
Maison >Périphériques technologiques >IA >UniOcc : Unifier la prédiction d'occupation centrée sur la vision avec un rendu géométrique et sémantique !
UniOcc : Unifier la prédiction d'occupation centrée sur la vision avec un rendu géométrique et sémantique !

- 王林avant
- 2023-09-16 20:29:10764parcourir
Titre original : UniOcc : Unifying Vision-Centric 3D Occupancy Prediction withometric and Semantic Rendering
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2306.09117.pdf

Paper idée :
Dans ce rapport technique, nous proposons une solution appelée UniOCC pour les trajectoires de prédiction d'occupation 3D centrées sur la vision dans le cadre du CVPR 2023 nuScenes Open Dataset Challenge. Les méthodes de prédiction d'occupation existantes se concentrent principalement sur l'utilisation d'étiquettes d'occupation 3D pour optimiser les caractéristiques projetées de l'espace volumétrique 3D. Cependant, le processus de génération de ces étiquettes est très complexe et coûteux (reposant sur une annotation sémantique 3D), et est limité par la résolution des voxels et ne peut pas fournir une sémantique spatiale à granularité fine. Pour remédier à cette limitation, nous proposons une nouvelle méthode de prédiction d'occupation unifiée (UniOcc) qui impose explicitement des contraintes géométriques spatiales et complète la supervision sémantique fine avec un rendu de rayons de volume. Notre méthode améliore considérablement les performances du modèle et montre un bon potentiel pour réduire les coûts d'annotation manuelle. Compte tenu de la complexité de l'annotation des occupations 3D, nous proposons en outre le cadre Teacher Student (DTS) sensible à la profondeur pour améliorer la précision des prédictions à l'aide de données non étiquetées. Notre solution a atteint 51,27 % mIoU sur le classement officiel monomodèle, se classant troisième dans ce défi
Conception de réseau :
Dans ce défi, cet article propose UniOcc, qui est une solution générale qui exploite le rendu de volume pour unifier la supervision de représentations 2D et 3D, améliorant les modèles de prédiction d'occupation multi-caméras. Cet article ne conçoit pas une nouvelle architecture de modèle, mais se concentre sur l'amélioration des modèles existants [3, 18, 20] de manière polyvalente et plug-and-play.
Réécrit comme suit : cet article implémente la fonction de génération de cartes sémantiques et de profondeur 2D à l'aide du rendu de volume en mettant à niveau la représentation vers une représentation de style NeRF [1, 15, 21]. Cela permet une supervision fine au niveau des pixels 2D. Par échantillonnage de rayons de voxels tridimensionnels, la sémantique de pixel bidimensionnelle restituée et les informations de profondeur peuvent être obtenues. En intégrant explicitement les relations d'occlusion géométrique et les contraintes de cohérence sémantique, cet article fournit des conseils explicites pour le modèle et garantit le respect de ces contraintes. Il convient de mentionner qu'UniOcc a le potentiel de réduire le recours à des annotations sémantiques 3D coûteuses. En l'absence d'étiquettes d'occupation 3D, les modèles formés à l'aide uniquement de notre supervision de rendu de volume fonctionnent encore mieux que les modèles formés à l'aide de la supervision d'étiquettes 3D. Cela met en évidence le potentiel passionnant de réduire le recours à des annotations sémantiques 3D coûteuses, car les représentations de scènes peuvent être apprises directement à partir d’étiquettes de segmentation 2D abordables. De plus, le coût de l'annotation de segmentation 2D peut être encore réduit en utilisant des technologies avancées telles que SAM [6] et [14,19].
Cet article présente également le cadre Depth Sensing Teacher-Student (DTS), une méthode de formation auto-supervisée. Différent du Mean Teacher classique, DTS améliore la prédiction approfondie du modèle d'enseignant, permettant une formation stable et efficace tout en utilisant des données non étiquetées. De plus, cet article applique quelques techniques simples mais efficaces pour améliorer les performances du modèle. Cela inclut l'utilisation de masques visibles lors de la formation, l'utilisation d'un réseau fédérateur pré-entraîné plus solide, l'augmentation de la résolution des voxels et la mise en œuvre de l'augmentation des données au moment du test (TTA)
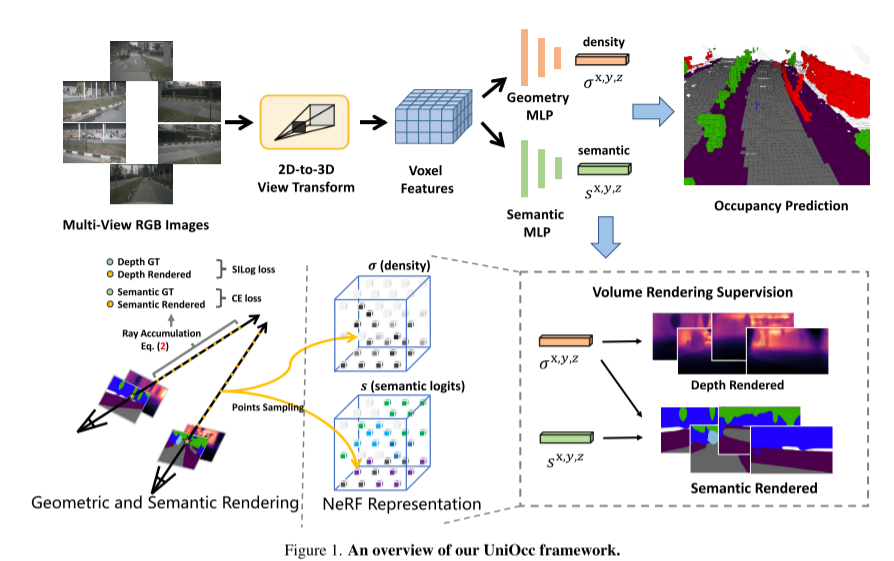 Voici un aperçu du framework UniOcc :
Image 1
Voici un aperçu du framework UniOcc :
Image 1
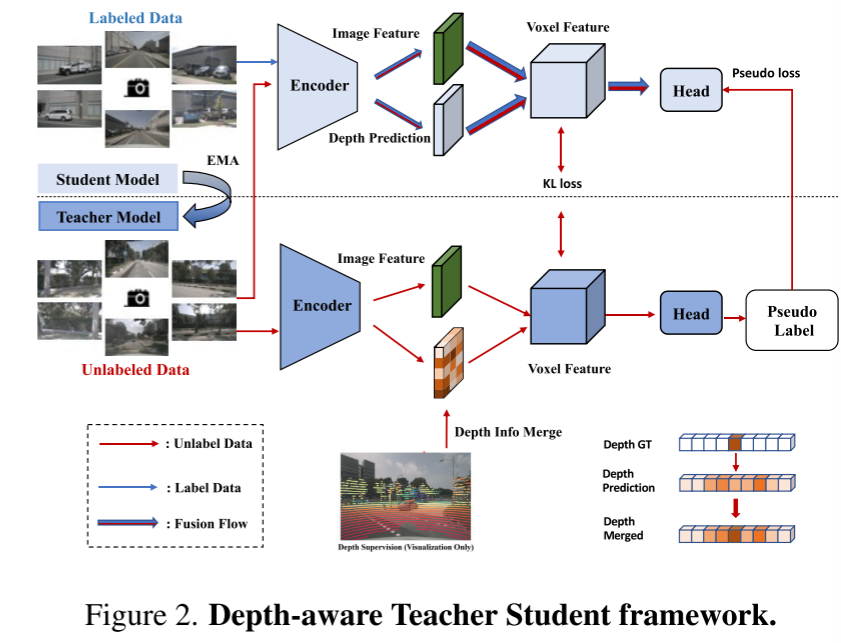 Image 2. Cadre enseignant-élève soucieux de la profondeur.
Image 2. Cadre enseignant-élève soucieux de la profondeur.

Pan, M., Liu, L., Liu, J., Huang, P., Wang, L., Zhang, S. , Xu, S., Lai, Z., Yang, K. (2023). UniOcc : unifier le rendu géométrique et sémantique avec une prédiction d'occupation 3D centrée sur la vision. ArXiv. /abdos/2306.09117
 Lien original : https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Lien original : https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles applications technologiques de collecte de données le développement d'applications de bracelets de santé intelligents incarne-t-il ?
- Quels sont les produits des appareils intelligents ?
- Vous possédez un smartphone avec trois cartes SIM et trois veilles ?
- Vivo a-t-il un robot vocal intelligent ?
- Explication détaillée de la bibliothèque de vision par ordinateur opencv en Python