
Maison >Périphériques technologiques >IA >Annonce des prix VLDB 2023, un article conjoint de l'Université Tsinghua, 4Paradigm et NUS a remporté le prix du meilleur papier industriel
Annonce des prix VLDB 2023, un article conjoint de l'Université Tsinghua, 4Paradigm et NUS a remporté le prix du meilleur papier industriel

- 王林avant
- 2023-09-14 10:01:01772parcourir
La conférence internationale VLDB 2023 s'est tenue avec succès à Vancouver, au Canada. La conférence VLDB est l'une des trois principales conférences ayant une longue histoire dans le domaine des bases de données. Son nom complet est la Conférence internationale sur les bases de données à grande échelle. Chaque conférence se concentre sur l'affichage des orientations de pointe actuelles de la recherche sur les bases de données, des dernières technologies de l'industrie et des niveaux de R&D de divers pays, attirant des soumissions des plus grandes institutions de recherche du monde.

La conférence se concentre sur l'innovation des systèmes, exhaustivité et conception expérimentale Il existe des exigences extrêmement élevées dans d'autres aspects. Le taux d'acceptation des articles du VLDB est généralement faible, environ 18 %. Seuls les articles avec de grandes contributions sont susceptibles d'être acceptés. La concurrence est encore plus féroce cette année. Selon les données officielles, un total de 9 articles du VLDB ont remporté le prix du meilleur article cette année, notamment ceux de l'Université de Stanford, de l'Université Carnegie Mellon, de Microsoft Research, de VMware Research, de Meta et d'autres universités, instituts de recherche et géants de la technologie de renommée mondiale. Parmi eux, l'article « FEBench : A Benchmark for Real-Time Relational Data Feature Extraction » réalisé conjointement par 4Paradigm, l'Université Tsinghua et l'Université nationale de Singapour a remporté le prix final du meilleur article industriel.
 Cet article est une collaboration entre 4Paradigm, l'Université Tsinghua et l'Université nationale de Singapour. Le document propose un test de test de calcul de fonctionnalités en temps réel basé sur l'accumulation de scénarios réels dans l'industrie, qui est utilisé pour évaluer les systèmes de prise de décision en temps réel basés sur l'apprentissage automatique. Veuillez cliquer sur le lien suivant pour consulter le document : https. ://github.com/decis -bench/febench/blob/main/report/febench.pdf
Cet article est une collaboration entre 4Paradigm, l'Université Tsinghua et l'Université nationale de Singapour. Le document propose un test de test de calcul de fonctionnalités en temps réel basé sur l'accumulation de scénarios réels dans l'industrie, qui est utilisé pour évaluer les systèmes de prise de décision en temps réel basés sur l'apprentissage automatique. Veuillez cliquer sur le lien suivant pour consulter le document : https. ://github.com/decis -bench/febench/blob/main/report/febench.pdf
Adresse du projet : https://github.com/decis-bench/febench
Le contenu qui doit être réécrit est : L'adresse du projet est https://github.com/decis-bench/febench
Contexte du projet
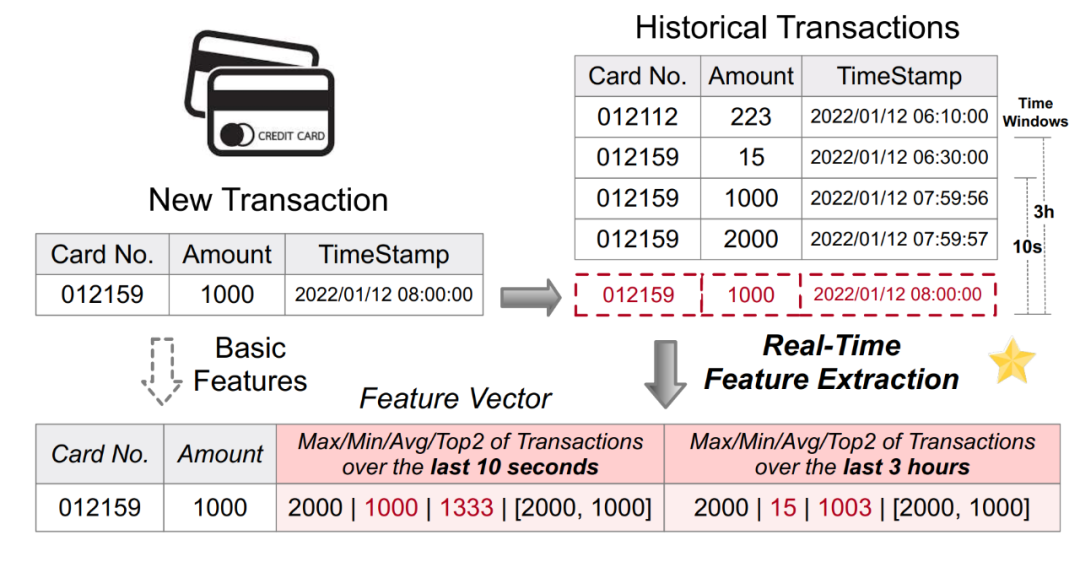
- Les systèmes de prise de décision basés sur l'intelligence artificielle sont largement utilisés dans de nombreuses industries scénarios. Parmi eux, de nombreux scénarios impliquent des calculs basés sur des données en temps réel, comme la lutte contre la fraude dans le secteur financier et les recommandations en ligne en temps réel dans le secteur de la vente au détail. Les systèmes de prise de décision en temps réel pilotés par l’apprentissage automatique comprennent généralement deux liens informatiques principaux : les fonctionnalités et les modèles. En raison de la diversité des logiques métier et des exigences de faible latence et de concurrence élevée en ligne, le calcul des fonctionnalités devient souvent le goulot d'étranglement de l'ensemble du système décisionnel. Par conséquent, beaucoup de pratique d’ingénierie est nécessaire pour créer une plateforme de calcul de caractéristiques en temps réel disponible, stable et efficace. La figure 1 ci-dessous montre un scénario courant de calcul de fonctionnalités en temps réel pour les applications antifraude. En effectuant des calculs de fonctionnalités basés sur le tableau d'enregistrement des transactions par carte de crédit d'origine, de nouvelles fonctionnalités (telles que le montant maximum/minimum/moyen de la carte de crédit au cours des 10 dernières secondes, etc.) sont générées, puis saisies dans le modèle en aval pour de vrai. inférence temporelle
Contenu réécrit : Figure 1. Application du calcul de caractéristiques en temps réel dans les applications antifraude
De manière générale, une plateforme de calcul de caractéristiques en temps réel doit répondre aux deux exigences de base suivantes :
Efficacité des services en ligne : les services en ligne visent les données et les calculs en temps réel, répondant aux besoins de faible latence, de simultanéité élevée et de haute disponibilité.
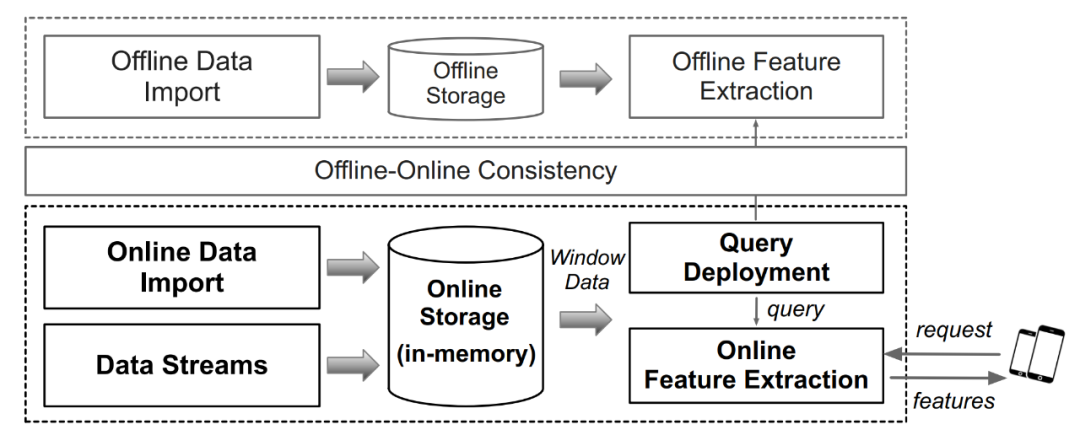
- Figure 2. Architecture et flux de travail de la plate-forme de calcul de caractéristiques en temps réel Comme le montre la figure 2 ci-dessus, l'architecture d'une plate-forme commune de calcul de caractéristiques en temps réel est répertoriée. En termes simples, il comprend principalement les moteurs informatiques hors ligne et les moteurs informatiques en ligne. Le point clé est d'assurer la cohérence de la logique informatique entre les moteurs informatiques hors ligne et en ligne. Il existe actuellement de nombreuses plates-formes de fonctionnalités sur le marché qui peuvent répondre aux exigences ci-dessus et former une plate-forme complète de calcul de fonctionnalités en temps réel, y compris des systèmes à usage général tels que Flink ou des systèmes spécialisés tels que OpenMLDB, Tecton, Feast, etc. Cependant, l’industrie manque actuellement d’un référentiel dédié orienté vers les caractéristiques en temps réel pour mener une évaluation rigoureuse et scientifique des performances de tels systèmes. En réponse à cette demande, l'auteur de cet article a créé FEBench, un test de référence de calcul de fonctionnalités en temps réel, pour évaluer les performances de la plate-forme de calcul de fonctionnalités et analyser la latence globale, la latence longue traîne et les performances de concurrence du système.
 Principe technique
Principe technique
La construction de référence de FEBench comprend principalement trois aspects du travail : la collecte d'ensembles de données, le contenu généré par la requête doit être réécrit et lorsque le contenu est réécrit, les modèles appropriés doivent être sélectionnés
Collecte d'ensembles de données
L'équipe de recherche a collecté un total de 118 ensembles de données qui peuvent être utilisés dans des scénarios de calcul de caractéristiques en temps réel. Ces ensembles de données proviennent de sites Web de données publics tels que Kaggle, Tianchi, UCI ML, KiltHub et. données publiques internes au sein de Fourth Paradigm, couvrant des scénarios d'utilisation typiques dans le monde industriel, tels que la finance, la vente au détail, la médecine, la fabrication, les transports et d'autres scénarios industriels. L'équipe de recherche a en outre classé les ensembles de données collectés en fonction du nombre de tableaux et de la taille de l'ensemble de données, comme le montre la figure 3 ci-dessous.
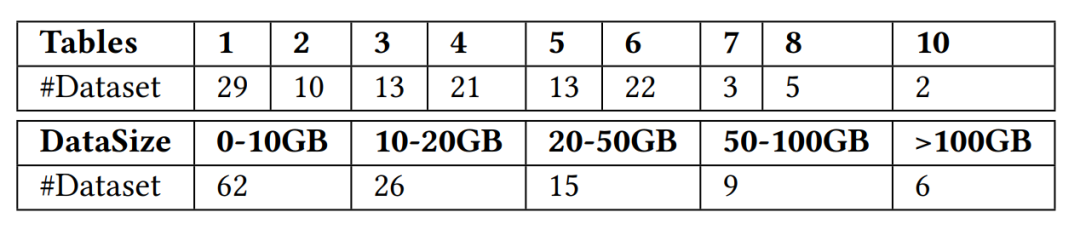
Contenu réécrit : Le graphique du nombre de tables et de la taille de l'ensemble de données dans FEBench est le suivant :
Le contenu généré par la requête doit être réécrit
En raison de la grande nombre d'ensembles de données, pour chaque donnée La charge de travail de la logique informatique liée à l'extraction de caractéristiques générée manuellement est très énorme, c'est pourquoi les chercheurs ont utilisé des technologies d'apprentissage automatique telles qu'AutoCross (document de référence : AutoCross : Automatic Feature Crossing for Tabular Data in Real-World Applications) pour fournir les données collectées, Set génère automatiquement des requêtes. La sélection des fonctionnalités de FEBench et le contenu généré par les requêtes doivent être réécrits, ce qui comprend les quatre étapes suivantes (comme le montre la figure 4 ci-dessous) :
En identifiant la table principale (stockant les données de streaming) et les tables auxiliaires (telles que les tables statiques/ Table d'ajout/instantané) peut être initialisée. Par la suite, les colonnes portant des noms ou des relations clés similaires dans les tables primaires et secondaires sont analysées, et les relations un-à-un/un-à-plusieurs entre les colonnes sont énumérées, ce qui correspond à différents modes de fonctionnement des fonctionnalités.
Mappez les relations des colonnes avec les opérateurs de fonctionnalités.
Après avoir extrait toutes les fonctionnalités candidates, l'algorithme de recherche Beam est utilisé pour générer de manière itérative un ensemble de fonctionnalités efficace.
Les fonctionnalités sélectionnées sont converties en requêtes SQL sémantiquement équivalentes.
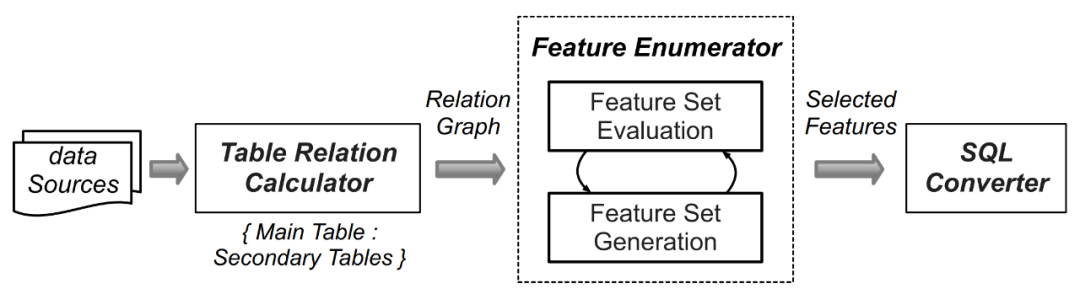
Figure 4. Processus de génération de requête dans FEBench
Lors de la réécriture du contenu, vous devez choisir un modèle approprié
Après avoir généré la requête pour chaque ensemble de données, les chercheurs ont ensuite utilisé l'algorithme de clustering pour sélectionnez des requêtes représentatives comme modèles de requête pour réduire les tests répétés de tâches similaires. Pour les 118 ensembles de données et requêtes de fonctionnalités collectés, utilisez l'algorithme DBSCAN pour regrouper ces requêtes. Les étapes spécifiques sont les suivantes :
Divisez les fonctionnalités de chaque requête en cinq parties : le nombre de colonnes de sortie, le nombre total de. opérateurs de requête, la fréquence d'occurrence des opérateurs complexes, le nombre de niveaux de sous-requêtes imbriqués et le nombre maximum de tuples dans la fenêtre temporelle. Étant donné que les requêtes d'ingénierie de fonctionnalités impliquent généralement des fenêtres temporelles et que la complexité des requêtes n'est pas affectée par la taille des données par lots, la taille de l'ensemble de données n'est pas incluse comme l'une des fonctionnalités de clustering.
Utilisez un modèle de régression logistique pour évaluer la relation entre les fonctionnalités de requête et les caractéristiques d'exécution de la requête, en utilisant les fonctionnalités comme entrée du modèle et le temps d'exécution de la requête de fonctionnalité comme sortie du modèle. L'importance des différentes fonctionnalités sur les résultats de clustering est prise en compte en utilisant le poids de régression de chaque fonctionnalité comme poids de clustering
Sur la base des fonctionnalités de requête pondérées, l'algorithme DBSCAN est utilisé pour diviser la requête de fonctionnalités en plusieurs clusters.
Le graphique suivant montre la répartition de 118 ensembles de données selon divers indicateurs de considération. La figure (a) montre les indicateurs de nature statistique, y compris le nombre de colonnes de sortie, le nombre total d'opérateurs de requête et le nombre de niveaux de sous-requêtes imbriqués. La figure (b) montre les indicateurs ayant la plus forte corrélation avec le temps d'exécution de la requête, y compris le nombre d'opérations d'agrégation, nombre de niveaux de sous-requêtes imbriqués et nombre de fenêtres temporelles
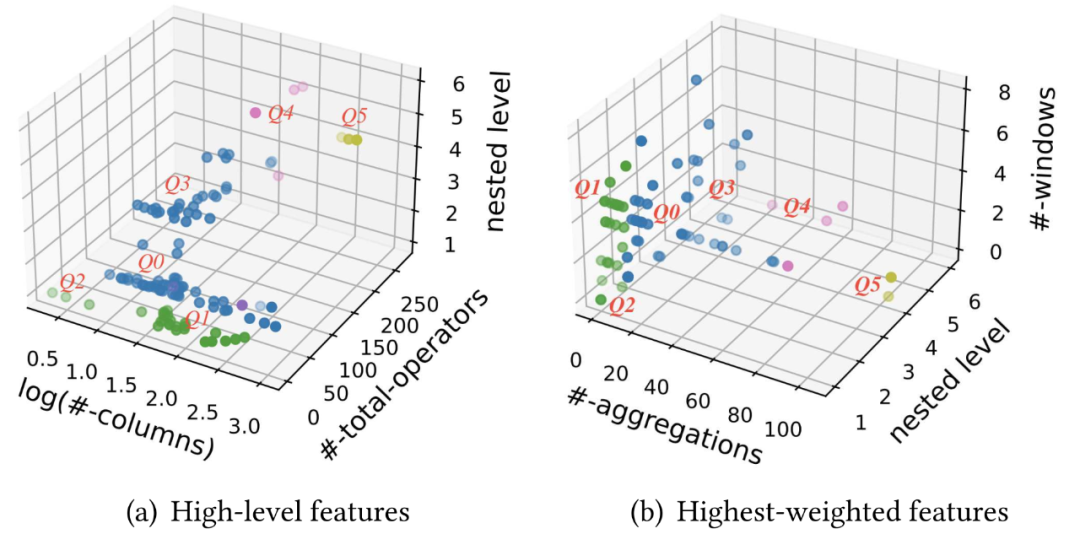
Figure 5. 118 requêtes de fonctionnalités ont obtenu 6 clusters grâce à l'analyse de cluster et des modèles de requêtes (Q0-5) ont été générés
Enfin, selon aux résultats du clustering, j'ai divisé les 118 requêtes de fonctionnalités en 6 clusters. Pour chaque cluster, les requêtes proches du centroïde sont sélectionnées comme modèles candidats. De plus, étant donné que les applications d'intelligence artificielle dans différents scénarios d'application peuvent avoir des exigences d'ingénierie de fonctionnalités différentes, essayez de sélectionner des requêtes de différents scénarios autour du centroïde de chaque cluster pour mieux couvrir différents scénarios d'ingénierie de fonctionnalités. Enfin, 6 modèles de requêtes ont été sélectionnés parmi 118 requêtes de fonctionnalités, adaptées à différents scénarios, notamment les transports, les soins de santé, l'énergie, les ventes et les transactions financières. Ces six modèles de requêtes constituent en fin de compte les ensembles de données et les requêtes de base de FEBench, qui sont utilisés pour tester les performances de la plateforme de calcul de fonctionnalités en temps réel.
Ce qui doit être réécrit, c'est : Évaluation de référence (OpenMLDB et Flink)
Dans l'étude, les chercheurs ont utilisé FEBench pour tester deux systèmes industriels typiques, à savoir Flink et OpenMLDB. Flink est une plate-forme informatique générale de cohérence du traitement par lots et par flux, tandis qu'OpenMLDB est une plate-forme informatique dédiée aux fonctionnalités en temps réel. Grâce à des tests et des analyses, les chercheurs ont découvert les avantages et les inconvénients de chaque système ainsi que les raisons qui les sous-tendent. Les résultats expérimentaux montrent qu'en raison de conceptions architecturales différentes, il existe des différences de performances entre Flink et OpenMLDB. Dans le même temps, cela illustre également l'importance de FEBench dans l'analyse des capacités du système cible. En résumé, les principales conclusions de l'étude sont les suivantes
Flink est deux ordres de grandeur plus lent qu'OpenMLDB en termes de latence (Figure 6). Les chercheurs ont analysé que la principale raison de cet écart réside dans les différentes méthodes de mise en œuvre des deux architectures système. OpenMLDB, en tant que système dédié au calcul de caractéristiques en temps réel, comprend des tables de sauts à double couche basées sur la mémoire et d'autres structures de données optimisées pour le temps. données de série. En fin de compte, par rapport à Flink, il présente des avantages évidents en termes de performances dans les scénarios de calcul de fonctionnalités. Bien entendu, en tant que système à usage général, Flink propose une gamme de scénarios applicables plus large qu'OpenMLDB.
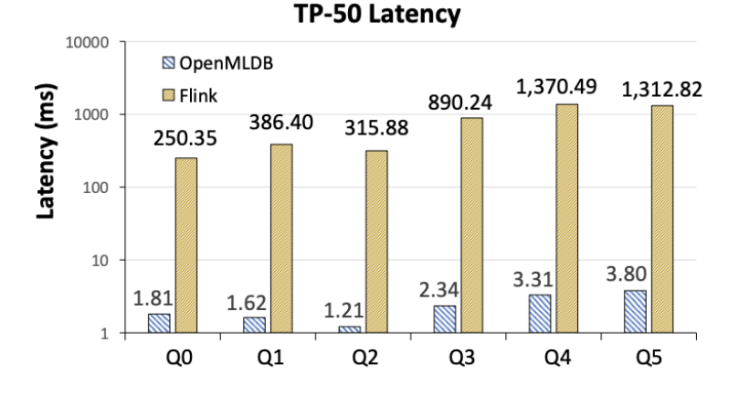
Figure 6. Comparaison de latence TP-50 entre OpenMLDB et Flink
OpenMLDB présente des problèmes évidents de latence de longue traîne, tandis que la latence de queue de Flink est plus stable (Figure 7). Notez que les chiffres suivants montrent les performances de latence normalisées par rapport au TP-50 respectif d'OpenMLDB et de Flink, et ne représentent pas des comparaisons de performances absolues. Réécrit comme suit : OpenMLDB a des problèmes évidents avec la latence de queue, tandis que la latence de queue de Flink est plus stable (voir Figure 7). Il convient de noter que les chiffres suivants normalisent les performances de latence par rapport aux performances d'OpenMLDB et de Flink sous TP-50 respectivement, plutôt qu'une comparaison des performances absolues
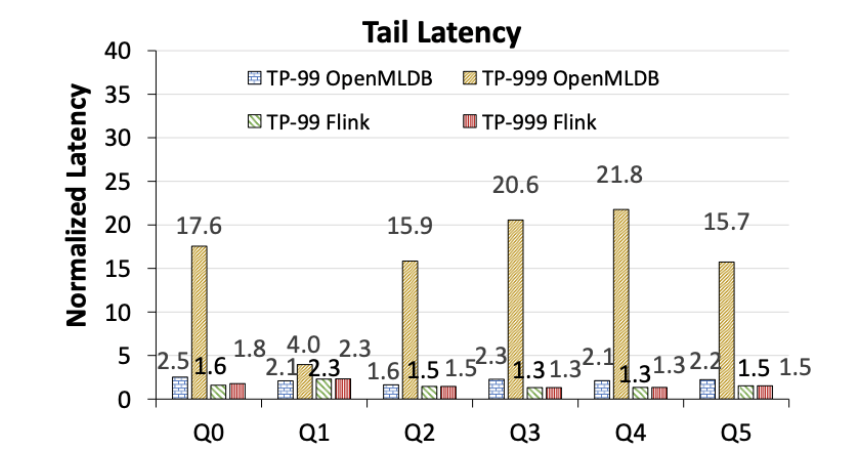
Figure 7. La fin d'OpenMLDB et de Flink Comparaison de latence (normalisée à la latence respective du TP-50)
Les chercheurs ont mené une analyse plus approfondie des résultats de performances ci-dessus :
Analyse de démontage basée sur le temps d'exécution, les indicateurs micro-architecturaux incluent l'achèvement des instructions, les erreurs Prédiction de branche, retour -dépendances finales, dépendances frontales, etc. Différents modèles de requêtes présentent différents goulots d'étranglement en termes de performances au niveau de la microstructure. Comme le montre la figure 8, le goulot d'étranglement des performances de Q0 à Q2 dépend principalement du front-end, représentant plus de 45 % de la durée d'exécution totale. Dans ce cas, les opérations effectuées sont relativement simples et la plupart du temps est consacré au traitement des demandes des utilisateurs et à la commutation entre les instructions d'extraction de fonctionnalités. Pour les troisième et cinquième trimestres, les dépendances du backend (telles que l'invalidation du cache) et l'exécution des instructions (y compris les instructions plus complexes) deviennent des facteurs plus importants. OpenMLDB améliore encore ses performances grâce à une optimisation ciblée
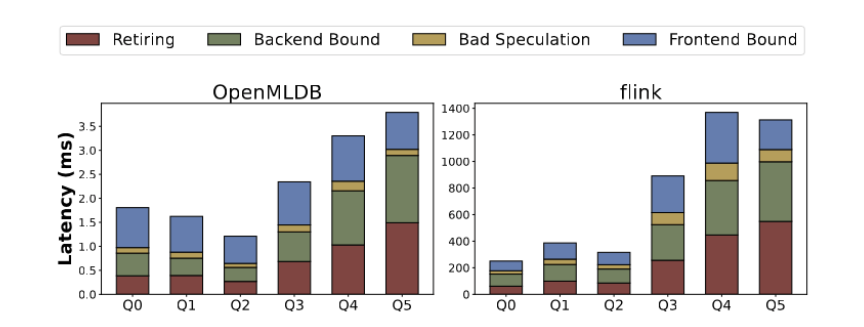
La figure 8 montre l'analyse des indicateurs de microarchitecture d'OpenMLDB et de Flink
Analyse du plan d'exécution : en prenant Q0 comme exemple, comparez la figure 9 ci-dessous. Comprendre le différences dans les plans d'exécution entre Flink et OpenMLDB. Les opérateurs informatiques dans Flink prennent le plus de temps, tandis qu'OpenMLDB réduit la latence d'exécution en optimisant le fenêtrage et en utilisant des techniques d'optimisation telles que des fonctions d'agrégation personnalisées.
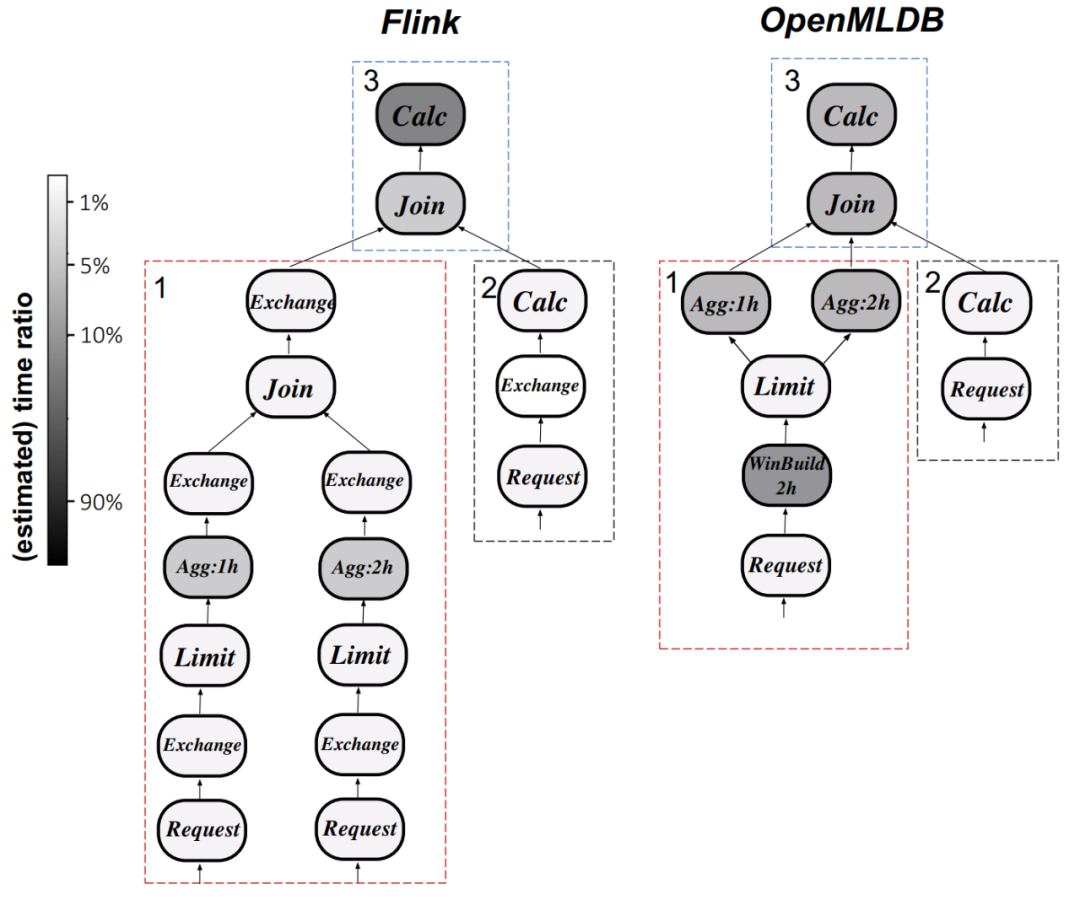
La neuvième image montre la comparaison entre OpenMLDB et Flink en termes de plan d'exécution (Q0)
Si l'utilisateur espère reproduire les résultats expérimentaux ci-dessus, ou effectuer des tests de référence sur le système local (le auteur de l'article (les résultats des tests sont également encouragés à être soumis et partagés dans la communauté), vous pouvez visiter la page d'accueil du projet FEBench pour plus d'informations.
Projet FEBench : https://github.com/decis-bench/febench
Projet Flink : https://github.com/apache/flink
Projet OpenMLDB : https://github .com/4paradigm/OpenMLDB
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les dix meilleurs outils de développement que les ingénieurs de développement PHP apprécient le plus
- Étapes détaillées pour créer un nouveau projet C++ complet dans VS2015
- Que fait un ingénieur de maintenance des données ?
- Que fait principalement un ingénieur PHP ?
- Explication détaillée de la façon de déboguer les projets Golang dans VSCode