
Maison >Périphériques technologiques >IA >Pas besoin de 4 H100 ! 34 milliards de paramètres Code Llama peut être exécuté sur Mac, 20 jetons par seconde, le meilleur pour la génération de code
Pas besoin de 4 H100 ! 34 milliards de paramètres Code Llama peut être exécuté sur Mac, 20 jetons par seconde, le meilleur pour la génération de code

- PHPzavant
- 2023-09-19 13:05:01927parcourir
Un développeur de la communauté open source, Georgi Gerganov, a découvert qu'il pouvait exécuter le modèle 34B Code Llama avec une précision F16 totale sur M2 Ultra, et que la vitesse d'inférence dépassait 20 jetons/s.
M2 Ultra a une bande passante de 800 Go/s, ce que d'autres ont généralement besoin d'utiliser 4 GPU haut de gamme pour atteindre
Et la vraie réponse derrière cela est : l'échantillonnage spéculatif).
La découverte de George a immédiatement déclenché une discussion parmi les grands noms de l'industrie de l'intelligence artificielle
Karpathy a retweeté et commenté : "L'exécution spéculative de LLM est une excellente optimisation du temps d'inférence."

"L'échantillonnage spéculatif" accélère l'inférence
Dans cet exemple, Georgi a utilisé le modèle de projet quantique Q4 7B (c'est-à-dire Code Llama 7B) pour effectuer un décodage spéculatif, puis a utilisé le Code Llama34B sur M2 Ultra générer.
Pour faire simple, utilisez un « petit modèle » pour réaliser un brouillon, puis utilisez le « grand modèle » pour vérifier et apporter des corrections afin d'accélérer l'ensemble du processus.

Adresse GitHub : https://twitter.com/ggerganov/status/1697262700165013689
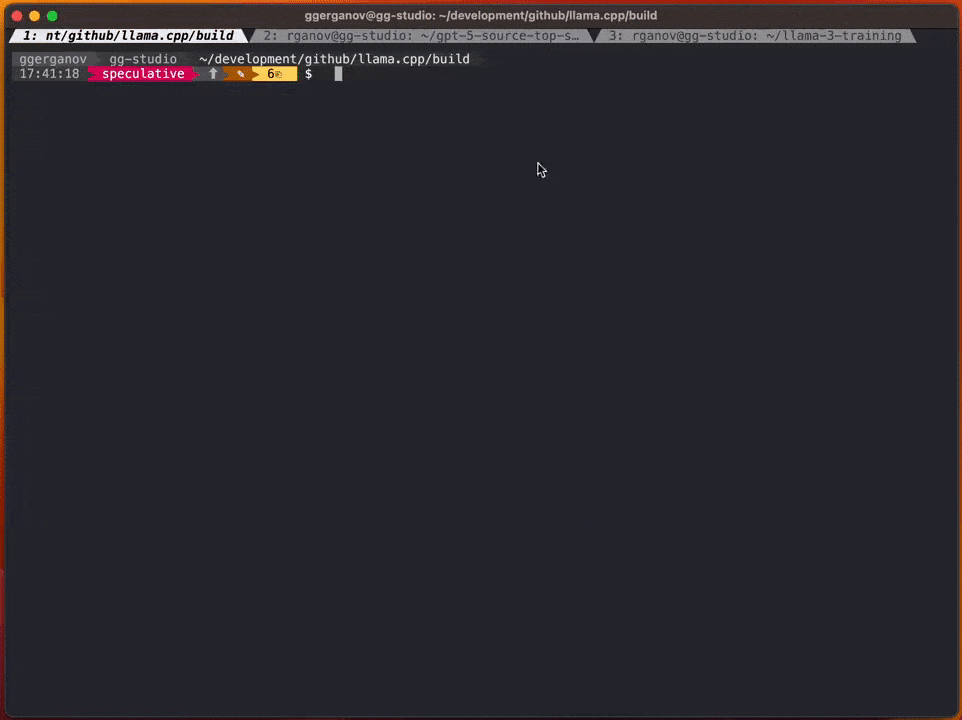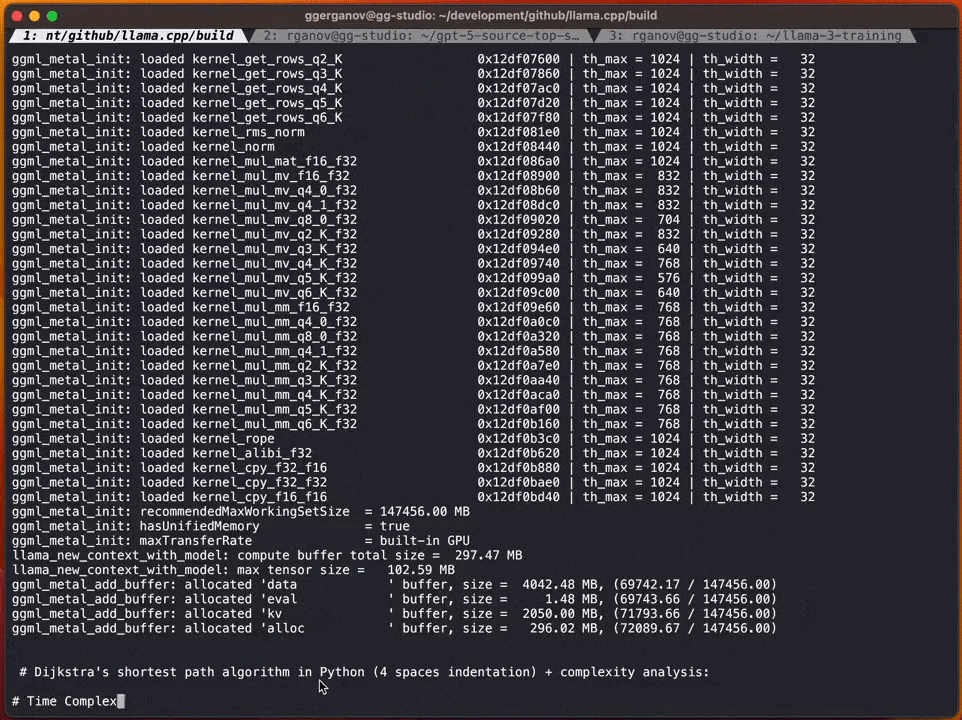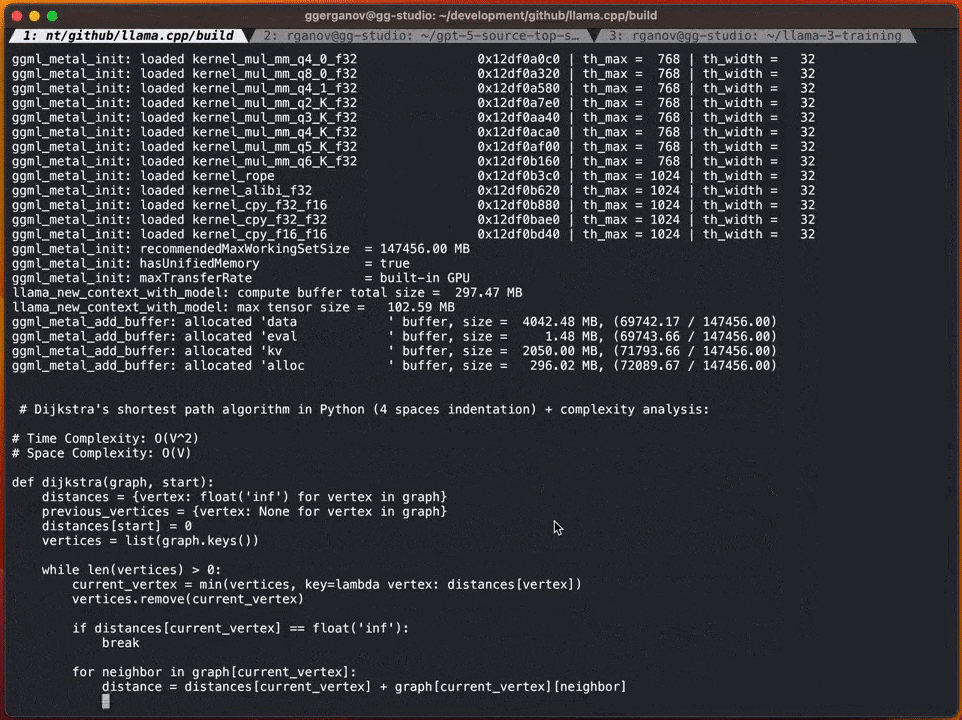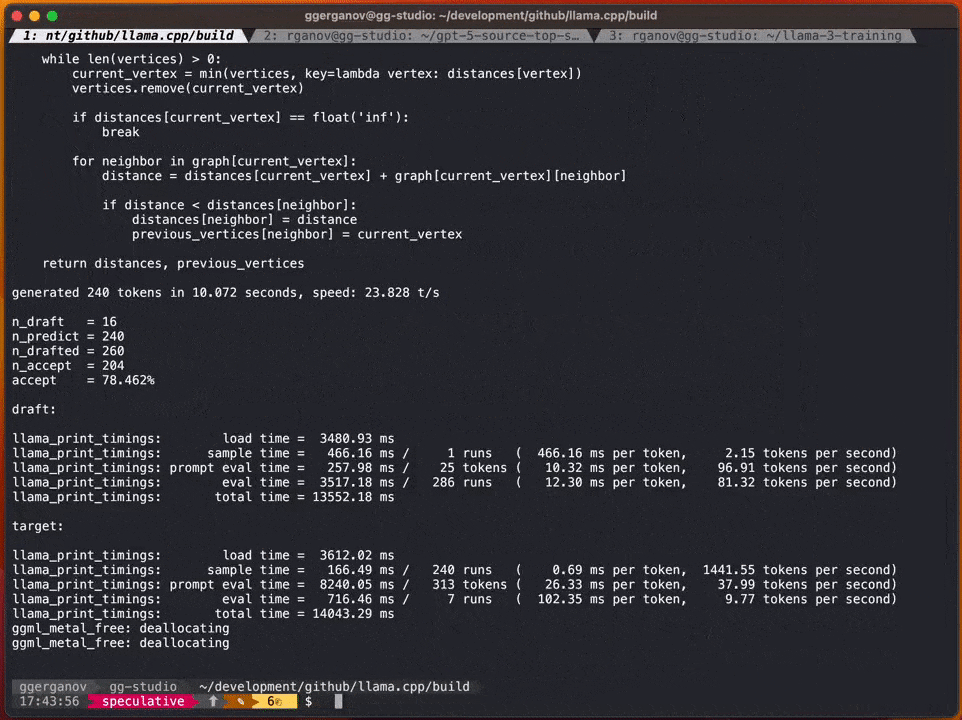
Selon Georgi, les vitesses de ces modèles sont les suivantes
F : 16 34B : env. par seconde 10 jetons
Ce qui doit être réécrit est : Q4 7B : ~80 jetons par seconde
Voici un exemple d'échantillonnage F16 standard sans utiliser d'échantillonnage spéculatif :
Après avoir ajouté la stratégie d'échantillonnage spéculatif, la vitesse peut atteindre environ 20 marks par seconde
Selon Georgi, la vitesse de génération de contenu peut varier. Cependant, cette approche semble être très efficace en termes de génération de code, car la plupart du vocabulaire peut être correctement deviné par le projet de modèle
Les cas d'utilisation utilisant "l'échantillonnage grammatical" sont également susceptibles d'en bénéficier grandement

Spéculation Comment l'échantillonnage permet-il une inférence rapide ?
Karpathy a fait une explication basée sur trois études précédentes réalisées par Google Brain, UC Berkeley et DeepMind.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2211.17192.pdf

Adresse papier : https://arxiv.org/pdf/ 1811.03115.pdf

Adresse papier : https://arxiv.org/pdf/2302.01318.pdf
Cela dépend de l'observation peu intuitive suivante :
Obligatoire pour envoyer un LLM sur un seul entrée jeton Le temps est le même que le temps nécessaire pour transférer par lots LLM sur K jetons d'entrée (K est plus grand que vous ne le pensez).
Ce fait peu intuitif est dû au fait que l'échantillonnage est sévèrement limité par la mémoire et que la plupart du "travail" n'est pas calculé, mais les poids du Transformer sont lus de la VRAM dans le cache intégré pour le traitement.

Pour accomplir la tâche de lecture de tous les poids, il est préférable de les appliquer au vecteur d'entrée de l'ensemble du lot
La raison pour laquelle nous ne pouvons pas naïvement exploiter ce fait et échantillonner K jetons à la fois est que tous les N jetons Tout dépend du jeton que nous avons échantillonné à l'étape N-1. Il s'agit d'une dépendance en série, donc l'implémentation de base se déroule une par une de gauche à droite.
Maintenant, une idée intelligente consiste à utiliser un modèle de brouillon petit et bon marché pour générer d'abord une séquence candidate composée de K marqueurs - un "brouillon". Nous introduisons ensuite toutes ces informations par lots dans le grand modèle
Selon la méthode ci-dessus, cela est presque aussi rapide que de saisir un seul jeton.
Ensuite, nous examinons le modèle de gauche à droite et les logits prédits par l'échantillon de jeton. Tout échantillon correspondant au brouillon nous permet de passer immédiatement au jeton suivant.
En cas de désaccord, nous abandonnons le modèle préliminaire et prenons en charge le coût d'un travail ponctuel (échantillonnage du modèle préliminaire et transmission des jetons suivants)
Cela fonctionne bien dans la pratique. La raison en est que les brouillons de jetons seront acceptés dans la plupart des cas parce qu'il s'agit de simples jetons, de sorte que même les modèles de brouillon plus petits peuvent les accepter.
Lorsque ces jetons simples seront acceptés, nous sauterons ces parties. Les jetons de difficulté avec lesquels le grand modèle n'est pas d'accord « retomberont » à la vitesse d'origine, mais seront en réalité plus lents en raison du travail supplémentaire.
Donc, en résumé : cette astuce étrange fonctionne parce que LLM est limité en mémoire lors de l'inférence. Dans le cas de « taille de lot 1 », une seule séquence d'intérêt est échantillonnée, ce qui est le cas pour la plupart des cas d'utilisation de « LLM local ». De plus, la plupart des jetons sont « simples ».
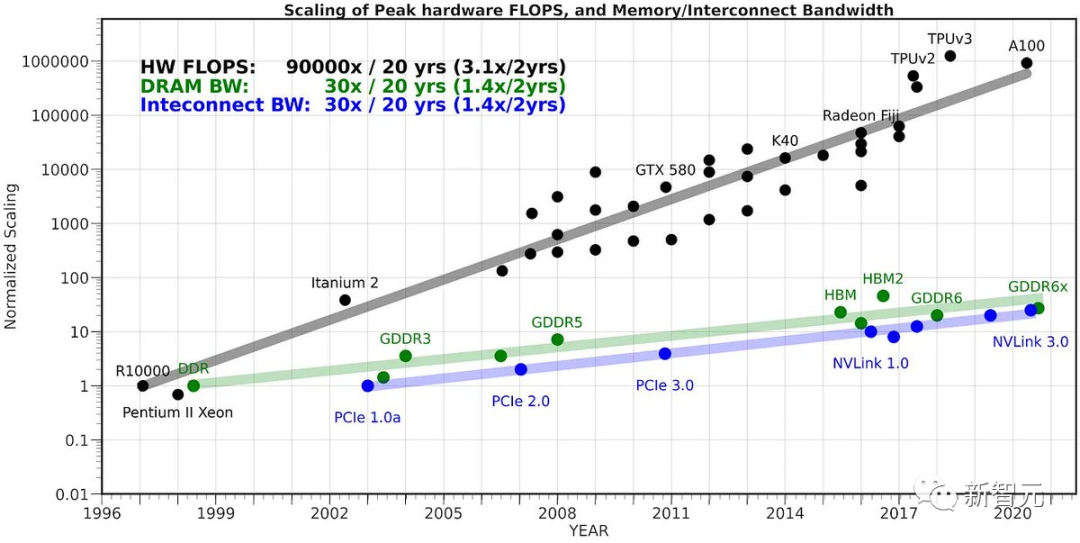
Le co-fondateur de HuggingFace a déclaré qu'il y a un an et demi, le modèle de 34 milliards de paramètres semblait très vaste et ingérable en dehors du centre de données. Désormais, il peut être facilement géré avec un simple ordinateur portable

Le LLM d'aujourd'hui n'est pas un point unique de percée, mais un système qui nécessite plusieurs composants importants pour fonctionner ensemble efficacement. Le décodage spéculatif est un excellent exemple qui nous aide à penser du point de vue des systèmes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!