
Maison >Périphériques technologiques >IA >SurroundOcc : grille d'occupation Surround 3D, nouveau SOTA !
SurroundOcc : grille d'occupation Surround 3D, nouveau SOTA !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-18 20:25:011718parcourir
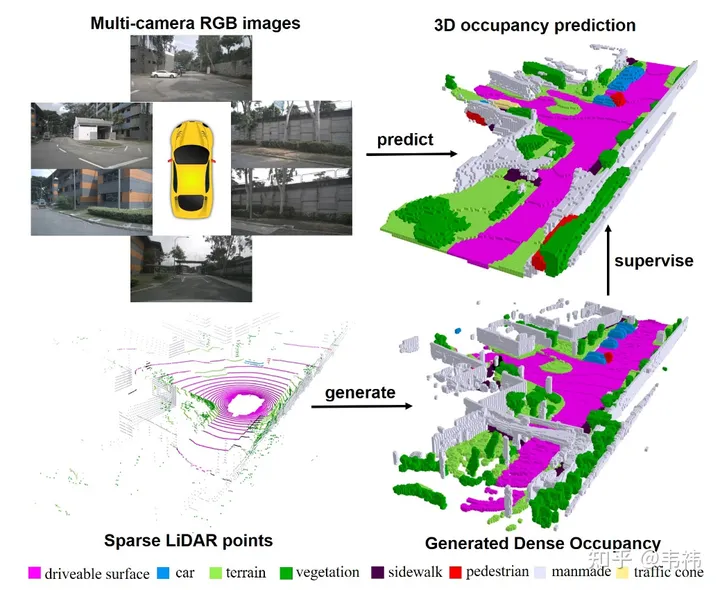
Dans ce travail, nous avons construit un ensemble de données raster d'occupation dense à partir de nuages de points multi-trames et conçu un réseau raster d'occupation tridimensionnel basé sur la structure Unet 2D-3D basée sur un transformateur. Nous sommes honorés que notre article ait été inclus dans ICCV 2023. Le code du projet est désormais open source et tout le monde est invité à l'essayer.

arXiv : https://arxiv.org/pdf/2303.09551.pdf
Code : https://github.com/weiyithu/SurroundOcc
Lien de la page d'accueil : https://weiyithu.github.io/ SurroundOcc/
Je cherchais un travail comme un fou ces derniers temps, et je n'ai pas eu le temps d'écrire. Il m'est arrivé de soumettre récemment un document prêt à photographier, j'ai pensé qu'il serait préférable d'écrire un. Résumé de Zhihu. D’ailleurs, l’introduction de l’article est déjà bien rédigée par différents comptes publics, et grâce à leur publicité, vous pouvez directement faire référence au Cœur de la Conduite Autonome : nuScenes SOTA ! SurroundOcc : Réseau de prédiction d'occupation 3D purement visuel pour la conduite autonome (Tsinghua & Tianda). En général, la contribution est divisée en deux parties. L'une explique comment utiliser des nuages de points lidar multi-trames pour créer un ensemble de données d'occupation dense, et l'autre explique comment concevoir un réseau pour la prévision d'occupation. En fait, le contenu des deux parties est relativement simple et facile à comprendre. Si vous ne comprenez rien, vous pouvez toujours me le demander. Donc, dans cet article, je veux parler d'autre chose que de la thèse. L'une est de savoir comment améliorer la solution actuelle pour la rendre plus facile à déployer, et l'autre est l'orientation future du développement.
Déploiement
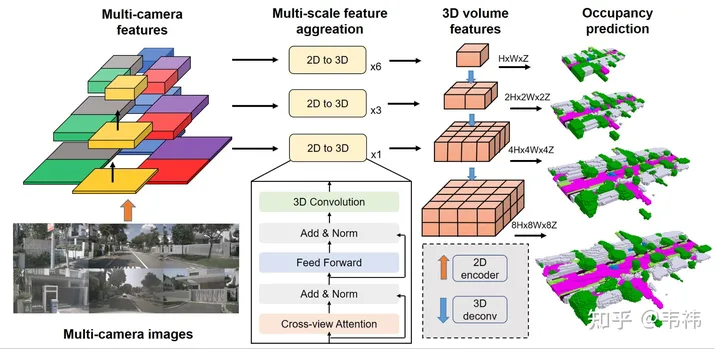
La facilité de déploiement d'un réseau dépend principalement de l'existence ou non d'opérateurs difficiles à mettre en œuvre du côté de la carte. Les deux opérateurs les plus difficiles de la méthode SurroundOcc sont le transformateur. couche et convolution 3D.
La fonction principale du transformateur est de convertir des fonctionnalités 2D en espace 3D. En fait, cette partie peut également être implémentée en utilisant LSS, Homography ou même mlp, cette partie du réseau peut donc être modifiée en fonction de la solution implémentée. Mais pour autant que je sache, la solution du transformateur n'est pas sensible à l'étalonnage et offre de meilleures performances parmi plusieurs solutions. Il est recommandé à ceux qui ont la capacité de mettre en œuvre le déploiement du transformateur d'utiliser la solution d'origine.
Pour la convolution 3D, vous pouvez la remplacer par une convolution 2D. Ici, vous devez remodeler la caractéristique 3D d'origine de (C, H, W, Z) en caractéristique 2D de (C* Z, H, W), puis Vous pouvez utiliser la convolution 2D pour l'extraction de caractéristiques. Dans l'étape finale de prédiction d'occupation, remodelez-la en (C, H, W, Z) et effectuez la supervision. D'un autre côté, sauter la connexion consomme plus de mémoire vidéo en raison de sa résolution plus grande. Lors du déploiement, il peut être supprimé et seule la couche de résolution minimale sera laissée. Notre expérience a révélé que ces deux opérations de convolution 3D auront des points de chute sur les nuscènes, mais l'échelle de l'ensemble de données de l'industrie est beaucoup plus grande que celle des nuscènes, et parfois certaines conclusions changeront, et les points de chute devraient être inférieurs, voire nuls.
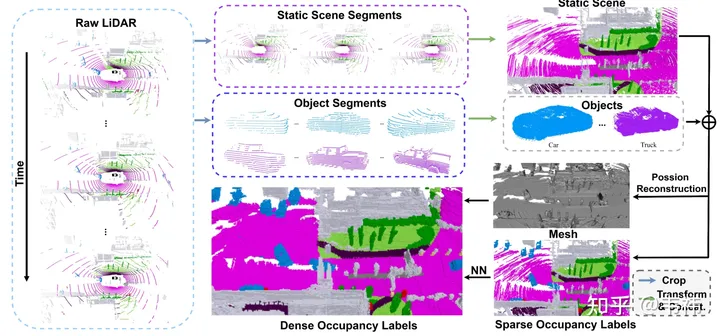
En termes de construction d'ensembles de données, l'étape la plus longue est la reconstruction de Poisson. Nous utilisons l'ensemble de données nuscenes, qui utilise un lidar à 32 lignes pour la collecte. Même en utilisant la technologie d’assemblage multi-images, nous avons constaté qu’il existe encore de nombreux trous dans le nuage de points assemblé. Nous avons donc utilisé la reconstruction de Poisson pour combler ces trous. Cependant, de nombreux nuages de points lidar actuellement utilisés dans l’industrie sont relativement denses, comme M1, RS128, etc. Par conséquent, dans ce cas, l'étape de reconstruction de Poisson peut être omise pour accélérer la construction de l'ensemble de données
D'autre part, SurroundOcc utilise le cadre de détection de cible tridimensionnel annoté en nuscènes pour séparer les scènes statiques et les objets dynamiques. Cependant, dans l'application réelle, l'autolabel, qui est un grand modèle tridimensionnel de détection et de suivi de cible, peut être utilisé pour obtenir le cadre de détection de chaque objet dans la séquence entière. Par rapport aux étiquettes annotées manuellement, les résultats produits en utilisant de grands modèles comporteront certainement des erreurs. La manifestation la plus directe est le phénomène d'image fantôme après l'assemblage de plusieurs images d'objets. Mais en fait, l'occupation n'a pas d'exigences aussi élevées en matière de forme des objets. Tant que la position du cadre de détection est relativement précise, elle peut répondre aux exigences.
Orientations futures
La méthode actuelle repose toujours sur le lidar pour fournir des signaux de surveillance d'occupation, mais de nombreuses voitures, en particulier certaines voitures à conduite assistée de bas niveau, ne disposent pas de lidar. Ces voitures peuvent retransmettre une grande quantité de données RVB via. mode ombre. , alors une orientation future est de savoir si nous pouvons utiliser le RVB uniquement pour l'apprentissage auto-supervisé. Une solution naturelle consiste à utiliser NeRF pour la supervision. Plus précisément, la partie dorsale avant reste inchangée pour obtenir une prédiction d'occupation, puis le rendu voxel est utilisé pour obtenir le RVB depuis chaque perspective de caméra, et la perte se fait avec la vraie valeur RVB. l’ensemble de formation. Créer un signal de supervision. Mais il est dommage que cette méthode simple n'ait pas très bien fonctionné lorsque nous l'avons essayée. La raison possible est que la portée de la scène extérieure est trop large et que le nerf ne pourra peut-être pas la retenir, mais c'est également possible. que nous ne l'avons pas ajusté correctement. Vous pouvez réessayer.
L'autre direction est le timing et le flux d'occupation. En fait, le flux d'occupation est bien plus utile pour les tâches en aval que l'occupation sur une seule image. Pendant l'ICCV, nous n'avons pas eu le temps de compiler l'ensemble des données sur les flux d'occupation, et lorsque nous avons publié le document, nous avons dû comparer de nombreuses références de flux, nous n'avons donc pas travaillé dessus à ce moment-là. Pour les réseaux de chronométrage, vous pouvez vous référer aux solutions de BEVFormer et BEVDet4D, relativement simples et efficaces. La partie difficile reste l'ensemble de données de flux. Les objets généraux peuvent être calculés à l'aide du cadre de séquence de détection de cible tridimensionnelle, mais les objets de forme spéciale tels que les petits sacs en plastique pour animaux peuvent devoir être annotés à l'aide de la méthode de flux de scène.

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle technologie est le rpa
- Que sont les technologies Web frontales ?
- Que savez-vous de la technologie de navigation inertielle pour la conduite autonome ?
- Cet article vous donnera une compréhension facile à comprendre de la conduite autonome
- Un article pour comprendre la perception lidar et fusion visuelle de la conduite autonome