
Maison >Périphériques technologiques >IA >Implémenter la génération d'améliorations de recherche basée sur Langchain, ChromaDB et GPT 3.5
Implémenter la génération d'améliorations de recherche basée sur Langchain, ChromaDB et GPT 3.5

- 王林avant
- 2023-09-14 14:21:111743parcourir
Traducteur | Zhu Xianzhong
Chong Lou | Reviewer
Abstract:Dans ce blog, nous découvrirons une méthode appelée récupération de génération augmentée invite technologie d'ingénierie et seront basés sur une combinaison de Langchain, ChromaDB et GPT 3.5 pour mettre en œuvre cette technologie .
Motivation
Avec l'émergence de modèles big data basés sur des transformateurs tels que GPT-3, le domaine du traitement du langage naturel (NLP) a réalisé des percées majeures. Ces modèles de langage sont capables de générer du texte de type humain et disposent déjà d'une variété d'applications telles que des chatbots, la génération et la traduction de contenu etc. Cependant, lorsqu'il s'agit de scénarios d'application d'informations spécialisées et spécifiques au client, les modèles de langage traditionnels peuvent ne pas répondre aux exigences. D'un autre côté, affiner ces modèles à l'aide de nouveaux corpus peut être coûteux et prendre du temps. Pour relever ce défi, nous pouvons utiliser une technique appelée Retrieval Augmented Generation (RAG : Retrieval Augmented Generation).
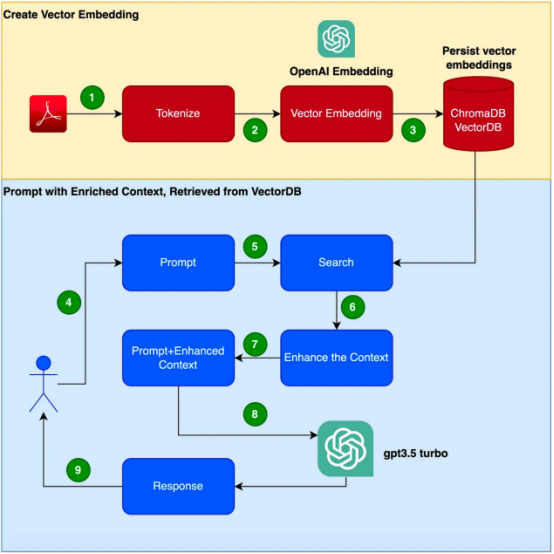
comment fonctionne cette Retrieval Enhanced Generation (RAG) , et passez une vraie vie Des battleexemples sont utilisés pour prouver l'efficacité de cette technologie. Il est à noter que cet exemple utilisera GPT-3.5 Turbo comme corpus supplémentaire pour répondre au manuel du produit. Imaginez que vous soyez chargé de développer un chatbot qui
peut répondre aux requêtes sur un produit spécifique. Le produit dispose de son propre manuel d’utilisation, spécifiquement destiné aux produits d’entreprise. Les modèles de langage traditionnels, tels que GPT-3, sont souvent formés sur des données générales et peuvent ne pas comprendre ce produit spécifique.D'un autre côté, affiner le modèle à l'aide d'un nouveau corpus semble être une solution cependant, cette approche entraînera des coûts et des besoins en ressources considérables ; Introduction à la génération augmentée par récupération (RAG) La génération augmentée par récupération (RAG) offre un moyen plus efficace de résoudre le problème de la génération de réponses contextuelles appropriées dans un domaine spécifique. Plutôt que d'utiliser un nouveau corpus pour affiner l'ensemble du modèle linguistique, RAG utilise la puissance de la récupération pour accéder aux informations pertinentes à la demande. En combinant des mécanismes de récupération avec des modèles de langage, RAG exploite le contexte externe pour améliorer les réponses. Ce contexte externe peut être fourni sous forme d'intégration vectorielle
Les étapes ci-dessous sont indiquées pour créer l'
application dans cet article.Il est à noter que dans cet exemple, nous utiliserons le manuel d'utilisation Focusrite Clarett comme corpus supplémentaire. Focusrite Clarett est une interface audio USB simple pour l'enregistrement et la lecture audio. Vous pouvez le télécharger à partir du lien https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett%208Pre%20USB%20User%20Guide%20V2%20English%20-%20EN.pdf Manuel d'utilisation. Créons un environnement virtuel pour encapsuler notre cas de mise en œuvre afin d'éviter qui peut se produire dans le système Conflit de version/bibliothèque/dépendance. Maintenant, nous exécutons la commande suivante pour créer un nouvel environnement virtuel Python : . Après votre inscription, connectez-vous et sélectionnez l'option API comme indiqué dans la capture d'écran (En raison du timing, lorsque vous ouvrez cette peut ne pas correspondre moi Actuellement prendre des captures d'écran avec modifications). Ensuite, allez dans les paramètres de votre compte et sélectionnez "Afficher les clés API": Ensuite, sélectionnez "Créer une nouvelle clé" ", vous verrez une fenêtre pop-up comme indiqué ci-dessous. Vous devez fournir un nom et cela générera une clé. Cette action générera une clé unique que vous devrez copier dans votre presse-papiers et stocker dans un . Ensuite , écrivons du code Python pour implémenter toutes les étapes indiquées dans l'organigramme ci-dessus. Installer les bibliothèques de dépendancesTout d'abord, 一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。 接下来,让我们开始编程。 在下面的代码中,我们会引入所有需要使用的依赖库和函数 在下面的代码中,阅读PDF,将文档标记化并拆分为标记。 在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。 执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。 现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。 既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。 这是输出的屏幕截图。 正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。 朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵 原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
Exercice pratique
Mettre en place un environnement virtuel
pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
Créer la clé OpenAI Ensuite, 
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
export OPENAI_API_KEY=<openai-key></openai-key>
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])

小结
译者介绍
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle science est le traitement du langage naturel ?
- Comment utiliser le langage Go pour le développement du traitement du langage naturel ?
- Utilisez la programmation Python pour implémenter l'accueil de l'interface de traitement du langage naturel Baidu afin de vous aider à développer des programmes de traitement intelligents.
- Techniques de traitement du langage naturel en C++
- Comment faire de l'interaction homme-machine et du traitement du langage naturel en C++ ?