
Maison >Périphériques technologiques >IA >Accélération de formation de 32 cartes à 176 %, cadre de formation open source pour grands modèles Megatron-LLaMA est là
Accélération de formation de 32 cartes à 176 %, cadre de formation open source pour grands modèles Megatron-LLaMA est là

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-14 16:01:05696parcourir
Taotian Group et Aicheng Technology ont officiellement publié le cadre de formation open source pour grands modèles - Megatron-LLaMA le 12 septembre. L'objectif de ce cadre est de permettre aux développeurs de technologies d'améliorer plus facilement les performances de formation des grands modèles de langage, de réduire les coûts de formation et de maintenir la compatibilité avec la communauté LLaMA. Les résultats des tests montrent que sur une formation à 32 cartes, Megatron-LLaMA peut atteindre une accélération de 176 % par rapport à la version de code obtenue directement sur HuggingFace ; sur une formation à grande échelle, Megatron-LLaMA s'étend presque linéairement et est instable au réseau. niveau de tolérance. Actuellement, Megatron-LLaMA est en ligne dans la communauté open source
Adresse open source : https://github.com/alibaba/Megatron-LLaMA
Les performances exceptionnelles des grands modèles de langage ont dépassé le temps de l'imagination des gens et encore une fois. Au cours des derniers mois, LLaMA et LLaMA2 ont été mis à la disposition générale de la communauté open source, offrant une excellente option pour ceux qui souhaitent former leurs propres grands modèles de langage. Dans la communauté open source, il existe déjà de nombreux modèles développés sur la base de LLaMA, notamment la formation continue/SFT (comme Alpaca, Vicuna, WizardLM, Platypus, StableBegula, Orca, OpenBuddy, Linly, Ziya, etc.) et la formation à partir de zéro ( tels que Baichuan, QWen, InternLM, OpenLLaMA). Ces travaux ont non seulement donné de bons résultats sur diverses listes d'évaluation objectives des capacités des grands modèles, mais ont également démontré d'excellentes performances dans des scénarios d'application pratiques tels que la compréhension de textes longs, la génération de textes longs, l'écriture de code et la résolution mathématique. De plus, de nombreux produits intéressants ont vu le jour dans l'industrie, comme LLaMA combiné au robot de chat vocal de Whisper, LLaMA combiné au logiciel de peinture de Stable Diffusion, et des robots de consultation auxiliaires dans le domaine médical/juridique, etc.
Bien que vous puissiez obtenez LLaMA à partir du code du modèle HuggingFace, mais la formation d'un modèle LLaMA avec vos propres données n'est pas une tâche simple et peu coûteuse pour les utilisateurs individuels ou les petites et moyennes organisations. Le volume des grands modèles et l'ampleur des données rendent impossible une formation efficace sur des ressources informatiques ordinaires, et la puissance et le coût de calcul sont devenus de sérieux goulots d'étranglement. Les utilisateurs de la communauté Megatron-LM ont des demandes très urgentes à cet égard.
Taotian Group et Aicheng Technology disposent de scénarios d'application très larges pour les applications de grands modèles et ont beaucoup investi dans une formation efficace des grands modèles. L'avènement de LLaMA a donné à de nombreuses entreprises, dont Taotian Group et Aicheng Technology, beaucoup d'inspiration en termes de traitement des données, de conception de modèles, de réglage fin et d'ajustement du retour d'apprentissage par renforcement, et a également contribué à réaliser de nouvelles percées dans les scénarios d'applications métier. . Par conséquent, afin de redonner à l'ensemble de la communauté open source LLaMA et de promouvoir le développement de la communauté open source chinoise de grands modèles pré-entraînés, afin que les développeurs puissent plus facilement améliorer les performances de formation des grands modèles de langage et réduire les coûts de formation, Taotian Le groupe et Aicheng Technology combineront certaines technologies internes pour optimiser la technologie et l'ouvrir en source libre, publieront Megatron-LLaMA et seront impatients de construire l'écosystème Megatron et LLaMA avec chaque partenaire.
Megatron-LLaMA fournit un ensemble de LLaMA standard implémentés par Megatron-LM, et fournit des outils de commutation gratuite avec le format HuggingFace pour faciliter la compatibilité avec les outils écologiques communautaires. Megatron-LLaMA a repensé le processus inverse de Megatron-LM, afin qu'il puisse être réalisé peu importe où le nombre de nœuds est petit et où une grande agrégation de gradient (GA) doit être activée, ou lorsque le nombre de nœuds est grand et un petit GA doit être utilisé. Excellentes performances d’entraînement.
- Dans une formation de 32 cartes, par rapport à la version de code directement obtenue de HuggingFace, Megatron-LLaMA peut atteindre 176 % d'accélération même avec la version optimisée par DeepSpeed et FlashAttention, Megatron-LLaMA peut encore réduire la vitesse ; d'au moins 19 % du temps de formation.
- Dans une formation à grande échelle, Megatron-LLaMA a une évolutivité presque linéaire par rapport à 32 cartes. Par exemple, en utilisant 512 A100 pour reproduire la formation de LLaMA-13B, le mécanisme inverse de Megatron-LLaMA peut gagner au moins deux jours par rapport au DistributedOptimizer du Megatron-LM natif sans aucune perte de précision.
- Megatron-LLaMA présente une haute tolérance à l'instabilité du réseau. Même sur le cluster de formation économique actuel 8xA100-80GB avec une bande passante de communication de 4x200Gbps (cet environnement est généralement un environnement de déploiement mixte, le réseau ne peut utiliser que la moitié de la bande passante, la bande passante du réseau constitue un sérieux goulot d'étranglement, mais le prix de location est relativement élevé). faible), Megatron-LLaMA peut encore atteindre une capacité d'expansion linéaire de 0,85, mais Megatron-LM ne peut atteindre que moins de 0,7 sur cet indicateur.
La technologie Megatron-LM offre des opportunités de formation LLaMA hautes performances
LLaMA est actuellement un travail important dans la grande communauté open source des modèles de langage. LLaMA introduit des technologies d'optimisation telles que le codage de caractères BPE, le codage de position RoPE, la fonction d'activation SwiGLU, la régularisation RMSNorm et l'intégration non liée dans la structure de LLM, et a obtenu d'excellents résultats dans de nombreuses évaluations objectives et subjectives. LLaMA propose des versions 7B, 13B, 30B, 65B/70B, qui conviennent à divers scénarios avec des exigences de modèle importantes et sont également privilégiées par les développeurs. Comme beaucoup d'autres grands modèles open source, étant donné que le responsable ne fournit que la version d'inférence du code, il n'existe pas de paradigme standard sur la manière de réaliser une formation efficace au moindre coût. Megatron-LM est une solution de formation élégante et performante. Megatron-LM fournit le parallélisme tensoriel (Tensor Parallel, TP, qui distribue de grandes multiplications sur plusieurs cartes pour le calcul parallèle), le parallélisme pipeline (Pipeline Parallel, PP, qui distribue différentes couches du modèle sur différentes cartes pour le traitement) et le parallélisme séquentiel ( Séquence parallèle). Parallèle, SP, différentes parties de la séquence sont traitées par différentes cartes, économisant ainsi la mémoire vidéo), optimisation DistributedOptimizer (similaire à DeepSpeed Zero Stage-2, division des gradients et des paramètres d'optimisation sur tous les nœuds informatiques) et d'autres technologies. peut réduire considérablement l'utilisation de la mémoire vidéo et améliorer l'utilisation du GPU. Megatron-LM exploite une communauté open source active, et de nouvelles technologies d'optimisation et conceptions fonctionnelles continuent d'être intégrées dans le cadre.
Cependant, le développement basé sur Megatron-LM n'est pas simple, en particulier le débogage et la vérification fonctionnelle sur des machines multi-cartes coûteuses sont très coûteuses. Megatron-LLaMA fournit d'abord un ensemble de codes de formation LLaMA basés sur le framework Megatron-LM, qui prend en charge des versions de modèles de différentes tailles et peut être facilement adapté pour prendre en charge diverses variantes de LLaMA, y compris Tokenizer qui prend directement en charge le format HuggingFace. Par conséquent, Megatron-LLaMA peut être facilement appliqué aux liens de formation hors ligne existants sans adaptation excessive. Dans le scénario de formation/mise au point à petite et moyenne échelle de LLaMA-7b et LLaMA-13b, Megatron-LLaMA peut facilement atteindre l'utilisation matérielle (MFU) de pointe de l'industrie de plus de 54 %
Megatron-LLaMA optimisation du processus inverse
Le contenu qui doit être réécrit est : Illustration : DeepSpeed ZeRO Stage-2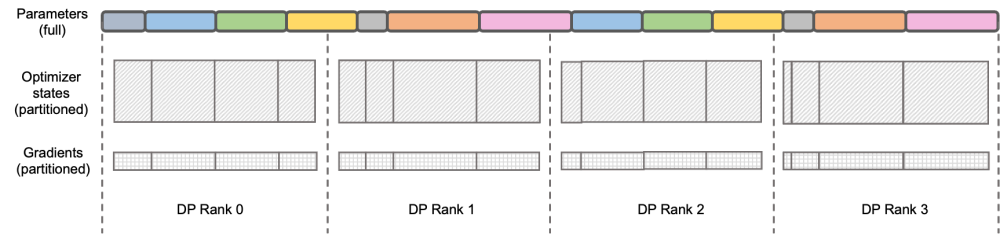
DeepSpeed ZeRO est un ensemble de frameworks de formation distribués lancés par Microsoft Les technologies proposées. en cela ont une influence très profonde sur de nombreux cadres ultérieurs. DeepSpeed ZeRO Stage-2 (ci-après dénommé ZeRO-2) est une technologie dans le cadre qui économise l'utilisation de la mémoire sans ajouter de charge de travail de calcul et de communication supplémentaire. Comme le montre la figure ci-dessus, en raison des exigences de calcul, chaque rang doit avoir tous les paramètres. Mais pour l’état de l’optimiseur, chaque Rang n’en est responsable que d’une partie, et il n’est pas nécessaire que tous les Rangs effectuent des opérations complètement répétées en même temps. Par conséquent, ZeRO-2 propose de diviser uniformément l'état de l'optimiseur dans chaque rang (notez qu'il n'est pas nécessaire de garantir que chaque variable est divisée de manière égale ou complètement conservée dans un certain rang). Chaque rang doit seulement être divisé pendant le processus de formation. . Responsable de la mise à jour de l'état de l'optimiseur et des paramètres du modèle de la pièce correspondante. Dans ce paramètre, les dégradés peuvent également être divisés de cette manière. Par défaut, ZeRO-2 utilise la méthode Réduire pour agréger les gradients entre tous les rangs à l'envers, puis chaque rang n'a besoin de conserver que la partie des paramètres dont il est responsable, ce qui non seulement élimine les calculs répétés redondants, mais réduit également la mémoire. utilisation.
Megatron-LM DistributedOptimizer
Native Megatron-LM implémente une segmentation d'état de gradient et d'optimisation de type ZeRO-2 via DistributedOptimizer pour réduire l'utilisation de la mémoire vidéo pendant l'entraînement. Comme le montre la figure ci-dessus, DistributedOptimizer utilise l'opérateur RéduireScatter pour distribuer tous les dégradés précédemment accumulés aux différents rangs après avoir obtenu tous les dégradés agrégés par le dégradé prédéfini. Chaque Rank n'obtient qu'une partie du gradient qu'il doit traiter, puis met à jour l'état de l'optimiseur et les paramètres correspondants. Enfin, chaque rang obtient les paramètres mis à jour des autres nœuds via AllGather et obtient enfin tous les paramètres. Les résultats réels de la formation montrent que la communication du gradient et des paramètres du Megatron-LM est effectuée en série avec d'autres calculs. Pour les tâches de pré-formation à grande échelle, afin de garantir que la taille totale des données du lot reste inchangée, il est généralement impossible de le faire. ouvrir une GA plus grande. Par conséquent, la proportion de communication augmentera avec l’augmentation du nombre de machines. À l’heure actuelle, les caractéristiques de la communication série conduisent à une très faible évolutivité. Au sein de la communauté, le besoin est également urgent
Megatron-LLaMA OverlappedDistributedOptimizer
Afin de résoudre ce problème, Megatron-LLaMA a amélioré le DistributedOptimizer du Megatron-LM natif pour le rendre plus efficace en communication par gradient. Les sous-capacités peuvent être parallélisées avec le calcul. En particulier, par rapport à la mise en œuvre de ZeRO, Megatron-LLaMA utilise une méthode de communication collective plus évolutive pour améliorer l'évolutivité grâce à une optimisation intelligente de la stratégie de partitionnement de l'optimiseur sous le principe du parallélisme. La conception principale d'OverlappedDistributedOptimizer garantit les points suivants : a) Le volume de données d'un seul opérateur de communication est suffisamment important pour utiliser pleinement la bande passante de communication. b) La quantité de données de communication requise par la nouvelle méthode de segmentation doit être égale au minimum ; volume de données de communication requis pour le parallélisme des données ; c) Pendant le processus de conversion de paramètres ou gradients complets et de paramètres ou gradients segmentés, un trop grand nombre de copies de mémoire vidéo ne peuvent pas être introduites.
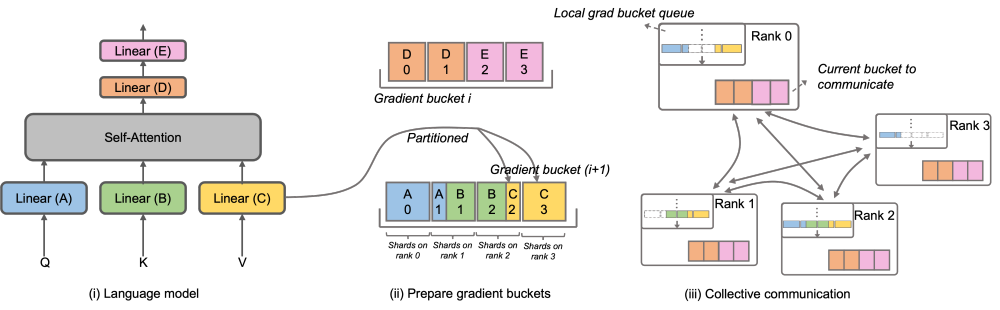
Plus précisément, Megatron-LLaMA a amélioré le DistributedOptimizer et a proposé OverlappedDistributedOptimizer, qui est utilisé pour optimiser la nouvelle méthode de segmentation dans le processus inverse de formation. Comme le montre la figure, lors de l'initialisation d'OverlappedDistributedOptimizer, tous les paramètres seront pré-attribués au bucket auquel ils appartiennent. Les paramètres de chaque Bucket sont complets. Un paramètre n'appartient qu'à un seul Bucket. Il peut y avoir plusieurs paramètres dans un Bucket. Logiquement, chaque bucket sera continuellement divisé en P parties (P est le nombre de groupes parallèles de données), et chaque rang du groupe parallèle de données sera responsable de l'une d'entre elles.
Le bucket est placé dans la file d'attente locale du bucket dégradé. pour assurer l’ordre des communications. Pendant que les calculs d'entraînement sont effectués, les groupes parallèles de données échangent leurs gradients requis en unités de seau via une communication collective. Dans Megatron-LLaMA, l'implémentation de Bucket utilise autant que possible l'indexation d'adresses, et un nouvel espace sera alloué uniquement lorsque la valeur doit être modifiée pour éviter de gaspiller de la mémoire vidéo
En combinant un grand nombre d'optimisations techniques, ce qui précède la conception permet un fonctionnement à grande échelle Lors d'une formation à grande échelle, Megatron-LLaMA peut utiliser pleinement le matériel et obtenir une meilleure accélération que le Megatron-LM natif. Dans un environnement réseau couramment utilisé, en élargissant l'échelle de formation de 32 cartes A100 à 512 cartes A100, Megatron-LLaMA peut toujours atteindre un taux d'expansion de 0,85
Les projets futurs de Megatron-LLaMA
Megatron-LLaMA est A Un cadre de formation open source conjoint par Taotian Group et Aicheng Technology et fournissant un support de maintenance de suivi a été largement utilisé en interne. Alors que de plus en plus de développeurs rejoignent la communauté open source de LLaMA et apportent des expériences qui peuvent être apprises les uns des autres, je pense qu'il y aura plus de défis et d'opportunités au niveau du cadre de formation à l'avenir. Megatron-LLaMA accordera une attention particulière au développement de la communauté et travaillera avec les développeurs pour promouvoir le développement dans les directions suivantes :
- Sélection de configuration optimale adaptative
- Support pour plus de structure de modèle ou de modifications de conception locales
- La solution ultime de formation aux performances dans des types d'environnements matériels plus différents
Adresse du projet : https://github.com/alibaba/Megatron-LLaMA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La chaîne industrielle de l'intelligence artificielle comprend
- Quels sont les domaines d'application de la technologie blockchain ?
- Quel est le concept de base de l'intelligence artificielle
- Quelles sont les applications de l'intelligence artificielle dans la vie ?
- Quelle est la technologie de base de l'Internet des objets