
Maison >Périphériques technologiques >IA >Gartner publie la courbe de maturité des technologies chinoises d'analyse de données et d'intelligence artificielle en 2023
Gartner publie la courbe de maturité des technologies chinoises d'analyse de données et d'intelligence artificielle en 2023

- PHPzavant
- 2023-09-14 15:37:10689parcourir
Gartner prédit que d’ici 2026, plus de 30 % des emplois de col blanc en Chine seront redéfinis et que les compétences nécessaires pour utiliser et gérer l’IA générative seront très populaires.
Le China Data Analytics and AI Technology Hype Cycle 2023 de Gartner révèle quatre thèmes fondamentaux liés aux données, à l'analyse et à l'IA en Chine : une stratégie de données chinoise qui donne la priorité aux résultats commerciaux, aux données et analyses régionales et à l'écosystème de l'IA, aux données, à l'effondrement de la Chine et de Taiwan, et l'intelligence artificielle devient un nouveau symbole de la puissance nationale.
Dans cette courbe, le plus grand nombre de technologies sont sur le point d'entrer dans une période d'expansion attendue. Zhang Tong, directeur de recherche principal chez Gartner, a déclaré : « L'innovation est souvent présentée comme une solution aux goulots d'étranglement traditionnels et devrait résoudre les préoccupations communes des DSI chinois, telles que le manque de ressources matérielles, l'évolutivité, les opérations durables, l'atténuation des risques de sécurité et les technologies. l'indépendance. le contrôle et l'applicabilité multi-domaines des modèles d'IA, ce qui se traduit par une valeur commerciale claire. Cependant, les utilisateurs finaux accordent plus d'importance aux impacts tangibles qu'aux concepts stratégiques abstraits. Le tissage de données est un cadre de conception permettant d'obtenir des pipelines de données, des services et une sémantique flexibles et réutilisables, impliquant l'intégration de données, des métadonnées actives, des graphiques de connaissances, le profilage des données, l'apprentissage automatique et la classification des données. Le tissage de données bouleverse l'approche dominante existante en matière de gestion des données. Il n'est plus « fait sur mesure » pour les données et les cas d'utilisation, mais « l'observation d'abord, puis l'utilisation ».
Zhang Tong, directeur de recherche senior chez Gartner, a déclaré : « L'émergence de cas d'utilisation des données, de l'analyse et de l'IA, ainsi que l'évolution rapide des réglementations en matière de sécurité des données, ont conduit à la complexité et à l'incertitude de la gestion des données en Chine. exploiter pleinement les coûts irrécupérables tout en fournissant des conseils sur la priorisation et le contrôle des coûts pour les nouvelles dépenses liées à l'infrastructure de gestion des données. aux opérations commerciales. La gestion des actifs de données s'applique à une variété de formes de données - par exemple, les images, les vidéos, les fichiers, les matériaux et les données de transaction dans le système, et couvre l'ensemble du cycle de vie des données, de l'acquisition des données à leur destruction. façon comme des actifs et en créer de la valeur. 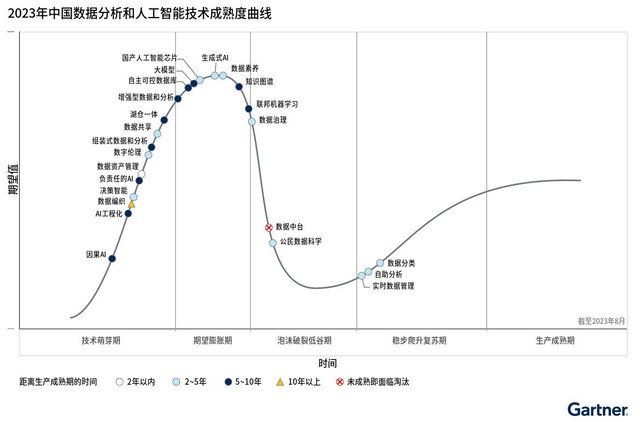
En tant que nouveau facteur de production, les données sont devenues un avantage concurrentiel pour les entreprises. Les données sont rapides, diversifiées, volumineuses et factuelles, les organisations doivent donc intégrer des processus pour générer des informations sur les données.
Zhang Tong, directeur de recherche senior chez Gartner, a déclaré : « Les actifs de données peuvent non seulement améliorer la qualité des opérations et de la prise de décision, mais également créer davantage de valeur commerciale. Ils peuvent également générer de nouveaux modèles commerciaux et utiliser les données pour monétiser directement. Cependant, même si la création de valeur s'accélère, les actifs de données comportent toujours des risques potentiels. Les entreprises doivent gérer soigneusement les actifs de données pour éviter les violations de la réglementation et les fuites accidentelles de données. des microservices basés sur des données ou des entreprises. Concepts d'architecture et de tissage de données qui rassemblent les actifs existants en capacités d'analyse de données et d'intelligence artificielle (IA) flexibles, modulaires et conviviales. Cette technologie peut utiliser une série de technologies pour transformer les applications de gestion et d'analyse de données en composants d'analyse de données et d'IA ou d'autres modules d'application, pris en charge par des capacités low-code et sans code, et prendre en charge une prise de décision adaptative et intelligente. Face à un environnement commercial en évolution rapide, les entreprises et institutions chinoises doivent améliorer leur agilité et accélérer la production d'informations. Assembled D&A aide les entreprises à utiliser des données modulaires et des capacités d'analyse pour intégrer plusieurs informations et informations de référence dans diverses mesures afin d'éviter un développement fragmenté. Les entreprises peuvent encore améliorer la flexibilité de livraison en rassemblant ou en réorganisant les capacités D&A pour faire face à différents scénarios d'utilisation. Grands modèlesLes grands modèles sont des modèles à grands paramètres formés de manière auto-supervisée sur un large éventail d'ensembles de données, dont la plupart sont basés sur l'architecture Transformer ou l'architecture de réseau neuronal profond de diffusion, et peuvent devenir multimodaux. Le nom Big Model vient de son importance et de sa large adéquation à une variété de scénarios d’utilisation en aval. Cette capacité d’adaptation à une variété de scénarios bénéficie d’un pré-entraînement suffisant et approfondi du modèle. Les grands modèles sont désormais devenus l'architecture privilégiée pour le traitement du langage naturel et ont été appliqués à la vision par ordinateur, au traitement audio et vidéo, au génie logiciel, à la chimie, à la finance et au droit. Un sous-concept populaire dérivé des grands modèles est celui des grands modèles de langage basés sur la formation de texte. Zhang Tong, directeur de recherche senior chez Gartner, a déclaré : « Les grands modèles ont le potentiel de fournir des effets améliorés pour les applications dans divers cas d'utilisation du langage naturel, et auront donc un impact profond dans les secteurs verticaux et les fonctions commerciales. productivité et permettre l'expérience client Automatisez, augmentez et créez de nouveaux produits et services de manière rentable, accélérant ainsi la transformation numérique.Data Middle Office
Data Middle Office (DMO) est une pratique de stratégie organisationnelle et de technologie. Grâce au centre de données, les utilisateurs de différents secteurs d'activité peuvent utiliser efficacement les données de l'entreprise pour prendre des décisions basées sur une source unique de vérité. La création d'un centre de données peut être un moyen de créer des capacités d'analyse et de données assemblables et réutilisables pour les entreprises. Ces capacités peuvent fournir des opérations numériques uniques et intégrer les opérations numériques tout au long de la chaîne de valeur via la pile technologique.
La raison pour laquelle de nombreuses entreprises chinoises adoptent des pratiques de données intermédiaires est de réduire la redondance technique de leur architecture de données et d'analyse, d'ouvrir des îlots de données de différents systèmes et de promouvoir des capacités de données et d'analyse réutilisables. Cependant, dans de nombreux cas, le centre de données n’a pas tenu sa promesse de capacités D&A agiles assemblées, et sa position sur le marché a donc été affaiblie. De nombreuses organisations et fournisseurs hésitent à adopter ce concept en interne, ou tout simplement à le supprimer de leur promotion.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que l'éducation à l'intelligence artificielle ?
- Quels sont les principaux moteurs du développement de l'intelligence artificielle ?
- Quelles sont les applications de l'intelligence artificielle dans la vie ?
- Selon les définitions scientifiques populaires, l'intelligence artificielle est un programme informatique semblable aux humains.
- Comment s'appelle l'assistant d'intelligence artificielle de Honor ?