
Maison >Périphériques technologiques >IA >Écoutez-moi, Transformer est une machine à vecteurs de support
Écoutez-moi, Transformer est une machine à vecteurs de support

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-17 18:09:03791parcourir
Transformer est une machine à vecteurs de support (SVM), une nouvelle théorie qui a déclenché des discussions au sein de la communauté universitaire.
Le week-end dernier, un article de l'Université de Pennsylvanie et de l'Université de Californie à Riverside a tenté d'étudier les principes de la structure Transformer basée sur de grands modèles, sa géométrie optimisée dans la couche d'attention et la séparation des jetons d'entrée optimaux de jetons non optimaux. Une équivalence formelle est établie entre les problèmes SVM limités.
L'auteur a déclaré sur hackernews que cette théorie résout le problème du SVM séparant les « bons » jetons des « mauvais » jetons dans chaque séquence d'entrée. En tant que sélecteur de jetons offrant d'excellentes performances, ce SVM est essentiellement différent du SVM traditionnel qui attribue des étiquettes 0-1 à l'entrée.
Cette théorie explique également comment l'attention induit la parcimonie via softmax : les "mauvais" jetons qui tombent du mauvais côté de la limite de décision SVM sont supprimés par la fonction softmax, tandis que les "bons" jetons sont ceux qui se retrouvent avec des non- jeton de probabilité softmax zéro. Il convient également de mentionner que ce SVM dérive des propriétés exponentielles de softmax.
Après le téléchargement de l'article sur arXiv, les gens ont exprimé leurs opinions les uns après les autres. Certaines personnes ont dit : La direction de la recherche sur l'IA est vraiment en spirale, est-ce qu'elle va revenir en arrière ?
Après avoir bouclé la boucle, les machines à vecteurs de support ne sont toujours pas obsolètes.
Depuis la publication de l'article classique « Attention is All You Need », l'architecture Transformer a apporté des progrès révolutionnaires dans le domaine du traitement du langage naturel (NLP). La couche d'attention de Transformer accepte une série de jetons d'entrée X et évalue la corrélation entre les jetons en calculant 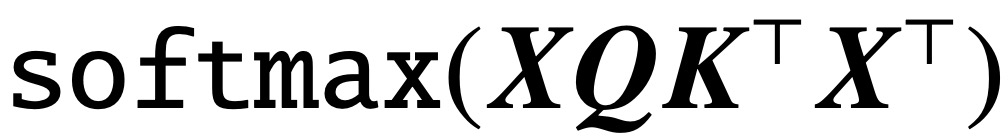 , où (K, Q) sont des paramètres de requête clé pouvant être entraînés, capturant finalement efficacement les dépendances distantes.
, où (K, Q) sont des paramètres de requête clé pouvant être entraînés, capturant finalement efficacement les dépendances distantes.
Maintenant, un nouvel article intitulé "Transformers as Support Vector Machines" établit une équivalence formelle entre la géométrie d'optimisation de l'attention personnelle et le problème SVM à marge dure, en utilisant le produit externe linéaire des paires de jetons. Les contraintes séparent les jetons d'entrée optimaux. à partir de jetons non optimaux.

Lien papier : https://arxiv.org/pdf/2308.16898.pdf
Cette équivalence formelle est basée sur l'article "Max-Margin Token Selection in Attention Mechanism" de Davoud Ataee Tarzanagh et al. "Sur la base de la régularisation Vanishing, convergeant vers une solution SVM qui minimise la norme nucléaire des paramètres combinés
. En revanche, le paramétrage directement via W minimise l'objectif de la norme Frobenius SVM. L'article décrit cette convergence et souligne qu'elle peut se produire dans le sens d'un optimum local plutôt que d'un optimum global. 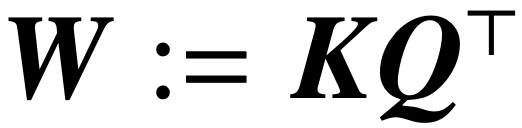 (2) L'article démontre également la convergence directionnelle locale/globale de la descente de gradient de paramétrage W dans des conditions géométriques appropriées. Il est important de noter que la surparamétrage catalyse la convergence globale en garantissant la faisabilité du problème SVM et en garantissant un environnement d'optimisation bénin sans points stationnaires.
(2) L'article démontre également la convergence directionnelle locale/globale de la descente de gradient de paramétrage W dans des conditions géométriques appropriées. Il est important de noter que la surparamétrage catalyse la convergence globale en garantissant la faisabilité du problème SVM et en garantissant un environnement d'optimisation bénin sans points stationnaires.
(3) Bien que la théorie de cette étude s'applique principalement aux têtes de prédiction linéaires, l'équipe de recherche propose un équivalent SVM plus général qui peut prédire la polarisation implicite des transformateurs à 1 couche avec des têtes/MLP non linéaires.
En général, les résultats de cette étude sont applicables aux ensembles de données généraux et peuvent être étendus aux couches d'attention croisée, et la validité pratique des conclusions de l'étude a été vérifiée grâce à des expériences numériques approfondies. Cette étude établit une nouvelle perspective de recherche qui considère les transformateurs multicouches comme des hiérarchies SVM qui séparent et sélectionnent les meilleurs jetons.
Plus précisément, étant donné une séquence d'entrée de longueur T et de dimension d'intégration d
, cette étude analyse les principaux modèles d'attention croisée et d'auto-attention :

où K, Q, V sont respectivement des matrices de clé, de requête et de valeur entraînables, 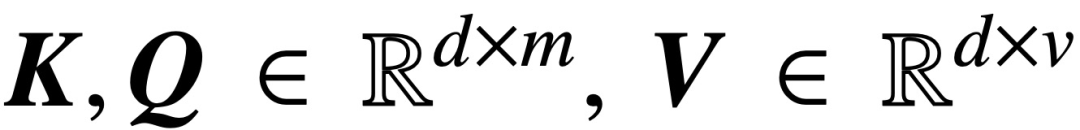 S (・) représente la non-linéarité softmax, qui est appliquée ligne par ligne
S (・) représente la non-linéarité softmax, qui est appliquée ligne par ligne 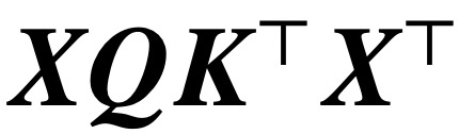 ; L'étude suppose que le premier jeton de Z (noté z) est utilisé pour la prédiction. Plus précisément, étant donné un ensemble de données d'entraînement
; L'étude suppose que le premier jeton de Z (noté z) est utilisé pour la prédiction. Plus précisément, étant donné un ensemble de données d'entraînement 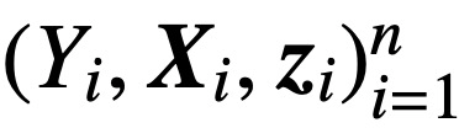 ,
, 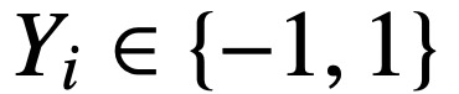 ,
, 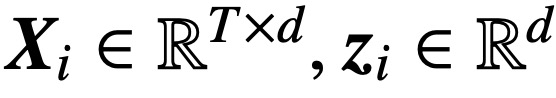 , cette étude utilise la fonction de perte décroissante
, cette étude utilise la fonction de perte décroissante  pour minimiser :
pour minimiser :
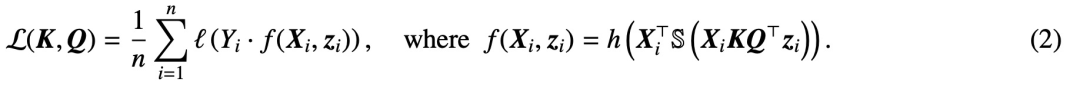
Ici, h (・) : 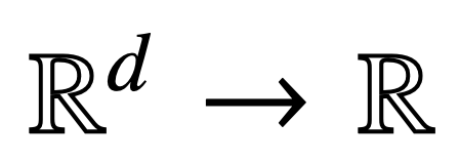 est l'en-tête de prédiction contenant la valeur poids V. Dans cette formulation, le modèle f (・) représente avec précision un transformateur monocouche où la couche d'attention est suivie d'un MLP. L'auteur restaure l'auto-attention dans (2) en posant
est l'en-tête de prédiction contenant la valeur poids V. Dans cette formulation, le modèle f (・) représente avec précision un transformateur monocouche où la couche d'attention est suivie d'un MLP. L'auteur restaure l'auto-attention dans (2) en posant 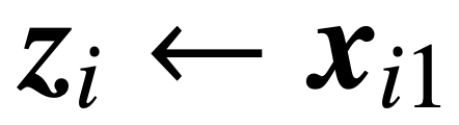 , où x_i représente le premier jeton de la séquence X_i. En raison de la nature non linéaire de l’opération softmax, elle pose un énorme défi en matière d’optimisation. Même si la tête de prédiction est fixe et linéaire, le problème est non convexe et non linéaire. Dans cette étude, les auteurs se concentrent sur l’optimisation des poids d’attention (K, Q ou W) et sur la résolution de ces défis pour établir l’équivalence de base des SVM.
, où x_i représente le premier jeton de la séquence X_i. En raison de la nature non linéaire de l’opération softmax, elle pose un énorme défi en matière d’optimisation. Même si la tête de prédiction est fixe et linéaire, le problème est non convexe et non linéaire. Dans cette étude, les auteurs se concentrent sur l’optimisation des poids d’attention (K, Q ou W) et sur la résolution de ces défis pour établir l’équivalence de base des SVM.
La structure de l'article est la suivante : le chapitre 2 introduit les connaissances préliminaires sur l'auto-attention et l'optimisation ; le chapitre 3 analyse la géométrie d'optimisation de l'auto-attention, montrant que le paramètre d'attention RP converge vers la solution marginale maximale ; Le chapitre 4 et le chapitre 5 présentent respectivement l'analyse de descente de gradient globale et locale, montrant que la variable de requête clé W converge vers la solution de (Att-SVM) ; le chapitre 6 fournit des résultats sur l'équivalence des têtes de prédiction non linéaires et du chapitre SVM généralisé ; Le chapitre 7 étend la théorie à la prédiction séquentielle et causale ; le chapitre 8 discute de la littérature connexe. Enfin, le chapitre 9 conclut en proposant des questions ouvertes et des orientations de recherche futures.
Le contenu principal de l'article est le suivant :
Biais implicite dans la couche d'attention (Chapitre 2-3)
Optimisation des paramètres d'attention (K, Q) lorsque la régularisation disparaît, convergera vers la solution marginale maximale de  dans la direction, et sa norme nucléaire cible est le paramètre de combinaison
dans la direction, et sa norme nucléaire cible est le paramètre de combinaison 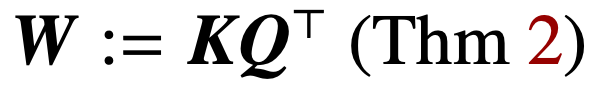 . Dans le cas du paramétrage direct de l'attention croisée avec le paramètre combiné W, le chemin de régularisation (RP) converge directionnellement vers la solution (Att-SVM) ciblant la norme de Frobenius.
. Dans le cas du paramétrage direct de l'attention croisée avec le paramètre combiné W, le chemin de régularisation (RP) converge directionnellement vers la solution (Att-SVM) ciblant la norme de Frobenius.
Il s'agit du premier résultat permettant de distinguer formellement les dynamiques d'optimisation paramétrique W versus (K, Q), révélant des biais d'ordre inférieur dans cette dernière. La théorie de cette étude décrit clairement l’optimalité des jetons sélectionnés et s’étend naturellement aux paramètres de classification séquence à séquence ou causale.
Convergence de la descente de gradient (Chapitre 4-5)
Avec une initialisation appropriée et une tête linéaire h (・), les itérations de descente de gradient (GD) de la variable de requête clé combinée W convergent dans la direction vers la solution optimale locale de (Att-SVM) (Section 5). Pour atteindre un optimum local, le jeton sélectionné doit avoir un score plus élevé que les jetons adjacents.
La direction optimale locale n'est pas nécessairement unique et peut être déterminée en fonction des caractéristiques géométriques du problème [TLZO23]. Comme contribution importante, les auteurs identifient les conditions géométriques qui garantissent la convergence vers l'optimum global (chapitre 4). Ces conditions incluent :
- Le meilleur jeton a une nette différence de score
- La direction initiale du dégradé est cohérente avec le meilleur jeton ;
De plus, l'article montre également que le surparamétrage (c'est-à-dire que la dimension d est grande et les mêmes conditions) en garantissant la faisabilité de (1) (Att-SVM) et (2) un effet bénin paysage d’optimisation (c’est-à-dire qu’il n’y a pas de points stationnaires ni de directions optimales locales parasites) pour catalyser la convergence globale (voir Section 5.2).
Les figures 1 et 2 illustrent cela.
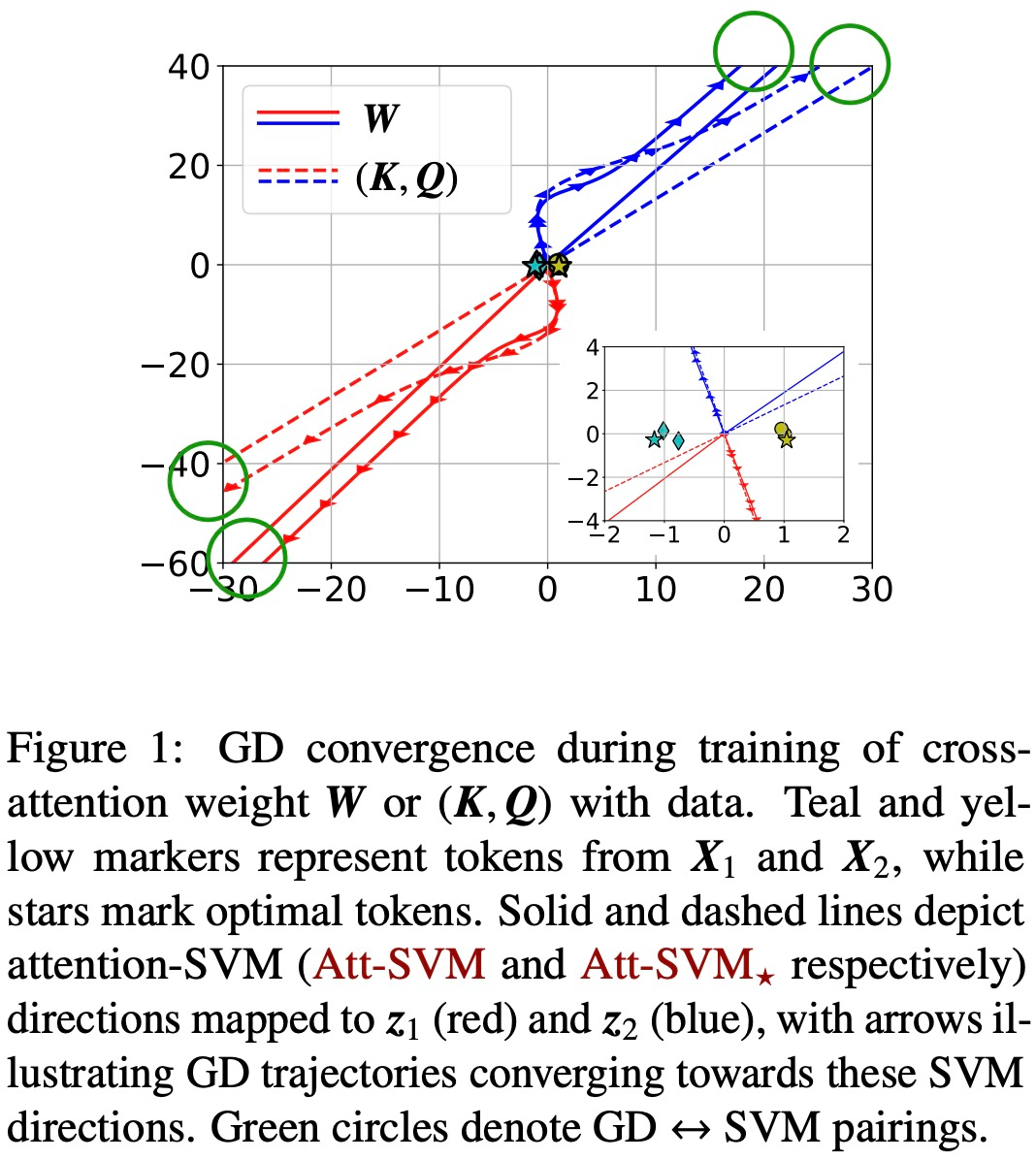
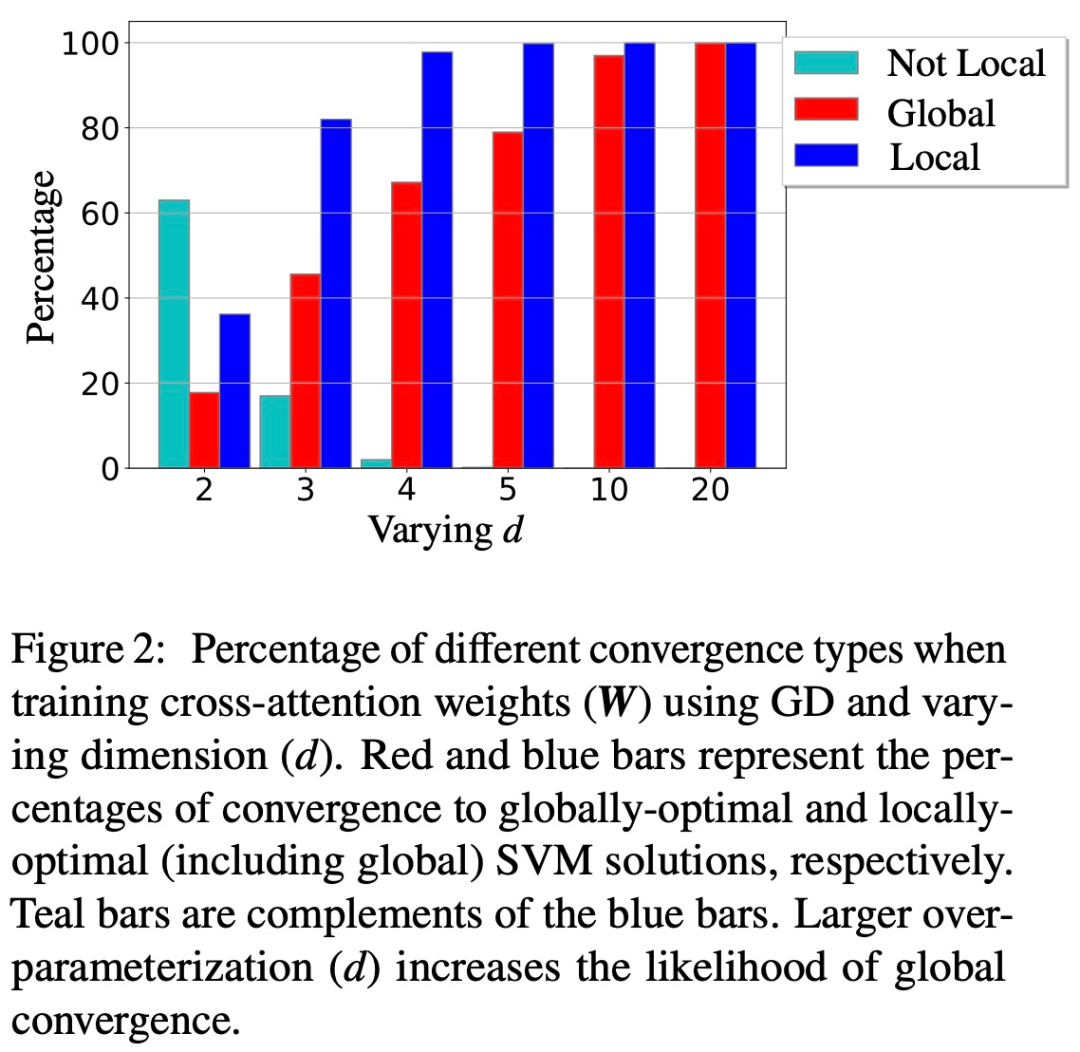
Généralité de l'équivalent SVM (Chapitre 6)
La couche d'attention est inhérente lors de l'optimisation avec h linéaire (・) Biais au sol pour sélectionner un jeton chaque séquence (c'est-à-dire une grande attention). Cela se reflète dans (Att-SVM), où le jeton de sortie est une combinaison convexe des jetons d'entrée. En revanche, les auteurs montrent que les têtes non linéaires doivent être composées de plusieurs jetons, soulignant ainsi leur importance dans la dynamique des transformateurs (Section 6.1). En utilisant les enseignements tirés de la théorie, les auteurs proposent une approche équivalente plus générale du SVM.
Notamment, ils démontrent que notre méthode peut prédire avec précision le biais implicite de l'attention entraînée via la descente de gradient dans des cas généraux non couverts par la théorie (par exemple, h (・) est un MLP). Plus précisément, notre formule générale découple le poids d'attention en deux parties : une partie directionnelle contrôlée par SVM, qui sélectionne les marqueurs en appliquant un masque 0-1 et une partie finie, qui ajuste la probabilité softmax pour déterminer la composition précise du jeton sélectionné ;
Une caractéristique importante de ces résultats est qu'ils s'appliquent à des ensembles de données arbitraires (tant que la SVM est réalisable) et peuvent être vérifiés numériquement. Les auteurs ont vérifié expérimentalement de manière approfondie l'équivalence marginale maximale et la polarisation implicite du transformateur. Les auteurs pensent que ces résultats contribuent à la compréhension des transformateurs en tant que mécanisme hiérarchique de sélection de jetons à marge maximale et peuvent jeter les bases des recherches à venir sur leur dynamique d’optimisation et de généralisation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les bases de données relationnelles couramment utilisées ?
- Les données stockées dans la RAM seront-elles perdues après une panne de courant ?
- Que dois-je faire si le texte WPS ne parvient pas à ouvrir la source de données ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?
- Quels sont les protocoles appartenant à la couche application dans le modèle de référence TCP IP ?