Cet article propose une méthode OPRO simple et efficace, qui utilise un grand modèle de langage comme optimiseur. La tâche d'optimisation peut être décrite en langage naturel, ce qui est meilleur que les invites conçues par les humains.
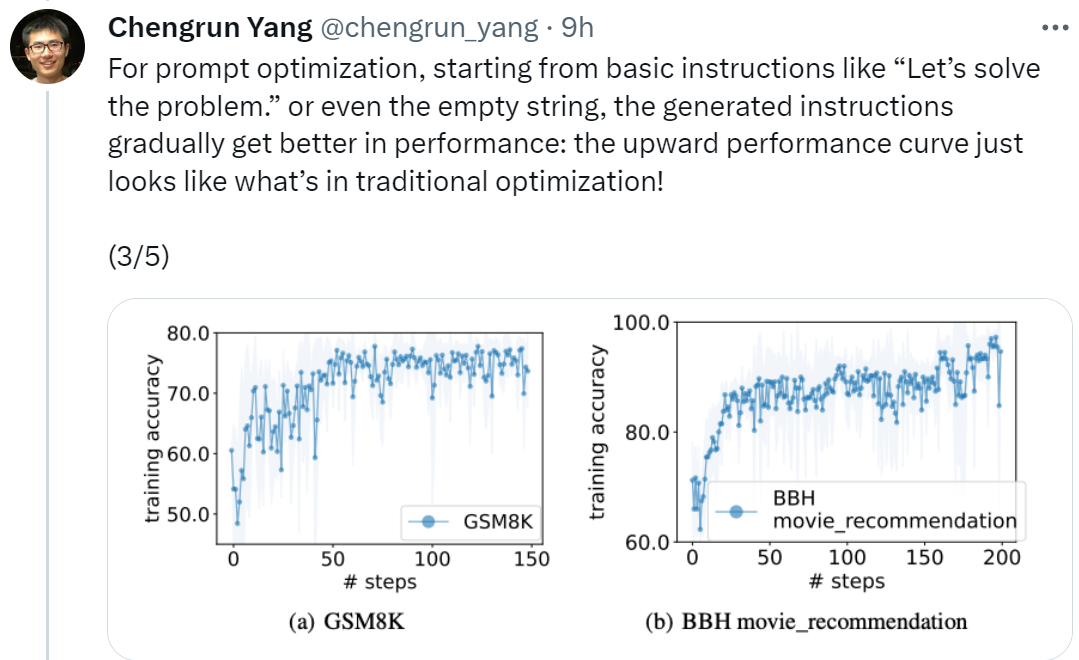
L'optimisation est cruciale dans tous les domaines. Certaines optimisations commencent par l'initialisation puis mettent à jour de manière itérative la solution pour optimiser la fonction objectif. De tels algorithmes d'optimisation doivent souvent être personnalisés pour des tâches individuelles afin de relever les défis spécifiques posés par l'espace de décision, en particulier pour l'optimisation sans dérivées. Dans l'étude que nous allons présenter ensuite, les chercheurs ont adopté une approche différente. Ils ont utilisé de grands modèles de langage (LLM) pour agir comme optimiseurs et ont obtenu de meilleurs résultats que les astuces conçues par l'homme sur diverses tâches. Cette recherche provient de Google DeepMind. Ils ont proposé une méthode d'optimisation simple et efficace OPRO (Optimization by PROmpting), dans laquelle la tâche d'optimisation peut être décrite en langage naturel. Par exemple, l'invite de LLM peut être "Take". une respiration profonde, résolvez ce problème étape par étape", ou cela pourrait être "Combinons nos commandes numériques et notre pensée claire pour déchiffrer la réponse rapidement et avec précision" et ainsi de suite. À chaque étape d'optimisation, LLM génère une nouvelle solution basée sur les indices des solutions générées précédemment et leurs valeurs, puis évalue la nouvelle solution et l'ajoute à l'invite de l'étape d'optimisation suivante. Enfin, l'étude applique la méthode OPRO à la régression linéaire et au problème du voyageur de commerce (le fameux problème NP), puis procède à l'optimisation des invites, dans le but de trouver des instructions qui maximisent la précision des tâches. Cet article effectue une évaluation complète de plusieurs LLM, notamment text-bison et Palm 2-L dans la famille de modèles PaLM-2, et gpt-3.5-turbo et gpt-4 dans la famille de modèles GPT. L'expérience a optimisé les invites sur GSM8K et Big-Bench Hard. Les résultats montrent que les meilleures invites optimisées par OPRO sont 8 % plus élevées que les invites conçues manuellement sur GSM8K et sont supérieures aux invites conçues manuellement sur la tâche Big-Bench Hard. Sortie jusqu'à 50%. « Afin d'effectuer optimisation rapide, nous sommes partis de "Commençons" En commençant par des instructions de base comme "Résoudre le problème", ou même une chaîne vide, les instructions générées par OPRO amélioreront progressivement les performances du LLM. La courbe de performances ascendante illustrée dans la figure ci-dessous. ressemble à la situation de l'optimisation traditionnelle ! " 
"Même si chaque LLM part de la même instruction, après optimisation par OPRO, les instructions finales optimisées des différents LLM affichent également des styles différents, qui sont meilleurs que les instructions écrites par les humains, et peuvent être transférés à des tâches similaires. "Nous pouvons également conclure du tableau ci-dessus que les styles d'instructions finalement trouvés par LLM en tant qu'optimiseur sont très différents. Les instructions de PaLM 2-L- L'informatique et le texte-bison sont plus concis, tandis que les instructions de GPT Les instructions étaient longues et détaillées. Bien que certaines instructions de niveau supérieur contiennent des invites « étape par étape », OPRO peut trouver d'autres expressions sémantiques et atteindre une précision comparable ou meilleure.
Cependant, certains chercheurs ont dit : « Respirez profondément et procédez étape par étape ». Cette astuce est très efficace sur le PaLM-2 de Google (taux de précision 80,2). Mais nous ne pouvons pas garantir qu’il fonctionne sur tous les modèles et dans toutes les situations, il ne faut donc pas l’utiliser aveuglément partout.
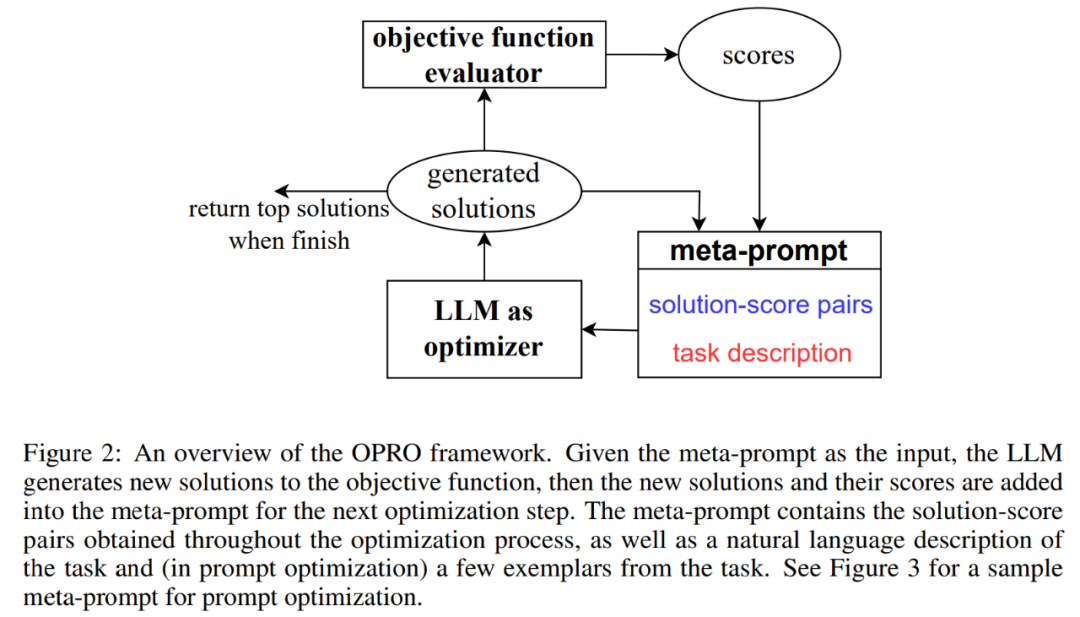
OPRO : LLM comme optimiseurLa figure 2 montre le cadre global d'OPRO. À chaque étape d'optimisation, LLM génère des solutions candidates à la tâche d'optimisation sur la base de la description du problème d'optimisation et des solutions précédemment évaluées dans la méta-invite (partie inférieure droite de la figure 2). Ensuite, LLM évalue les nouvelles solutions et les ajoute aux méta-conseils pour le processus d'optimisation ultérieur. Le processus d'optimisation prend fin lorsque LLM ne parvient pas à proposer une nouvelle solution avec un meilleur score d'optimisation ou atteint le nombre maximum d'étapes d'optimisation.
La figure 3 montre un exemple. Les méta-indices contiennent deux contenus principaux : la première partie est constituée des indices générés précédemment et de leur précision de formation correspondante ; la deuxième partie est la description du problème d'optimisation, comprenant plusieurs exemples sélectionnés au hasard dans l'ensemble de formation pour illustrer la tâche d'intérêt.
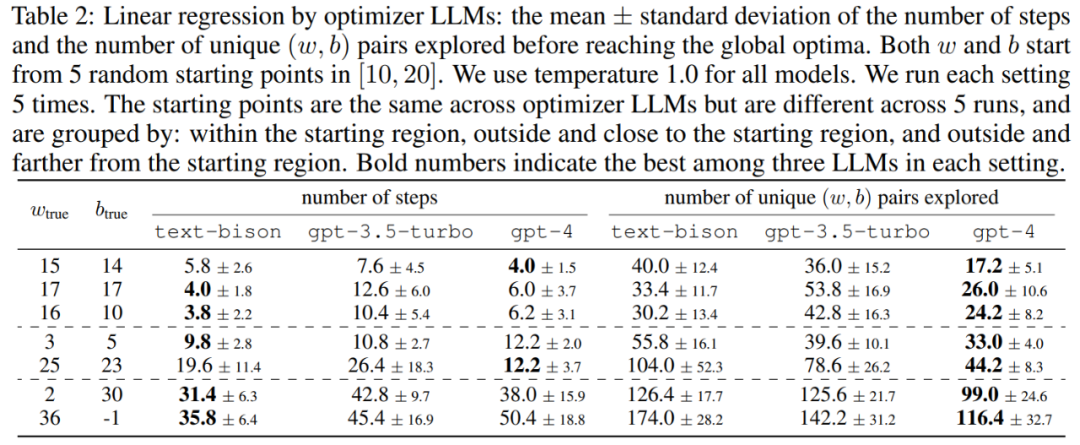
Cet article démontre d'abord le potentiel du LLM en tant qu'optimiseur « d'optimisation mathématique ». Les résultats du problème de régression linéaire sont présentés dans le tableau 2 :
Ensuite, l'article explore également les résultats de l'OPRO sur le problème du voyageur de commerce (TSP). Plus précisément, TSP fait référence à un ensemble donné. de n nœuds et leurs coordonnées, la tâche TSP est de trouver le chemin le plus court en partant du nœud de départ, en traversant tous les nœuds et enfin en revenant au nœud de départ.
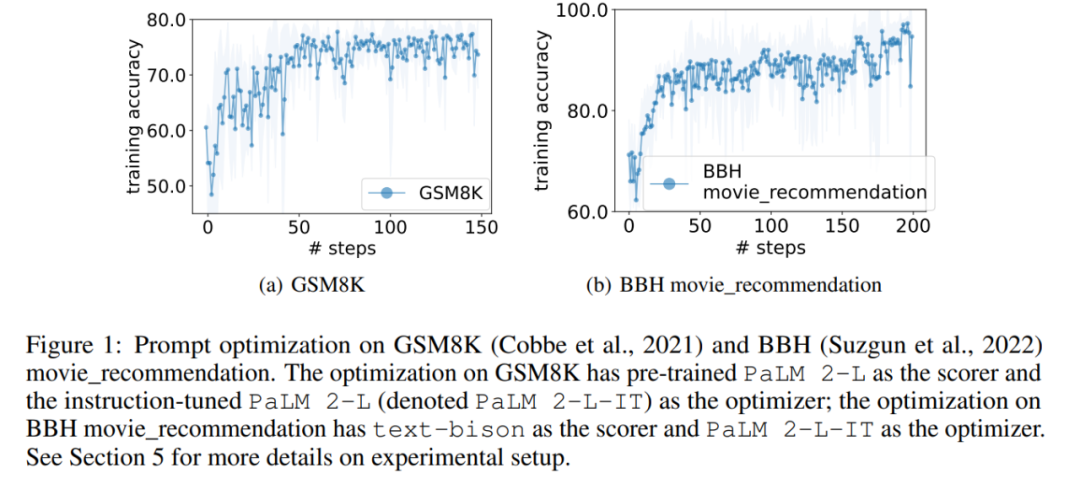
Dans l'expérience, cet article utilise le PaLM 2-L pré-entraîné, le PaLM 2-L réglé avec précision, text-bison, gpt-3.5-turbo, et gpt-4 comme LLM Optimizer ; PaLM 2-L pré-entraîné et text-bison comme buteur LLM. Le benchmark d'évaluation GSM8K concerne les mathématiques à l'école primaire, avec 7473 échantillons d'entraînement et 1319 échantillons de test ; le benchmark Big-Bench Hard (BBH) couvre un large éventail de sujets au-delà du raisonnement arithmétique, y compris les opérations symboliques et le raisonnement de bon sens. . La figure 1 (a) montre la courbe d'optimisation instantanée en utilisant PaLM 2-L pré-entraîné comme marqueur et PaLM 2-L-IT comme optimiseur, on peut observer l'optimisation La courbe montre une tendance globale à la hausse, avec plusieurs sauts se produisant tout au long du processus d'optimisation :
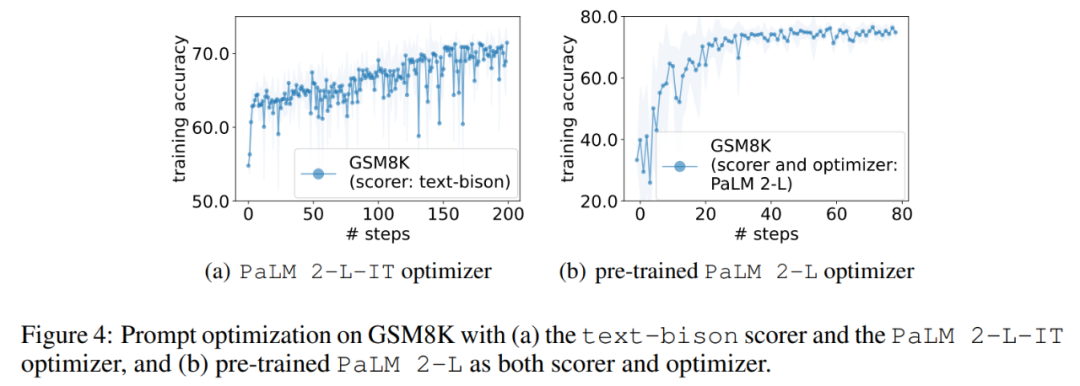
Ensuite, cet article montre les résultats de l'utilisation du marqueur text-bison et de l'optimiseur PaLM 2-L-IT pour générer l'instruction Q_begin. Cet article À partir d'instructions vides, la précision de l'entraînement à ce moment est de 57,1, puis la précision de l'entraînement commence à augmenter. La courbe d'optimisation de la figure 4 (a) montre une tendance à la hausse similaire, au cours de laquelle il y a quelques progrès dans la précision de l'entraînement :
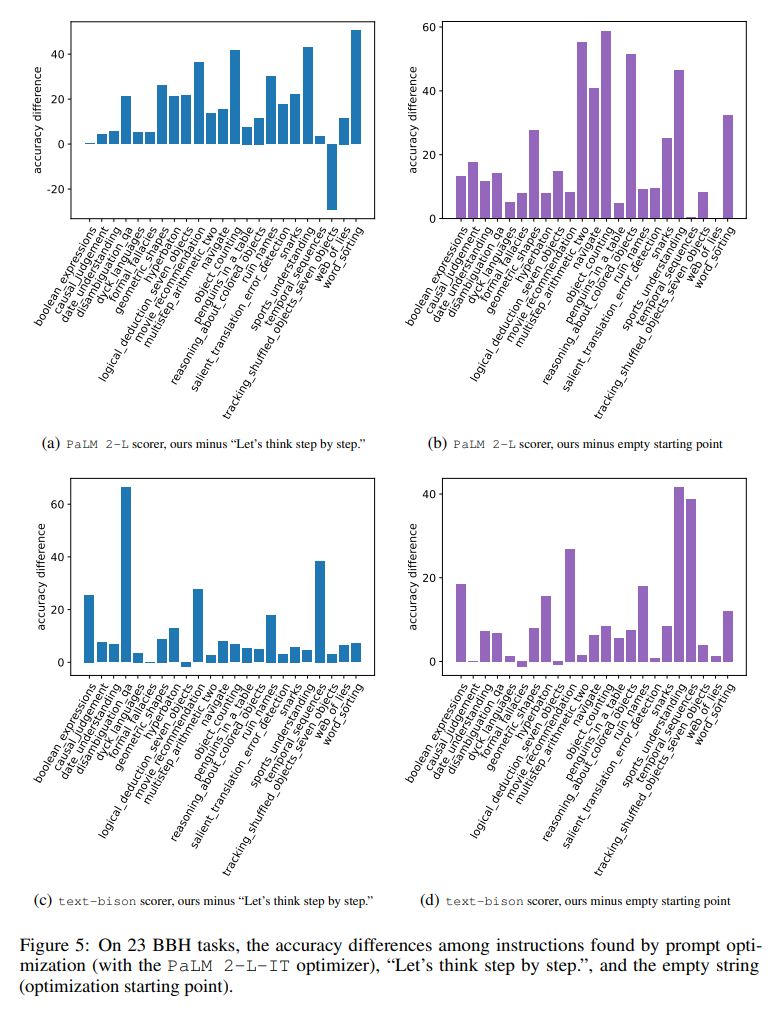
La figure 5 montre visuellement les 23 différences de précision pour chacun tâche par rapport à l'instruction "Réfléchissons étape par étape" entre la tâche BBH. Montre qu'OPRO trouve mieux les instructions que "réfléchissons étape par étape". Il y a un gros avantage sur presque toutes les tâches : les instructions trouvées dans cet article l'ont surpassé de plus de 5 % sur 19/23 tâches utilisant la niveleuse PaLM 2-L et sur 15/23 tâches utilisant la niveleuse texte-bison.
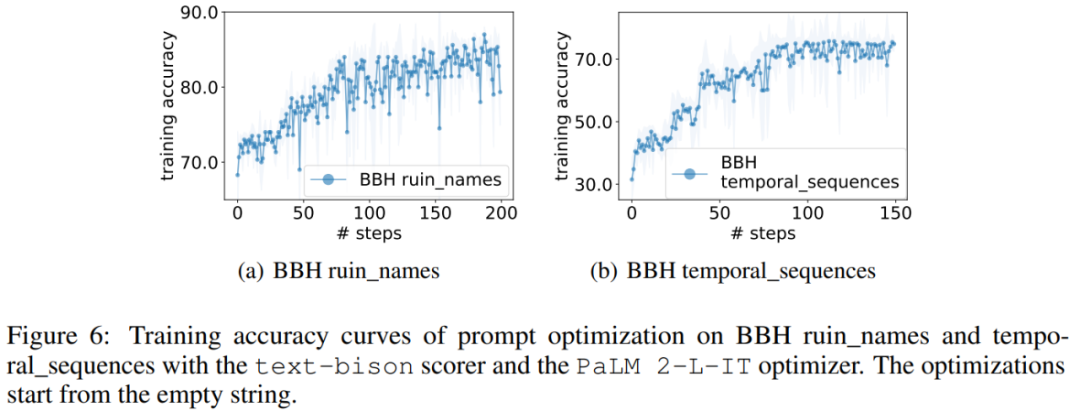
Semblable au GSM8K, cet article observe que les courbes d'optimisation de presque toutes les tâches BBH montrent une tendance à la hausse, comme le montre la figure 6.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Nous pouvons également conclure du tableau ci-dessus que les styles d'instructions finalement trouvés par LLM en tant qu'optimiseur sont très différents. Les instructions de PaLM 2-L- L'informatique et le texte-bison sont plus concis, tandis que les instructions de GPT Les instructions étaient longues et détaillées. Bien que certaines instructions de niveau supérieur contiennent des invites « étape par étape », OPRO peut trouver d'autres expressions sémantiques et atteindre une précision comparable ou meilleure.
Nous pouvons également conclure du tableau ci-dessus que les styles d'instructions finalement trouvés par LLM en tant qu'optimiseur sont très différents. Les instructions de PaLM 2-L- L'informatique et le texte-bison sont plus concis, tandis que les instructions de GPT Les instructions étaient longues et détaillées. Bien que certaines instructions de niveau supérieur contiennent des invites « étape par étape », OPRO peut trouver d'autres expressions sémantiques et atteindre une précision comparable ou meilleure.