 678 millions de dollars d'investissement de série D dirigé par SoftBank, avec une valorisation atteignant 5 milliards de dollars, ce qui en fait une société super licorne. Auparavant, les investisseurs de SambaNova comprenaient les plus grands fonds de capital-risque au monde tels que Google Ventures, Intel Capital, SK et Samsung Catalytic Fund. Alors, quelles sont les activités perturbatrices que fait cette super licorne qui a attiré les faveurs des plus grandes institutions d'investissement du monde ? En observant leurs premiers supports promotionnels, nous pouvons constater que SambaNova a choisi une voie de développement différente de celle du géant de l'IA NVIDIA
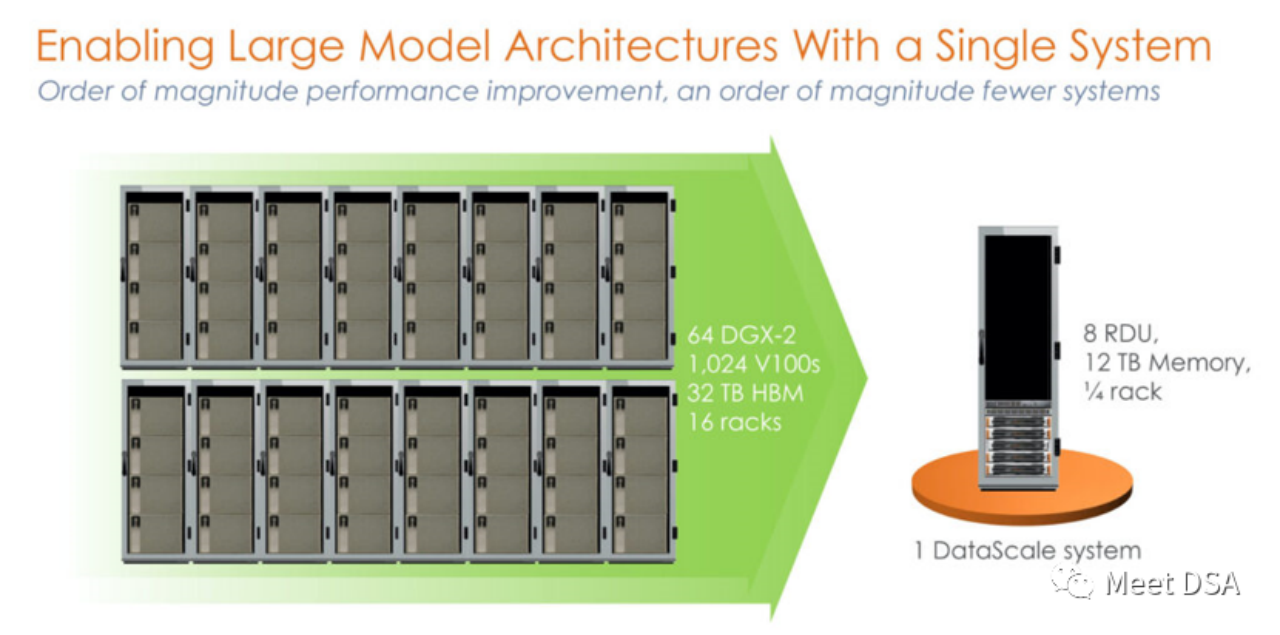
N'est-ce pas un peu choquant ? Un cluster 1024 V100 construit avec une puissance sans précédent sur la plateforme NVIDIA est en réalité équivalent à une seule machine de SambaNova ? ! Il s'agit du produit de première génération, une machine autonome à 8 cartes basée sur SN10 RDU.
Certaines personnes diront peut-être que cette comparaison est injuste. NVIDIA n'a-t-il pas le DGX A100 ? Peut-être que SambaNova lui-même s'en est rendu compte, et le produit SN30 de deuxième génération a été remplacé par ceci :

Le DGX A100 a un ordinateur ? puissance de 5 pétaFLOPS, le DataScale de deuxième génération de SambaNova dispose également d'une puissance de calcul de 5 pétaFLOPS. Comparaison de la mémoire de 320 Go HBM contre 8 To DDR4 (l'éditeur suppose qu'il a peut-être mal écrit l'article, il devrait être de 3 To * 8).
La puce de deuxième génération est en fait la version Die-to-Die du SN10 RDU. Les indicateurs architecturaux du SN10 RDU sont : 320TFLOPS@BF16, 320 M de SRAM, 1,5 T DDR4. Le SN30 RDU est doublé sur cette base, comme décrit ci-dessous :
« Cette puce avait 640 unités de calcul de modèle avec plus de 320 téraflops de calcul avec une précision en virgule flottante BF16 et avait également 640 unités de mémoire de modèle avec 320 Mo de SRAM sur puce. et 150 To/s de bande passante mémoire sur puce. Chaque processeur SN10 était également capable d'adresser 1,5 To de mémoire auxiliaire DDR4. " " Avec le Cardinal SN30 RDU, la capacité du RDU est doublée, et la raison pour laquelle elle est doublée est la suivante : que SambaNova a conçu son architecture pour utiliser le packaging multi-die dès le départ, et dans ce cas, SambaNova double la capacité de ses machines DataScale en intégrant deux nouveaux RDU – ce que nous supposons sont deux SN10 peaufinés avec des changements de microarchitecture mieux prendre en charge les grands modèles de base – dans un complexe unique appelé SN30. Chaque socket d'un système DataScale a désormais deux fois la capacité de calcul, deux fois la capacité de mémoire locale et deux fois la bande passante mémoire des premières générations de machines. points extraits
:La grande bande passante et la grande capacité ne peuvent être choisies que parmi deux options. NVIDIA a choisi le HBM à grande bande passante, tandis que SambaNova a choisi la DDR4 à grande capacité. En termes de résultats de performance, SambaNova gagne. Si vous passez au DGX H100, même si vous passez à des technologies de basse précision telles que le FP8, vous ne pouvez que réduire l'écart.
« Et même si le DGX-H100 offre 3 fois plus de performances en calcul à virgule flottante 16 bits que le DGX-A100, il ne comblera pas l'écart avec le système SambaNova. Cependant, avec des données FP8 de moindre précision, Nvidia pourrait. être capable de combler l'écart de performances ; on ne sait pas exactement dans quelle mesure la précision sera sacrifiée en passant à des données et à un traitement de moindre précision. "Si quelqu'un peut obtenir un tel effet, ne serait-ce pas une solution parfaite pour une grande puce ? Et il peut aussi affronter directement la concurrence de NVIDIA ! (Peut-être direz-vous que le processeur Grace peut également être connecté au LPDDR, ce qui est utile pour augmenter la capacité. D'un autre côté, comment SambaNova voit-il cette question : Grace n'est qu'un grand contrôleur de mémoire, mais il ne peut apporter que 512 Go. à Hopper. de DRAM, et un SN30 a 3 To de DRAM Nous avions l'habitude de plaisanter en disant que le processeur Arm "Grace" de Nvidia n'était qu'un contrôleur de mémoire surfait pour le GPU Hopper, et dans de nombreux cas, ce n'était en réalité qu'un contrôleur de mémoire. Et le GPU Hopper de chaque package de super puces Grace-Hopper ne dispose que d'un maximum de 512 Go de mémoire, c'est encore bien moins que les 3 To de mémoire fournis par SambaNovaL'histoire nous dit que peu importe la prospérité de l'empire, il est important. Il faudra peut-être aussi faire attention à cette fissure discrète
.
Xia He, le maître de Huawei, a récemment émis l'hypothèse qu'une faiblesse de l'empire NVIDIA pourrait résider dans le coût par Go du point de vue du coût. Il a suggéré un empilement fou de mémoire DDR bon marché pour des entrées/sorties internes à grande échelle. peut avoir un impact révolutionnaire sur NVIDIA
(Extension:https://www.php.cn/link/617974172720b96de92525536de581fa)
Et un autre maître Zhihu qui étudie le DSA, Mackler, a donné son avis, du point de vue de $/GBps (mouvement de données), HBM est plus rentable car bien que LLM ait une demande relativement importante en capacité de mémoire, il a également une énorme demande en bande passante mémoire. La formation nécessite un grand nombre de paramètres qui doivent être échangés dans la DRAM. .
(Extension : https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc)
À en juger par l'exemple d'architecture de SambaNova, une DDR de grande capacité et bon marché peut résoudre le problème du LLM, ce qui confirme que Le jugement de Xia Core ! Mais selon le point de vue de Mackler, la demande de bande passante énorme pour la migration des données est également un problème. Alors, comment SambaNova le résout-il ?
Vous devez mieux comprendre les caractéristiques de l'architecture RDU. En fait, c'est facile à comprendre :
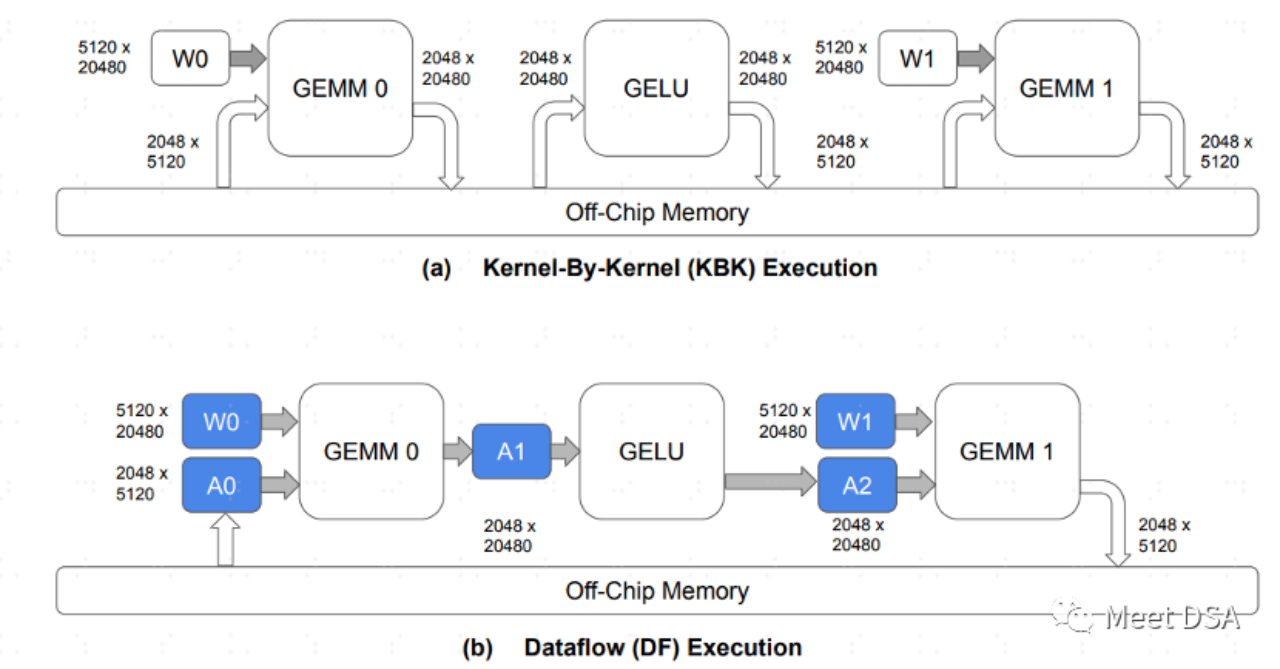
A est le paradigme de l'échange de données dans l'architecture GPU traditionnelle. Chaque opérateur doit se mettre à l'arrêt. puce DRAM pour échanger des données Cet échange aller-retour devrait être plus facile à comprendre qu'il occupe une grande quantité de bande passante DDR. B est ce que l'architecture de SambaNova peut réaliser. Pendant le processus de calcul du modèle, une grande partie du mouvement des données est conservée sur la puce, et il n'est pas nécessaire de faire des allers-retours vers la DRAM pour les échanger.
Par conséquent, Si vous pouvez obtenir l'effet comme B, le problème du choix entre une grande bande passante et une grande capacité, vous pouvez choisir en toute sécurité une grande capacité. C'est ce que dit le passage suivant :
« La question que nous nous posons est la suivante : qu'est-ce qui est le plus important dans une architecture de mémoire hybride prenant en charge les modèles de base, la capacité de mémoire ou la bande passante mémoire ? Vous ne pouvez pas avoir les deux sur la base d'une seule technologie de mémoire ? n'importe quelle architecture, et même lorsque vous avez un mélange de mémoires rapides et maigres et lentes et grasses, où Nvidia et SambaNova tracent des lignes différentes. »
Face au puissant NVIDIA, nous ne sommes pas sans espoir ! Cependant, suivre la stratégie GPGPU de NVIDIA n'est peut-être pas réalisable. Il semble que la bonne idée pour les grosses puces soit d'utiliser une DRAM moins coûteuse. Avec les mêmes spécifications de puissance de calcul, les performances peuvent atteindre plus de 6 fois celles de NVIDIA !
Comment l'architecture RDU/DataFlow de SambaNova obtient-elle l'effet B ? Ou existe-t-il d'autres moyens d'obtenir un effet similaire à B ? Nous le partagerons avec vous la prochaine fois. Amis intéressés, continuez à prêter attention à nos mises à jour
Matériel de lecture étendu :
[1]https://sambanova.ai/blog/a-new- état de l'art-in-nlp-beyond-gpus/
[2]https://www.nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase -ai-foundation-models/
[3]https://hc33.hotchips.org/assets/program/conference/day2/SambaNova%20HotChips%202021%20Aug%2023%20v1.pdf
[ 4] 《Formation efficace des modèles de grande langue avec la rareté et le flux de données》
[5] https://www.php.cn/link/617974172720b96de92525536de581fa
Le contenu qui doit être réécrit est: [6] https https://www.php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La Xiamen Metaverse Industry Expo s'ouvre pour présenter les réalisations innovantes de Metaverse
- En prenant l'« Exhibition Express », le parc industriel d'intelligence artificielle de Qingdao explore de nouvelles façons d'attirer les investissements
- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- La demande de puissance de calcul de l'IA a fortement augmenté et Shanghai Lingang construira une industrie de puissance de calcul à l'échelle de plusieurs dizaines de milliards.
- Exploration de l'application du langage Go dans l'industrie automobile intelligente