
Maison >Périphériques technologiques >IA >Avec 100 000 dollars américains + 26 jours, un LLM low-cost avec 100 milliards de paramètres est né
Avec 100 000 dollars américains + 26 jours, un LLM low-cost avec 100 milliards de paramètres est né

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-20 15:49:01868parcourir

Papier : https://arxiv.org/pdf/2309.03852.pdf
-
Le contenu qui doit être réécrit est : Lien du modèle : https://huggingface.co/CofeAI/FLM- 101B
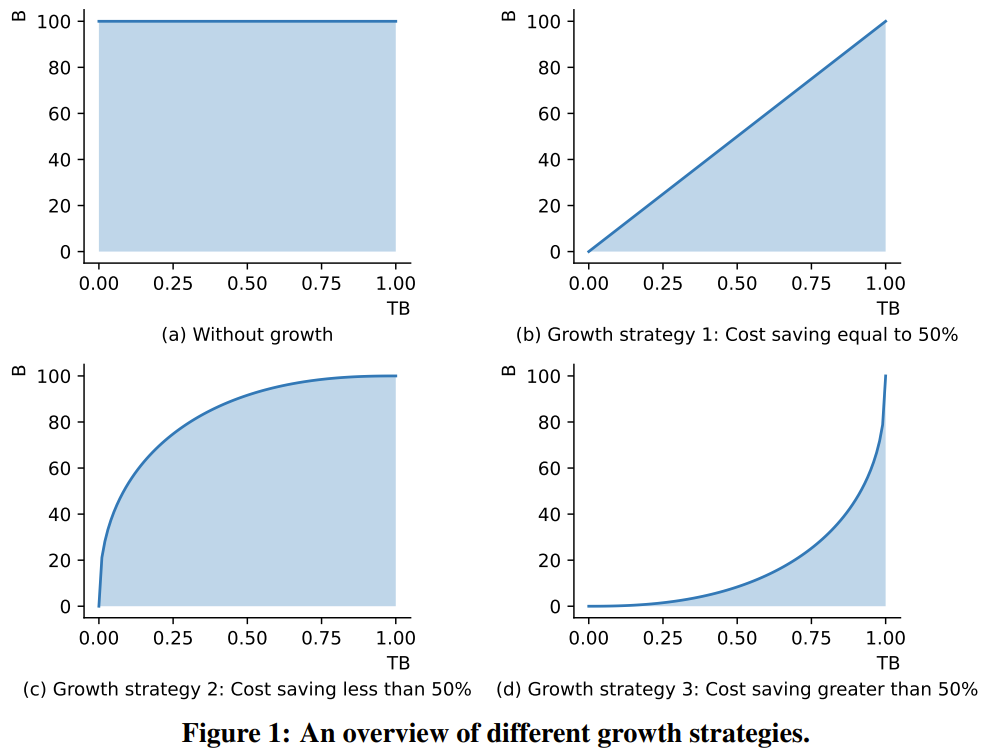
Le langage est de nature symbolique. Certaines études ont utilisé des symboles plutôt que des étiquettes de catégories pour évaluer le niveau d'intelligence des LLM. De même, l'équipe a utilisé une approche de cartographie symbolique pour tester la capacité du LLM à généraliser à des contextes invisibles.
Une capacité importante de l'intelligence humaine est de comprendre des règles données et de prendre les mesures correspondantes. Cette méthode de test a été largement utilisée à différents niveaux de tests. Par conséquent, la compréhension des règles devient ici le deuxième test.
Contenu réécrit : L'exploration de modèles est une partie importante de l'intelligence, qui implique l'induction et la déduction. Dans l’histoire du développement scientifique, cette méthode joue un rôle crucial. De plus, les questions des tests dans divers concours nécessitent souvent cette capacité à répondre. Pour ces raisons, nous avons choisi le pattern mining comme troisième indicateur d'évaluation
Le dernier et très important indicateur est la capacité anti-interférence, qui est également l'une des capacités fondamentales du renseignement. Des études ont montré que le langage et les images sont facilement perturbés par le bruit. Dans cette optique, l’équipe a utilisé l’immunité aux interférences comme mesure d’évaluation finale.
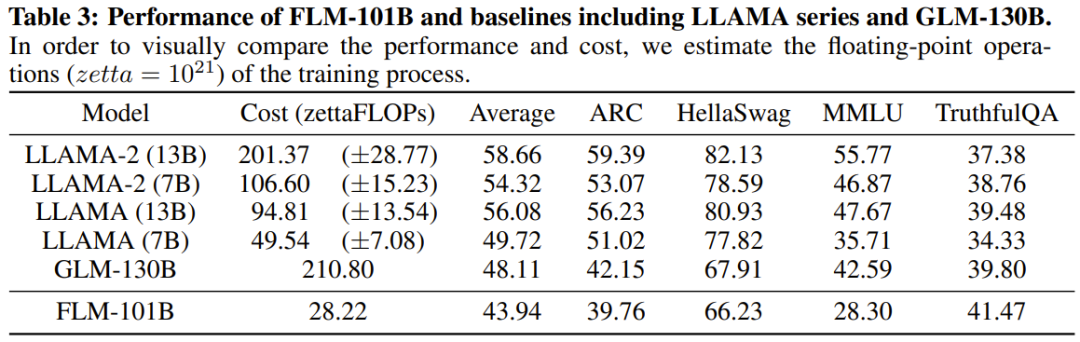
Le chercheur a déclaré qu'il s'agit d'une tentative de recherche LLM visant à entraîner plus de 100 milliards de paramètres à partir de zéro en utilisant une stratégie de croissance. Dans le même temps, il s'agit également du modèle à 100 milliards de paramètres le moins coûteux actuellement, ne coûtant que 100 000 dollars américains
En améliorant les objectifs de formation FreeLM, les méthodes potentielles de recherche d'hyperparamètres et la croissance préservant les fonctions, cette recherche résout le problème d'instabilité. Les chercheurs pensent que cette méthode peut également aider la communauté de recherche scientifique au sens large.
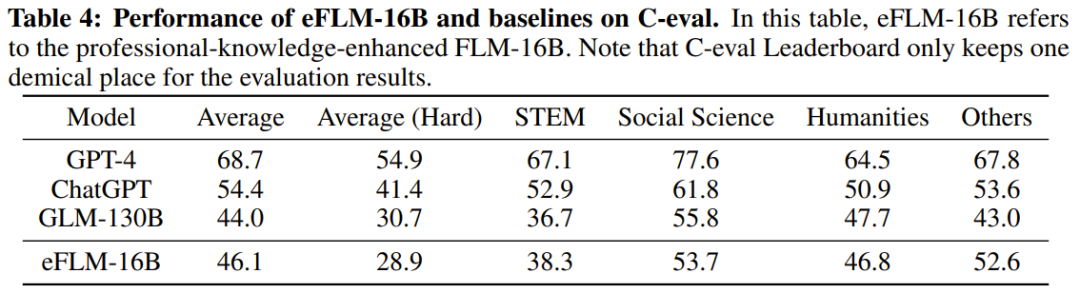
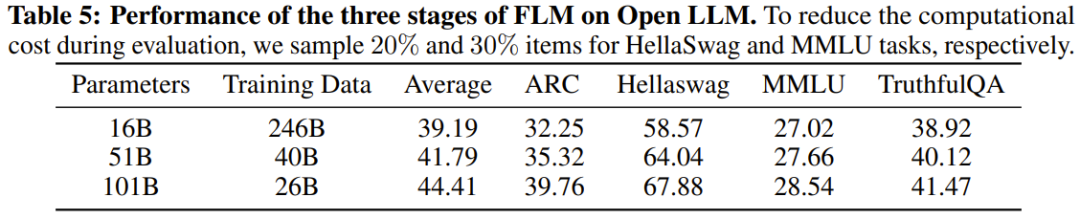
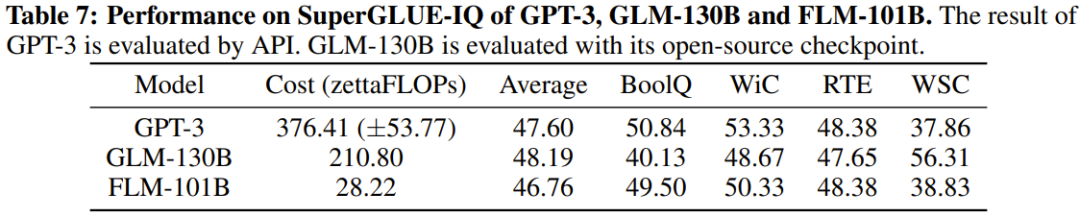
Les chercheurs ont également effectué des comparaisons expérimentales du nouveau modèle avec des modèles auparavant puissants, notamment en utilisant des références axées sur les connaissances et une nouvelle référence d'évaluation systématique du QI. Les résultats expérimentaux montrent que le modèle FLM-101B est compétitif et robuste
L'équipe publiera des modèles de points de contrôle, du code, des outils associés, etc. pour promouvoir la recherche et le développement de LLM bilingues en chinois et en anglais avec une échelle de 100 milliards de paramètres.
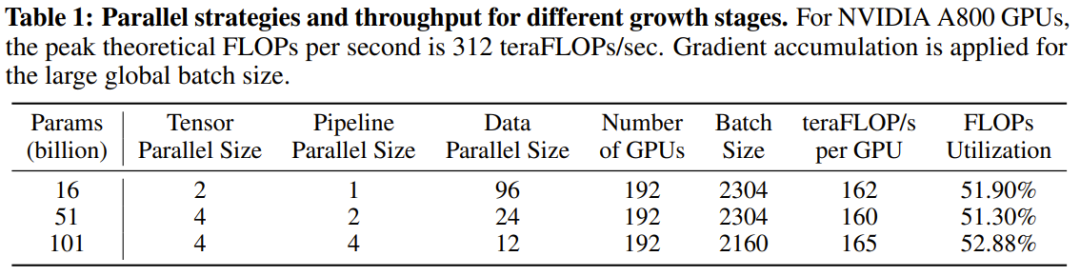
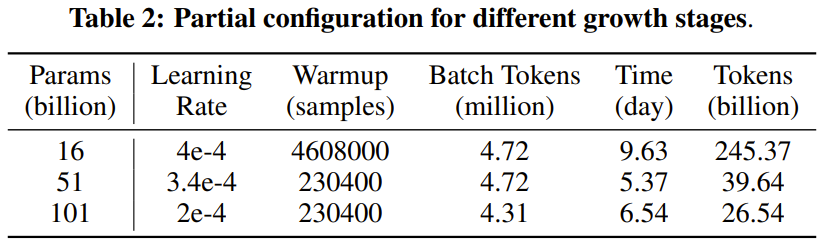
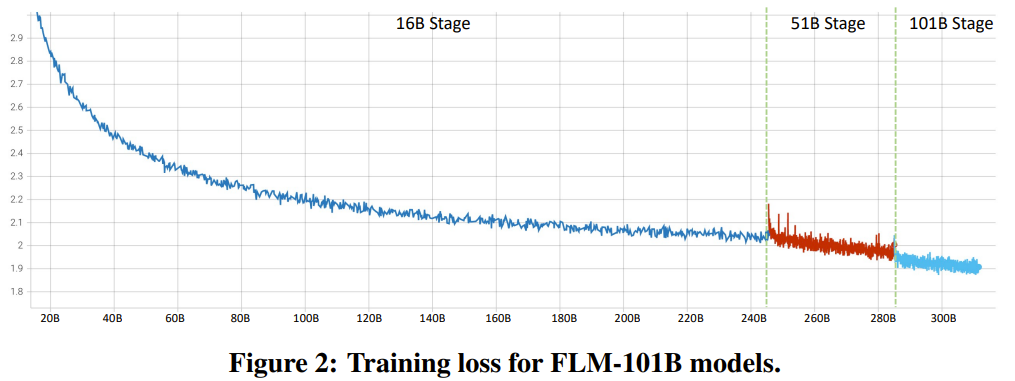


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Introduction détaillée à la théorie MySQL et aux connaissances de base
- L'Université de Pékin et Alibaba créent un laboratoire commun pour se concentrer sur la théorie de l'intelligence artificielle et la recherche sur les algorithmes innovants
- Découverte de trois modèles Python majeurs et des dix principaux exemples d'algorithmes couramment utilisés