
Maison >Périphériques technologiques >IA >Microsoft propose une technologie brevetée pour prédire la posture d'objets articulés pour la capture de la posture corporelle AR/VR
Microsoft propose une technologie brevetée pour prédire la posture d'objets articulés pour la capture de la posture corporelle AR/VR

- 王林avant
- 2023-09-18 19:37:01991parcourir
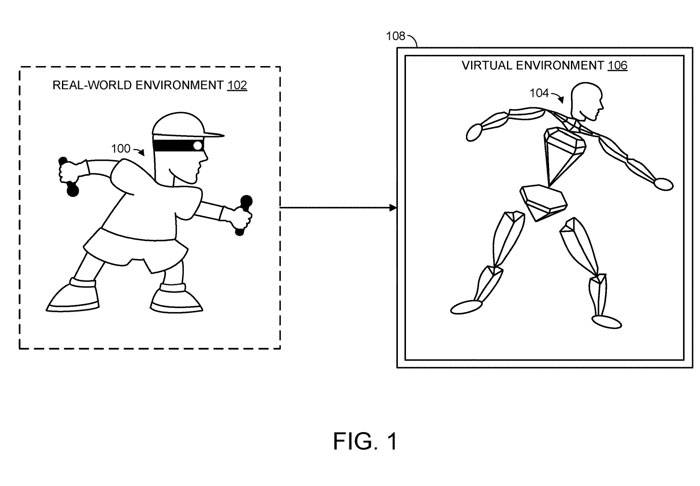
(Nweon, 18 septembre 2023) Afin de représenter avec précision la posture réelle d'un utilisateur humain, des informations relativement détaillées sur la position et l'orientation des parties du corps de l'utilisateur sont généralement nécessaires, mais ces informations ne sont pas toujours disponibles. Par exemple, lors de l'utilisation d'un casque pour offrir une expérience de réalité virtuelle, le système peut uniquement être en mesure d'obtenir des informations spatiales liées à la tête et aux mains de l'utilisateur. Cependant, dans la plupart des cas, cela ne suffit pas pour reproduire fidèlement la posture réelle d'un utilisateur humain
Ainsi, dans la demande de brevet intitulée « Prédiction de pose pour objet articulé », Microsoft a proposé une technologie pour prédire la pose d'objets articulés. En particulier, le modèle d'apprentissage automatique reçoit les informations spatiales de n articulations différentes de l'objet articulé, n articulations étant plus petites que toutes les articulations de l'objet articulé.
Dans le cas d'un utilisateur humain, les n articulations peuvent inclure l'articulation de la tête de l'utilisateur humain et/ou une ou deux articulations du poignet, qui sont associées à des informations spatiales détaillant les paramètres de la tête et/ou des mains de l'utilisateur
Le modèle d'apprentissage automatique a été entraîné pour recevoir des informations spatiales d'entrée pour n+m articulations d'un objet articulé, où m est supérieur ou égal à 1. Par exemple, lors de la formation initiale, un modèle d’apprentissage automatique reçoit des données d’entrée correspondant à presque toutes les articulations d’un objet articulé. Les n+m articulations peuvent inclure chaque articulation de l'objet articulé.
Dans d'autres exemples, il peut y avoir n+m articulations là où il y en a moins que toutes les articulations d'un objet articulé. Pendant le processus de formation, les données entrées dans le modèle d'apprentissage automatique peuvent être progressivement masquées. Vous pouvez remplacer les données d'entrée correspondantes d'un nœud spécifique dans m nœuds par une valeur prédéfinie, ou simplement l'omettre
En d'autres termes, un modèle d'apprentissage automatique est entraîné pour prédire avec précision la pose d'un objet articulé sur la base de moins d'informations sur la position/orientation des différentes parties mobiles de l'objet articulé.
Grâce à cette approche, les modèles d'apprentissage automatique sont capables de prédire avec précision la pose des objets articulés au moment de l'exécution avec seulement des données d'entrée clairsemées. Microsoft souligne que cette technologie peut reproduire avec précision la pose réelle d'objets articulés pour les utilisateurs humains sans nécessiter beaucoup d'informations sur l'orientation de chaque articulation
En d’autres termes, les inventions peuvent offrir des avantages technologiques qui améliorent l’interaction homme-machine en reproduisant plus précisément les gestes réels des utilisateurs humains. Ces avantages techniques incluent l'amélioration de l'immersion des expériences de réalité virtuelle et l'amélioration de la précision des systèmes de reconnaissance gestuelle
De plus, la technologie décrite peut réduire la consommation de ressources informatiques tout en reproduisant avec précision la posture réelle d'un utilisateur humain en réduisant la quantité de données qui doivent être collectées en entrée du processus de prédiction de posture.
L'exemple de méthode 200 montre la figure 2 pour prédire la pose d'un objet articulé
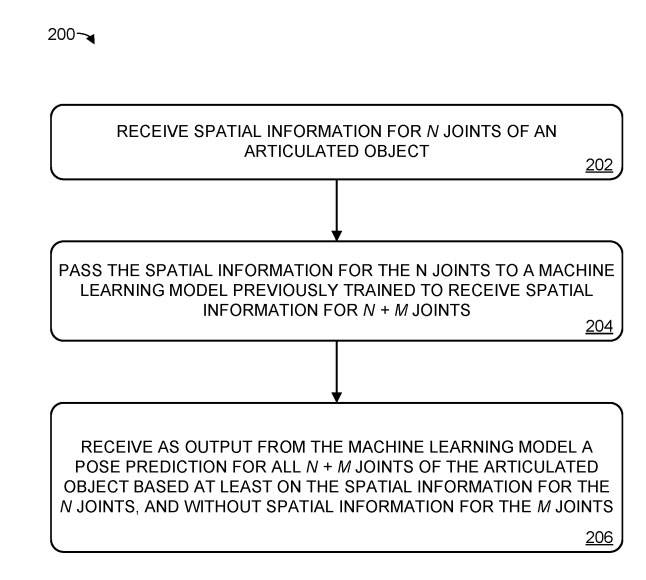
Au point 202, recevez les informations spatiales de n articulations, qui sont utilisées pour les objets articulés. Le système reçoit les informations spatiales de n articulations de l'objet articulé, qui contiennent moins d'articulations que toutes les articulations de l'objet articulé. Représentant l'information spatiale d'une articulation sous la forme de la position et de l'orientation de six degrés de liberté reliant les parties du corps, cela peut être utilisé pour déduire l'état de l'articulation
À titre d'exemple, les n articulations peuvent inclure les articulations de la tête du corps humain, et les informations spatiales des articulations de la tête peuvent décrire les paramètres de la tête humaine en détail. De plus, les n articulations peuvent comprendre une ou plusieurs articulations du poignet du corps humain, et les informations spatiales de la ou des articulations du poignet peuvent décrire en détail les paramètres d'une ou de plusieurs mains du corps humain.
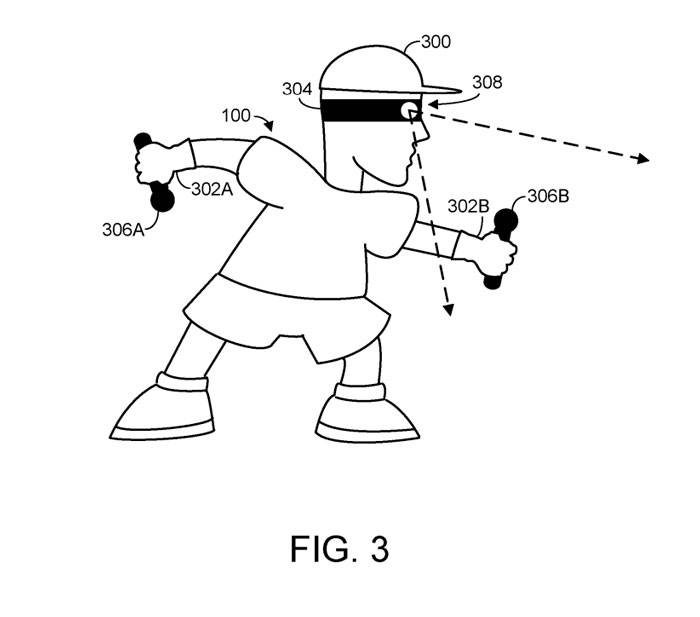
La figure 3 montre les utilisateurs humains. L'utilisateur humain possède une tête 300 et deux mains 302A et 302B. Le système informatique peut recevoir des informations spatiales pour une ou plusieurs articulations d'un utilisateur humain, qui peuvent comprendre des articulations de la tête et/ou du poignet.
Les informations spatiales de n articulations de l'objet articulé peuvent être dérivées des données de positionnement émises par un ou plusieurs capteurs. Des capteurs peuvent être intégrés dans un ou plusieurs dispositifs tenus ou portés par des parties du corps correspondantes d'un utilisateur humain.
Par exemple, les capteurs peuvent inclure une ou plusieurs unités de mesure inertielle intégrées dans un visiocasque et/ou un contrôleur portatif. Comme autre exemple, un capteur peut comprendre une ou plusieurs caméras.
La figure 3 illustre schématiquement les différents types de capteurs où la sortie des capteurs peut inclure ou être utilisée pour dériver des informations spatiales. Plus précisément, un utilisateur humain porte un visiocasque 304 sur sa tête 300.
De plus, l'utilisateur humain tient des capteurs de position 306A et 306B, qui peuvent être configurés pour détecter et signaler le mouvement des mains de l'utilisateur au casque 304 et/ou à un autre système informatique configuré pour recevoir des informations spatiales.
Dans la figure 2, nous revenons à la situation 204. Nous transmettons les informations spatiales de n articulations au modèle d'apprentissage automatique précédemment formé. Ce modèle reçoit en entrée des informations spatiales de n+m articulations, où la valeur de m est supérieure ou égale à 1. En d'autres termes, par rapport au modèle de formation précédent, ce modèle d'apprentissage automatique reçoit moins d'informations sur l'espace articulaire
En 206, recevoir en sortie une prédiction de pose de l'objet articulé issue du modèle d'apprentissage automatique, ladite prédiction étant basée au moins sur les informations spatiales des n articulations et ne contenant pas les informations spatiales de leurs articulations. En d’autres termes, même si les informations spatiales de m articulations ne sont pas fournies, le modèle d’apprentissage automatique peut prédire la posture complète de l’objet commun.
La figure 4 montre un exemple de modèle d'apprentissage automatique 400 pour illustrer ce processus
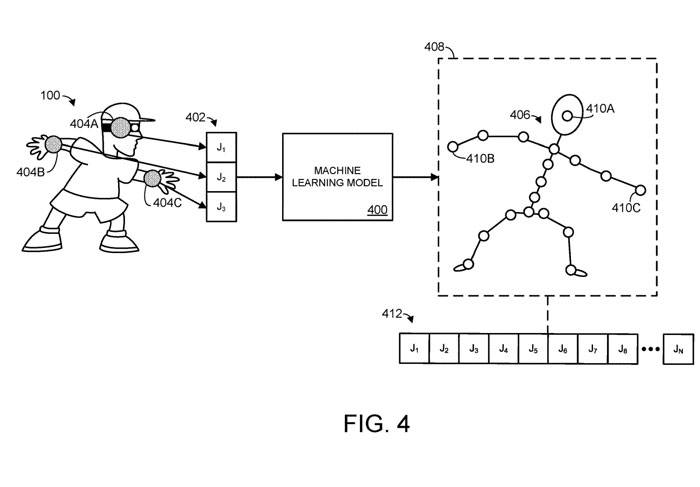
Sur la figure 4, le modèle d'apprentissage automatique reçoit des informations spatiales 402, correspondant à trois articulations différentes J1, J2 et J3. Les informations spatiales pour une articulation peuvent prendre la forme de toute donnée informatique appropriée qui spécifie ou peut être utilisée pour dériver la position et/ou l'orientation de la partie du corps connectée à l'articulation.
Par exemple, les informations spatiales peuvent spécifier directement la position et l'orientation d'une partie du corps, et/ou les informations spatiales peuvent spécifier une ou plusieurs rotations d'une articulation par rapport à un ou plusieurs axes de rotation. Sur la figure 4, les articulations J1, J2, J3 correspondent à l'articulation de la tête 404A d'un utilisateur humain et à deux articulations du poignet 404B/404C, comme le montrent les cercles ombrés superposés sur le corps de l'utilisateur.
Dans cet exemple, les n articulations comprennent trois articulations, correspondant aux articulations de la tête et du poignet du corps humain. Sur la base des informations spatiales d'entrée 402, le modèle d'apprentissage automatique génère une pose prédite 406 de l'objet articulé.
De plus, le modèle d'apprentissage automatique peut générer des informations spatiales prédites correspondant aux articulations représentées par l'articulation virtuelle. Les utilisateurs humains peuvent être représentés par des avatars aux proportions caricaturales ou non humaines. Par exemple, les informations spatiales prédites peuvent correspondre à des articulations représentées par SMPL.
En d'autres termes, les articulations de la représentation virtuelle de la représentation articulée ne doivent pas nécessairement avoir une correspondance 1:1 avec les articulations de l'objet articulé. Par conséquent, les informations spatiales en sortie prédites par le modèle d’apprentissage automatique peuvent concerner des articulations qui ne correspondent pas directement aux n+m articulations de l’objet articulé. Par exemple, une représentation virtuelle peut comporter moins d’articulations vertébrales qu’un objet articulé.
Les modèles d'apprentissage automatique peuvent être formés de n'importe quelle manière appropriée. Dans un mode de réalisation, le modèle d'apprentissage automatique peut avoir été préalablement entraîné à l'aide de données d'entrée d'entraînement avec des étiquettes de vérité terrain pour des objets articulés.
En d'autres termes, le modèle d'apprentissage automatique peut être fourni avec des informations spatiales d'entraînement sur les articulations de l'objet articulé et étiqueté comme étiquettes de vérité terrain spécifiant la pose réelle de l'objet articulé correspondant aux informations spatiales.
Comme mentionné ci-dessus, un modèle d'apprentissage automatique peut être entraîné pour recevoir des informations spatiales de n+m articulations en entrée. Cela implique, lors de la première itération de formation, de fournir au modèle d'apprentissage automatique des données d'entrée de formation pour toutes les n+m articulations. Dans une série ultérieure d'itérations d'entraînement, les données d'entrée d'entraînement de m articulations peuvent être progressivement masquées.
Par exemple, lors de la deuxième itération d'entraînement, la première des m articulations peut être masquée, où les informations spatiales de l'articulation dans l'ensemble de données d'entraînement sont remplacées par une valeur prédéfinie représentant l'articulation masquée, ou simplement omise.
À titre d'exemple. Lors de la troisième itération d'entraînement, la deuxième des m articulations peut être masquée, et ainsi de suite, jusqu'à ce que toutes les m articulations soient masquées et que seules les informations spatiales de n articulations soient fournies au modèle d'apprentissage automatique.
Ce processus est illustré dans les figures 5a à 5d. Plus précisément, sur la figure 5A, le modèle d'apprentissage automatique 400 est pourvu d'un ensemble de données d'entrée de formation. Dans ce mode de réalisation, les données d'entrée d'entraînement comprennent des informations spatiales correspondant à une pluralité de postures différentes de l'objet articulé, y compris la première posture 502A et la seconde posture 502B.
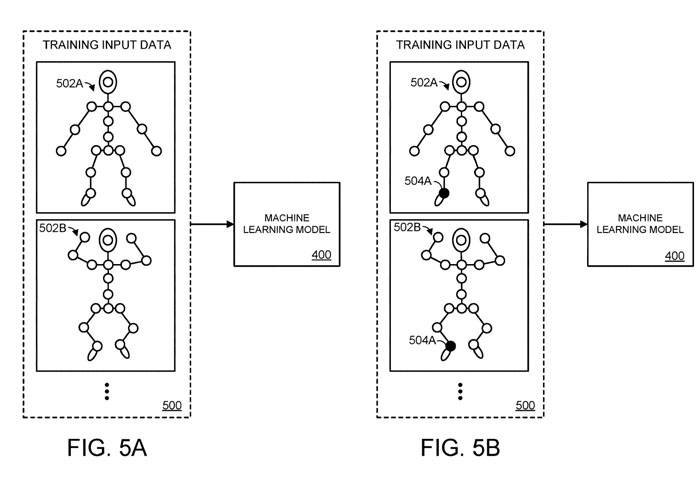
Dans la figure 5A, nous fournissons les informations spatiales de n+m articulations pour l'objet articulé du modèle d'apprentissage automatique. Dans cette représentation simplifiée du corps humain, chaque cercle représentant une articulation est représenté par un motif de remplissage blanc. Cependant, sur la figure 5B, nous avons blindé le 504A comme indiqué avec un motif de remplissage noir pour représenter le cercle du connecteur 504A
En d'autres termes, la figure 5A représente l'itération initiale du processus de formation, où les informations spatiales pour toutes les n+m articulations sont fournies au modèle d'apprentissage automatique. La figure 5B montre la deuxième itération du processus de formation, dans laquelle la première articulation 504A parmi les m articulations est masquée
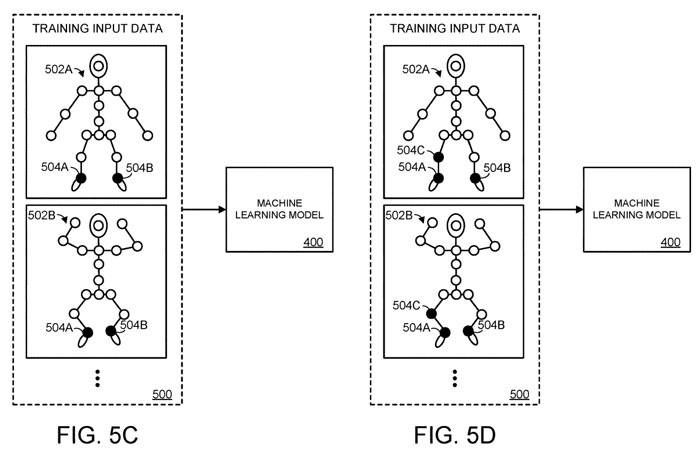
Sur la figure 5C, la deuxième articulation 504B parmi les m articulations représentées par la charnière est obstruée. De même, sur la figure 5D, la troisième articulation parmi les m articulations est obstruée. De multiples itérations d'entraînement peuvent être poursuivies jusqu'à ce que les informations spatiales de chacune des m articulations soient masquées, et seules les informations spatiales de n articulations soient fournies au modèle d'apprentissage automatique.
Dans le scénario ci-dessus, nous décrivons la situation où l'objet articulé est le corps entier du corps humain. Cependant, les objets articulés peuvent aussi prendre d'autres formes
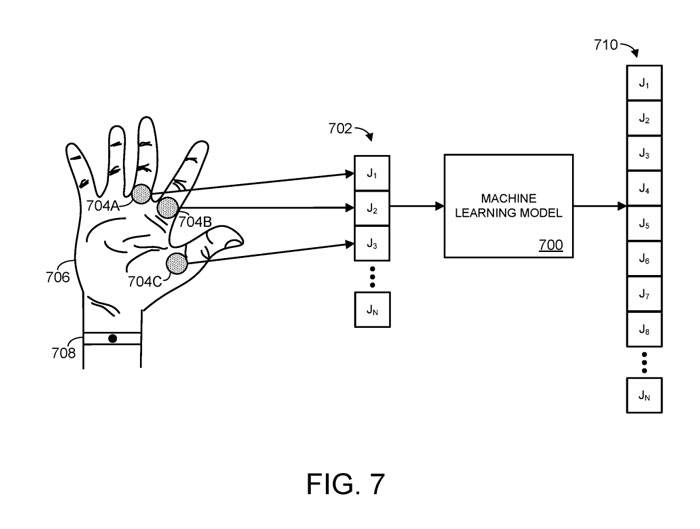
Comme le montre la figure 7, l'objet articulé est la main humaine, et non le corps humain tout entier. Plus précisément, la figure 7 montre un exemple de modèle d'apprentissage automatique 700.
Le modèle d'apprentissage automatique 700 reçoit des informations spatiales pour les articulations J1, J2 et J3, qui correspondent aux trois articulations 704A-C d'un objet articulé, prenant dans ce cas la forme d'une main humaine 706.
Dans ce cas précis, les n articulations comprennent une ou plusieurs articulations des doigts de la main humaine. Les informations spatiales d'une ou plusieurs articulations de doigts détaillent les paramètres d'un ou plusieurs doigts ou segments de doigts de la main humaine. Par exemple, les informations spatiales peuvent préciser la position/orientation des doigts de la main, et/ou la rotation appliquée aux articulations de la main
Toute méthode appropriée peut être utilisée pour collecter des informations sur l'espace articulaire, par exemple via le capteur de position 708. Par exemple, un capteur de position pourrait prendre la forme d’une caméra configurée pour imager la main. Comme autre exemple, un capteur de position pourrait inclure une antenne radiofréquence appropriée configurée pour exposer la surface de la main à un champ électromagnétique et évaluer l'effet du mouvement et de la proximité d'une peau humaine conductrice sur l'impédance du champ électromagnétique au niveau de l'antenne
Sur la base des informations spatiales d'entrée 702, le modèle d'apprentissage automatique produira un ensemble d'informations spatiales prédites 710. Les informations spatiales 710 peuvent être utilisées pour construire la pose prédite de l'objet articulé. Comme mentionné précédemment, ces informations spatiales peuvent représenter la position et l'orientation des parties du corps d'objets articulés
Brevets associés : Brevet Microsoft | Prédiction de pose pour un objet articulé
Microsoft a initialement soumis une demande de brevet intitulée « Prédiction de pose pour objet articulé » en juin 2022, et la demande a été récemment publiée par l'Office américain des brevets et des marques
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les casques AR/VR peuvent-ils sauver la valeur marchande d'Apple ? La révélation la plus complète est ici
- Luminosité 4K+5000nit ? Le casque Apple Reality Pro AR/VR exposé
- Il est révélé que le casque Apple AR/VR sera disponible en 6 couleurs et 2 spécifications
- Analyste de Morgan Stanley : Apple a entre 300 000 et 500 000 casques AR/VR en stock
- Creusez des centaines de brevets AR/VR et explorez tous les aspects d'Apple XR