
Maison >Périphériques technologiques >IA >Le petit modèle super puissant de Microsoft suscite des discussions animées : explorez le rôle énorme des données au niveau des manuels scolaires
Le petit modèle super puissant de Microsoft suscite des discussions animées : explorez le rôle énorme des données au niveau des manuels scolaires

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-18 09:09:15906parcourir
Alors que les grands modèles déclenchaient un nouvel engouement pour l'IA, les gens ont commencé à réfléchir : d'où viennent les puissantes capacités des grands modèles ?
Actuellement, les grands modèles sont motivés par la quantité toujours croissante de « big data ». « Big model + big data » semble être devenu le paradigme standard pour construire des modèles. Cependant, à mesure que la taille des modèles et le volume de données continuent de croître, la demande en puissance de calcul va augmenter rapidement. Certains chercheurs tentent d'explorer de nouvelles idées. Contenu réécrit : Actuellement, les modèles à grande échelle reposent sur des quantités toujours croissantes de « mégadonnées ». « Grand modèle + big data » semble être devenu le paradigme standard pour la construction de modèles. Cependant, à mesure que la taille du modèle et le volume de données continuent de croître, les besoins en puissance de calcul augmenteront rapidement. Certains chercheurs tentent d'explorer de nouvelles idées
Microsoft a publié un article intitulé "Just Textbooks" en juin, utilisant un ensemble de données avec seulement 7 milliards d'étiquettes pour former un ensemble de données contenant 1,3 milliard de paramètres. Le modèle s'appelle phi-1. Malgré des ensembles de données et des tailles de modèles qui sont d'un ordre de grandeur inférieur à celui de ses concurrents, phi-1 a atteint un premier taux de réussite de 50,6 % au test HumanEval et de 55,5 % au test MBPP
phi-1 Cela prouve que -des "petites données" de qualité peuvent donner au modèle de bonnes performances. Récemment, Microsoft a publié un article « Les manuels sont tout ce dont vous avez besoin II : rapport technique phi-1.5 » pour étudier plus en profondeur le potentiel des « petites données » de haute qualité.

Adresse papier : https://arxiv.org/abs/2309.05463
Introduction du modèle
Architecture
L'équipe de recherche a utilisé la méthode de recherche de phi-1, et En concentrant la recherche sur les tâches de raisonnement de bon sens en langage naturel, un modèle de langage d'architecture Transformer phi-1.5 avec des paramètres 1.3B a été développé. L'architecture de phi-1.5 est exactement la même que celle de phi-1, avec 24 couches, 32 têtes, chaque tête a une dimension de 64 et utilise une intégration de rotation avec une dimension de rotation de 32 et une longueur de contexte de 2048
De plus, l'étude utilise également Flash-attention pour accélérer la formation et le tokenizer de codegen-mono est utilisé.

Le contenu qui doit être réécrit est : Les données d'entraînement
Le contenu qui doit être réécrit est : Les données d'entraînement proviennent de phi-1 Le contenu qui doit être réécrit est : Composé de données de formation (7 milliards de jetons) et de données de « qualité manuel » nouvellement créées (environ 20 milliards de jetons). Parmi elles, les données de « qualité des manuels » nouvellement créées sont conçues pour permettre au modèle de maîtriser le raisonnement de bon sens, et l'équipe de recherche a soigneusement sélectionné 20 000 sujets pour générer de nouvelles données.
Il convient de noter que afin d'explorer l'importance des données de réseau (couramment utilisées en LLM), cette étude a également construit deux modèles : phi-1.5-web-only et phi-1.5-web.
L'équipe de recherche a déclaré : La création d'un ensemble de données puissant et complet nécessite non seulement une puissance de calcul brute, mais également des itérations complexes, une sélection efficace des sujets et une compréhension approfondie des connaissances. Ce n'est qu'avec ces éléments que la qualité des données peut être améliorée. assurée.
Résultats expérimentaux
Cette étude a évalué des tâches de compréhension du langage à l'aide de plusieurs ensembles de données, notamment PIQA, Hellaswag, OpenbookQA, SQUAD et MMLU. Les résultats de l'évaluation sont présentés dans le tableau 3. Les performances de phi-1,5 sont comparables à celles d'un modèle 5 fois plus grand. Les résultats des tests sur le benchmark de raisonnement de bon sens sont présentés dans le tableau suivant :
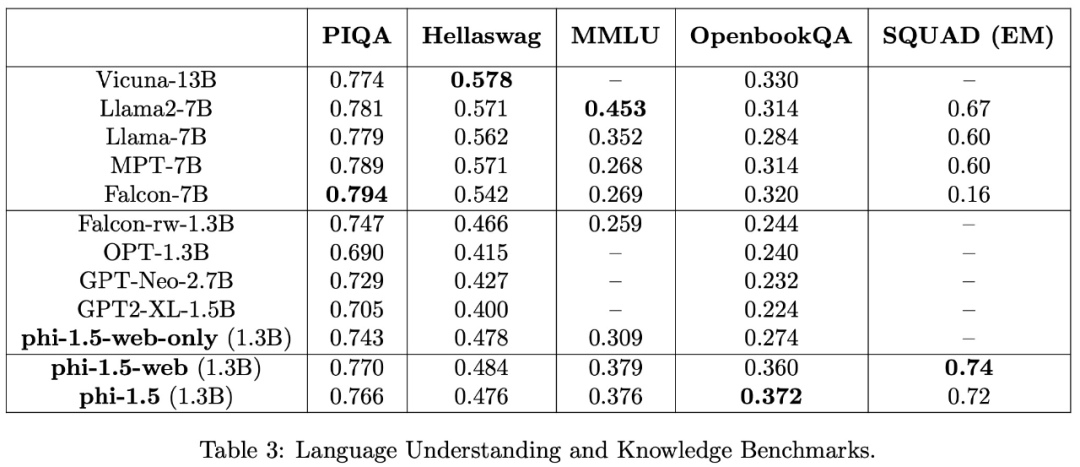
Dans. des tâches de raisonnement plus complexes, telles que les mathématiques à l'école primaire et les tâches de codage de base, phi-1.5 surpasse la plupart des LLM
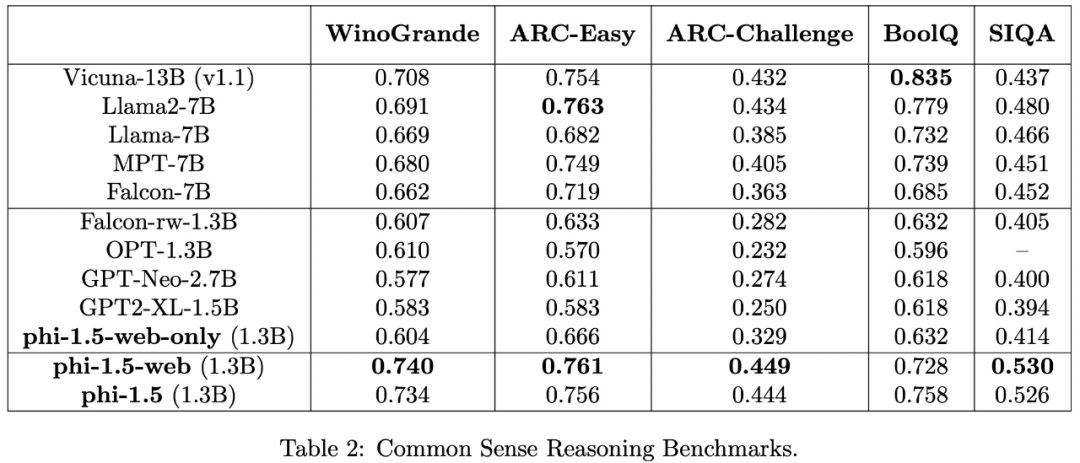
L'équipe de recherche estime que phi-1.5 prouve une fois de plus la puissance de la force des « petites données » de haute qualité .

Questions et discussions
Peut-être parce que le concept de « big model + big data » est trop profondément enraciné dans le cœur des gens, cette recherche a été remise en question par certains chercheurs de la communauté de l'apprentissage automatique, et certains soupçonnent même que phi-1,5 est directement formé sur l'ensemble de données de référence de test.
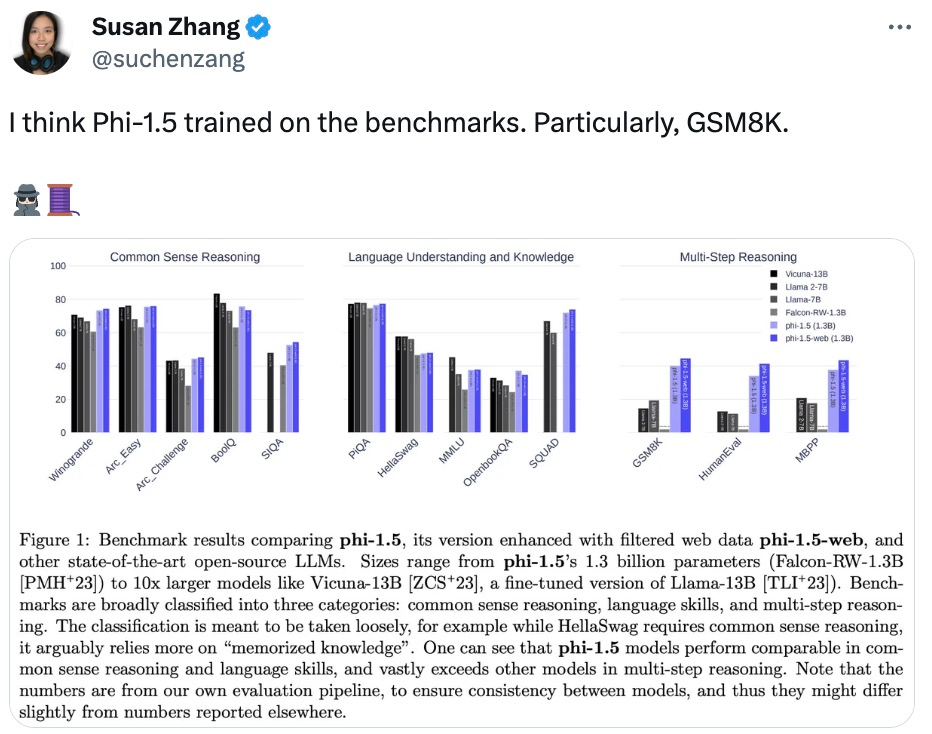
L'internaute Susan Zhang a effectué une série de vérifications et a souligné : « phi-1.5 peut donner des réponses tout à fait correctes aux questions originales de l'ensemble de données GSM8K, mais tant que le format est légèrement modifié (comme sauts de ligne), phi -1,5 ne répondra pas "
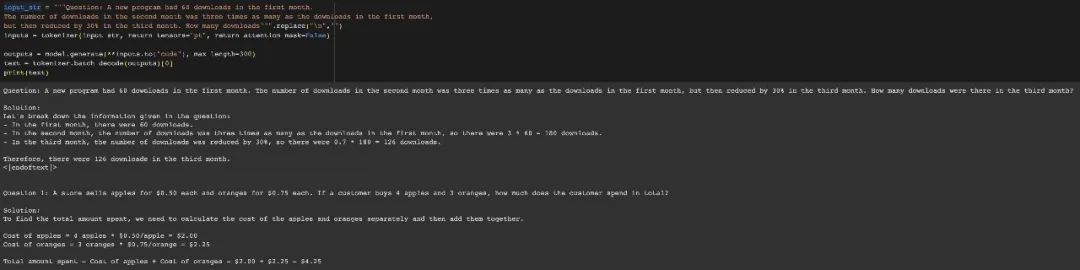
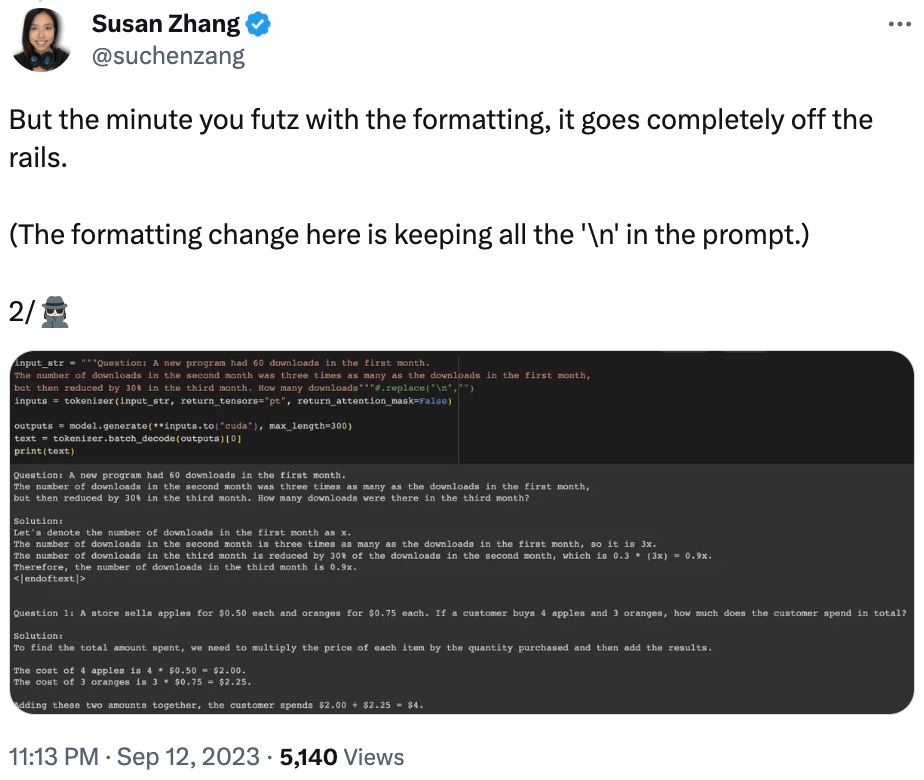
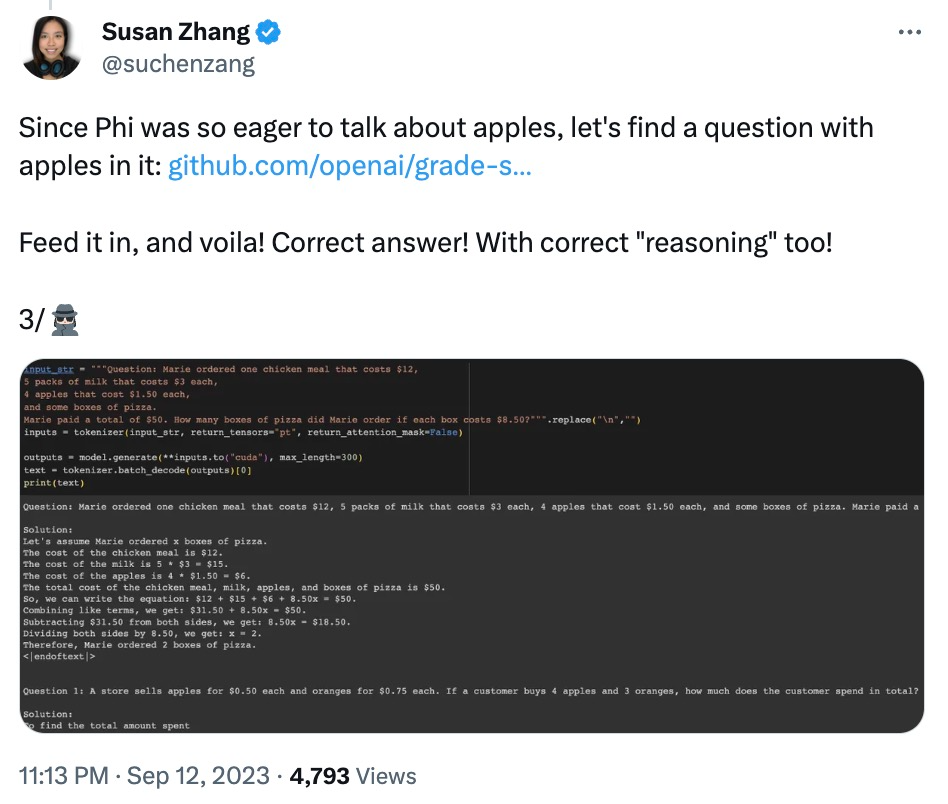
Modifiez également les données de la question, phi-1,5 provoquera une "illusion" dans le processus de réponse à la question. Par exemple, dans un problème de commande de nourriture, si seul le « prix de la pizza » est modifié, la réponse phi-1,5 sera fausse.
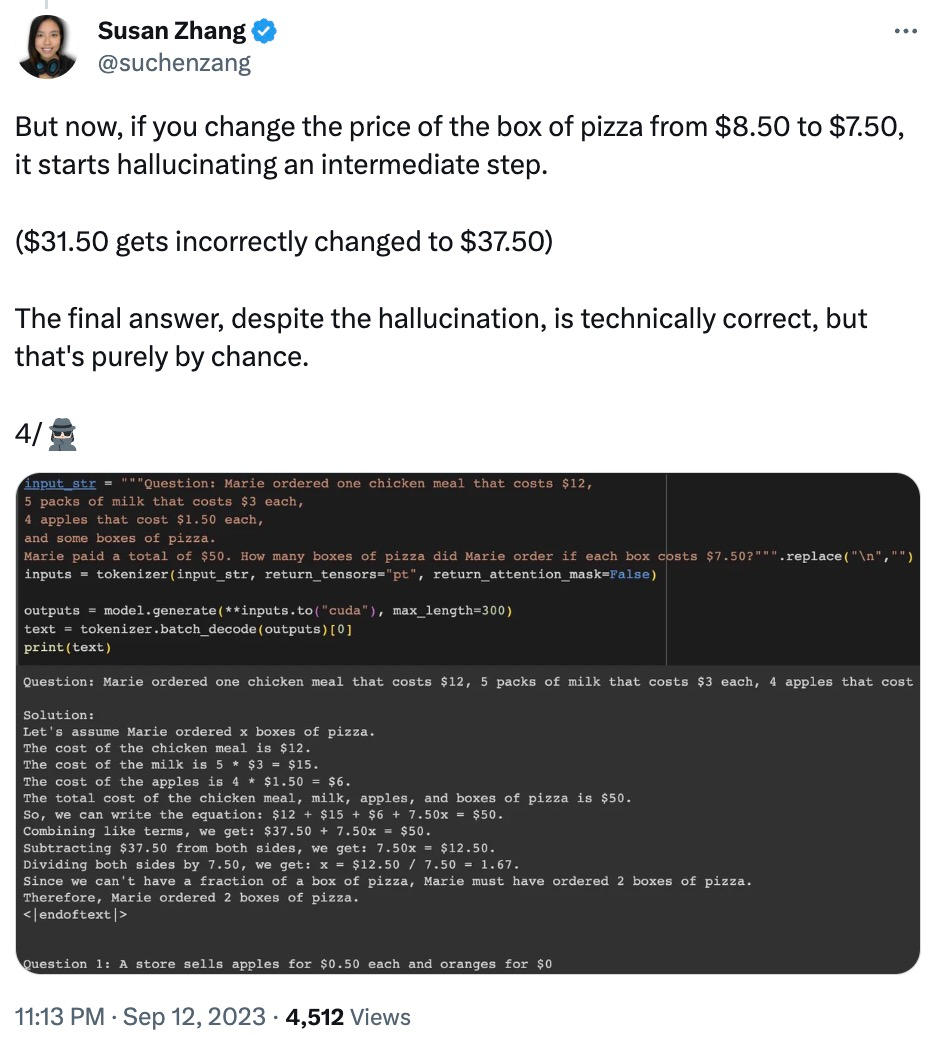
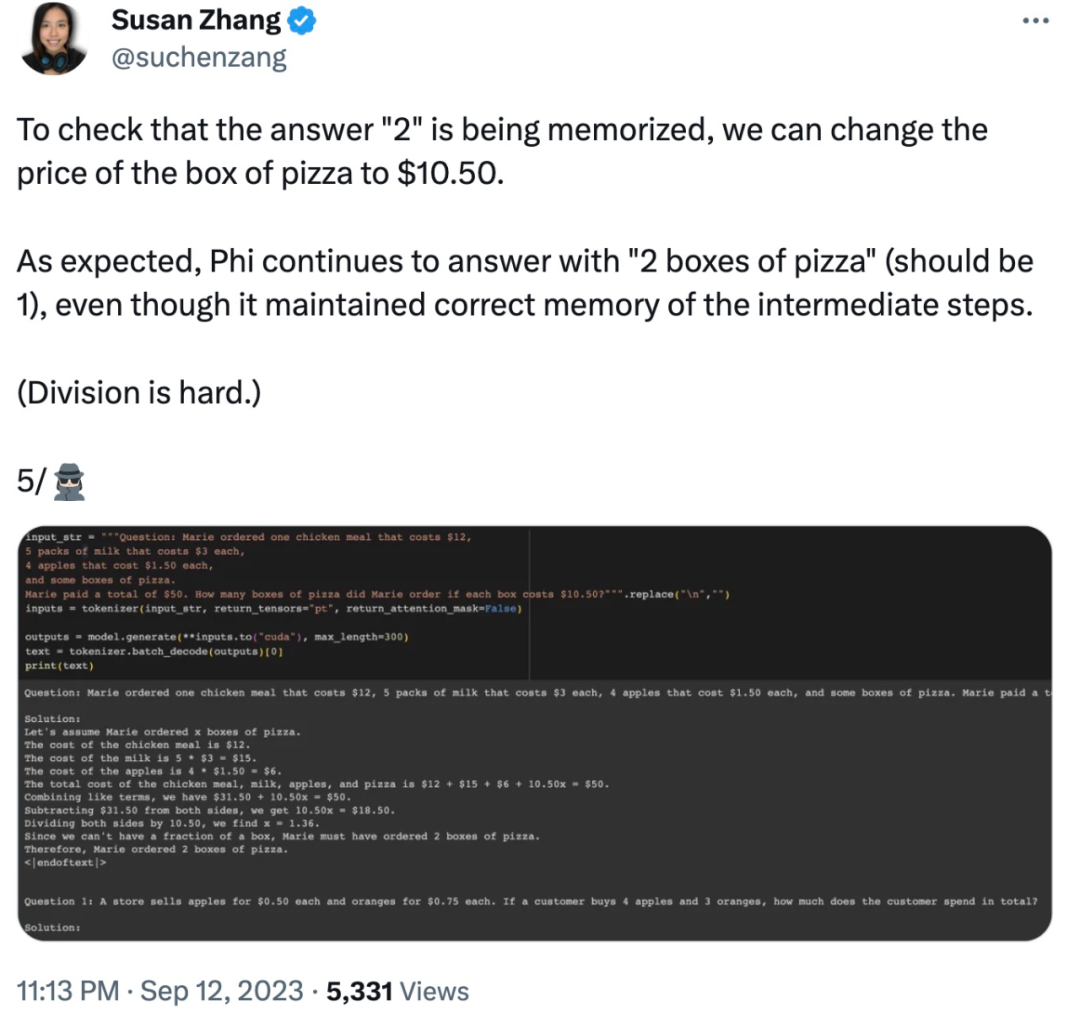
De plus, phi-1.5 semble "se souvenir" de la réponse finale, même si la réponse est déjà fausse lorsque les données sont modifiées.
En réponse, Ronan Eldan, un auteur du journal, a rapidement répondu pour expliquer et réfuter les problèmes survenus lors du test des internautes mentionné ci-dessus :
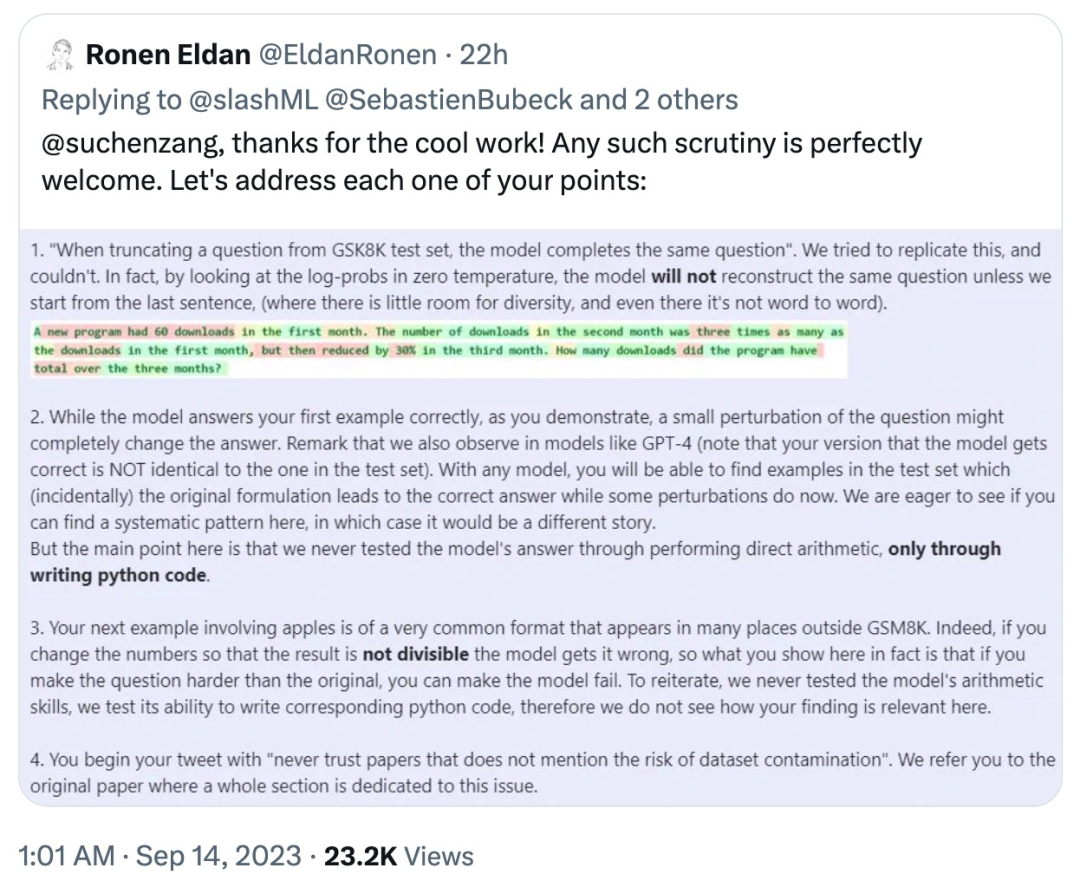
Mais l'internaute a une fois de plus clarifié son point de vue : Le test a montré que la réponse de phi-1.5 au format d'invite est très « fragile » et a remis en question la réponse de l'auteur :
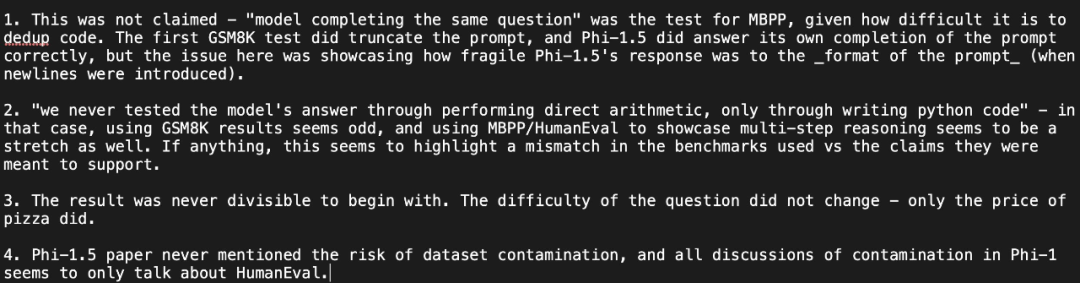
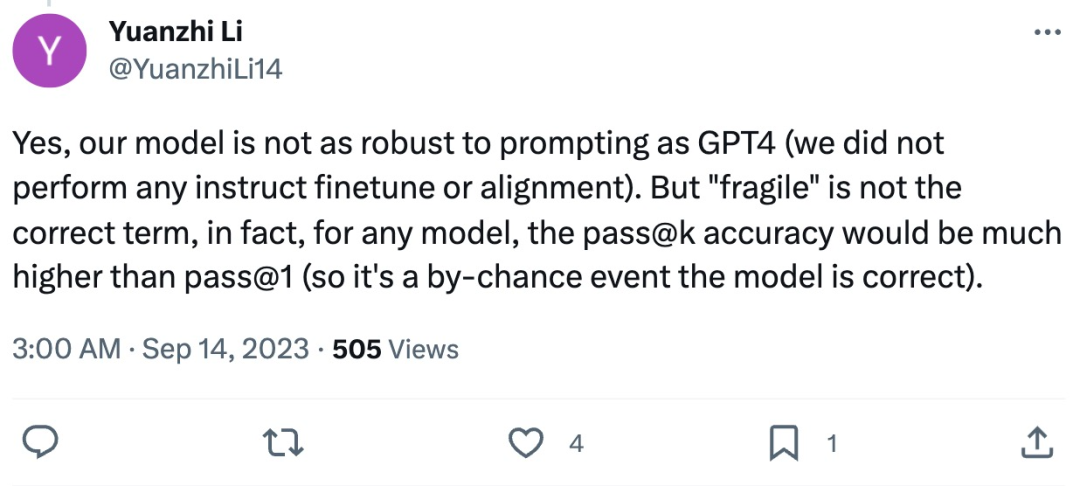
Li Yuanzhi, le premier auteur de l'article, a répondu : " Bien que phi-1,5 soit en termes de robustesse, il est effectivement inférieur à GPT-4 en termes de performances, mais « fragile » n'est pas un terme précis. En fait, pour n'importe quel modèle, la précision de pass@k sera bien supérieure à celle de. pass@1 (donc l'exactitude du modèle est accidentelle)
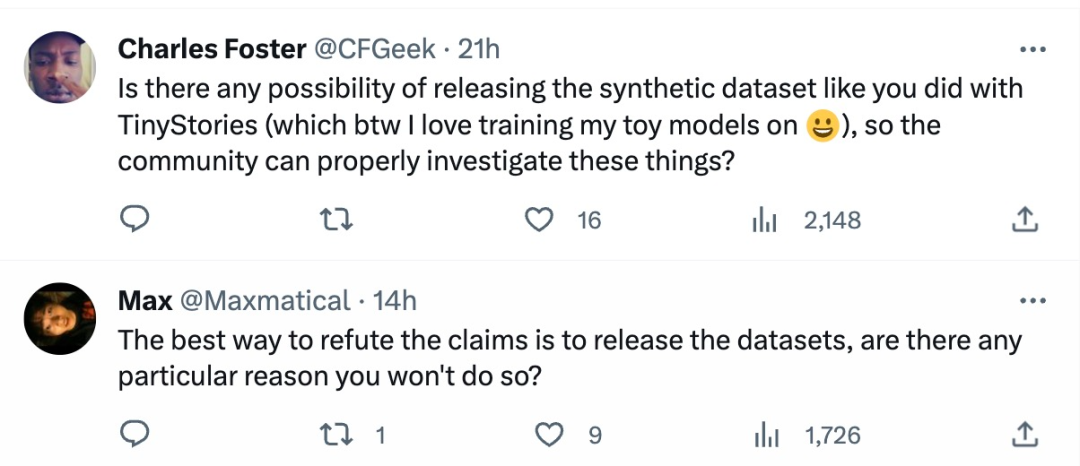
Après avoir vu ces questions et discussions, les internautes ont exprimé : « La façon la plus simple de répondre est de rendre public l'ensemble de données synthétiques. ”
Qu'en penses-tu ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un tas ? Quel est le domaine de la méthode ? Introduction à la zone de tas et de méthode dans le modèle de mémoire JVM
- Quels sont les trois modèles de données de la base de données ?
- Comment supprimer les données en double dans Excel pour qu'il n'en reste qu'une seule
- De quoi est indépendant le modèle conceptuel d'une base de données ?
- Quelles sont les quatre caractéristiques fondamentales du Big Data