
Maison >Périphériques technologiques >IA >Titre réécrit : Byte lance le programme de pré-formation visuelle Vi-PRoM pour améliorer le taux de réussite et l'effet des opérations du robot
Titre réécrit : Byte lance le programme de pré-formation visuelle Vi-PRoM pour améliorer le taux de réussite et l'effet des opérations du robot

- 王林avant
- 2023-09-13 10:57:02966parcourir
Ces dernières années, la pré-formation visuelle sur des données réelles à grande échelle a fait des progrès significatifs, montrant un grand potentiel dans l'apprentissage robotique basé sur l'observation des pixels. Cependant, ces études diffèrent en termes de données, de méthodes et de modèles de pré-formation. Par conséquent, quels types de données, méthodes de pré-entraînement et modèles peuvent mieux aider au contrôle du robot reste une question ouverte. trois perspectives fondamentales des méthodes de formation ont étudié de manière approfondie l'impact des stratégies visuelles de pré-formation sur les tâches de fonctionnement des robots et ont fourni des résultats expérimentaux importants qui sont bénéfiques pour l'apprentissage des robots. En outre, ils ont proposé un programme de pré-formation visuelle pour le fonctionnement des robots appelé
Vi-PRoM, qui combine l'apprentissage auto-supervisé et l'apprentissage supervisé.Le premier utilise l'apprentissage contrastif pour obtenir des modèles latents à partir de données non étiquetées à grande échelle, tandis que le second vise à apprendre la sémantique visuelle et les changements dynamiques temporels. Un grand nombre d’expériences de fonctionnement de robots menées dans divers environnements de simulation et sur des robots réels ont prouvé la supériorité de cette solution.
 Adresse papier : https://arxiv.org/pdf/2308.03620.pdf
Adresse papier : https://arxiv.org/pdf/2308.03620.pdf
- Adresse du projet : https://explore-pretrain-robot.github.io/
- Étude de référence
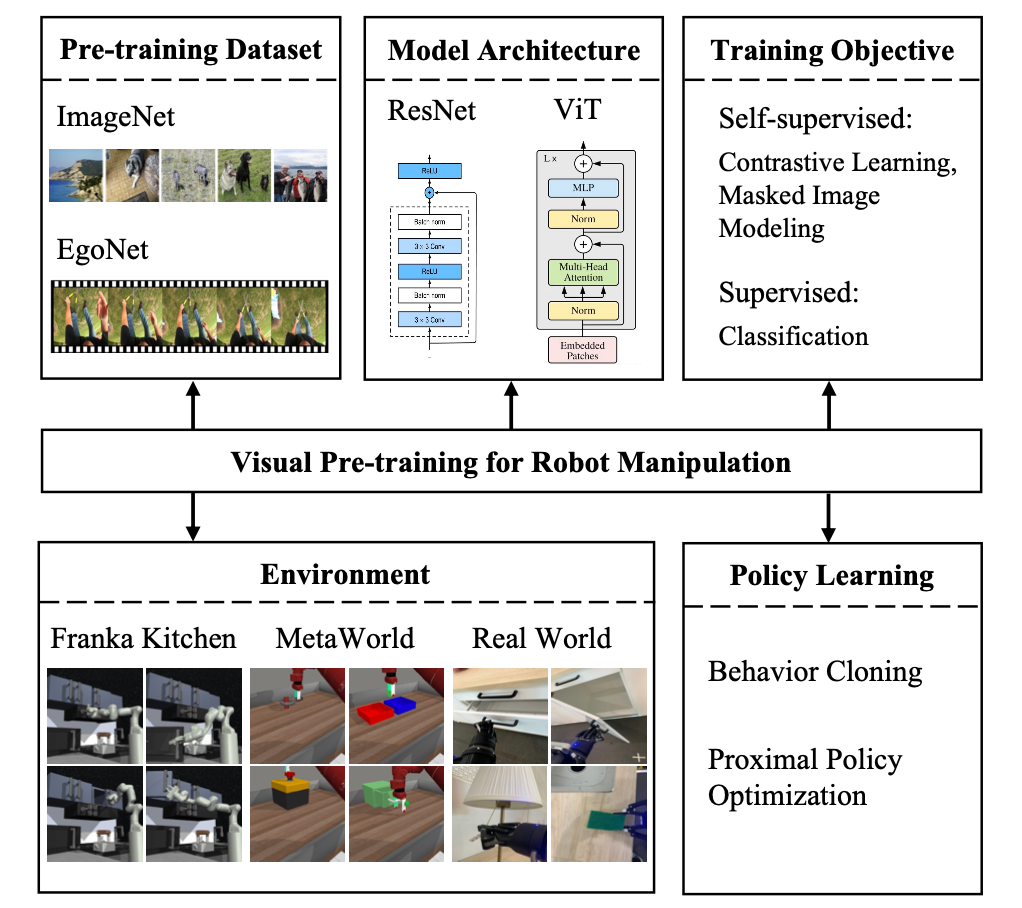 Données pré-entraînées
Données pré-entraînées
EgoNet est plus puissant qu'ImageNet. Pré-entraîner les encodeurs visuels sur différents ensembles de données (c'est-à-dire ImageNet et EgoNet) grâce à des méthodes d'apprentissage contrastées et observer leurs performances dans les tâches de manipulation de robots. Comme le montre le tableau 1 ci-dessous, le modèle pré-entraîné sur EgoNet a obtenu de meilleures performances sur les tâches de fonctionnement du robot. Évidemment, les robots préfèrent les connaissances interactives et les relations temporelles contenues dans les vidéos en termes de tâches opérationnelles. De plus, les images naturelles égocentriques d'EgoNet ont un contexte plus global sur le monde, ce qui signifie que des caractéristiques visuelles plus riches peuvent être apprises
Structure du modèle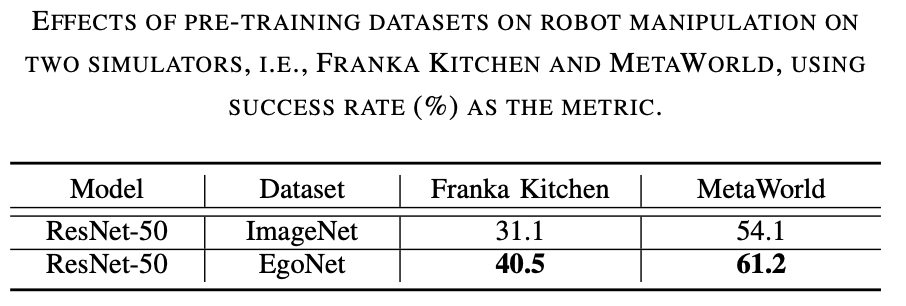
ResNet-50 est plus performant. Comme le montre le tableau 2 ci-dessous, ResNet-50 et ResNet-101 fonctionnent mieux que ResNet-34 sur les tâches de manipulation de robots. De plus, les performances ne s'améliorent pas à mesure que le modèle passe de ResNet-50 à ResNet-101.
Méthode de pré-formation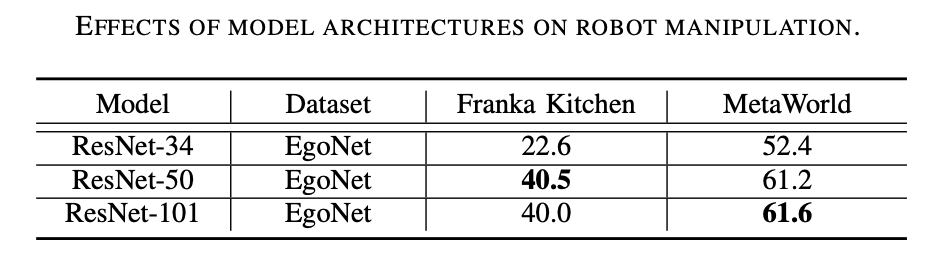
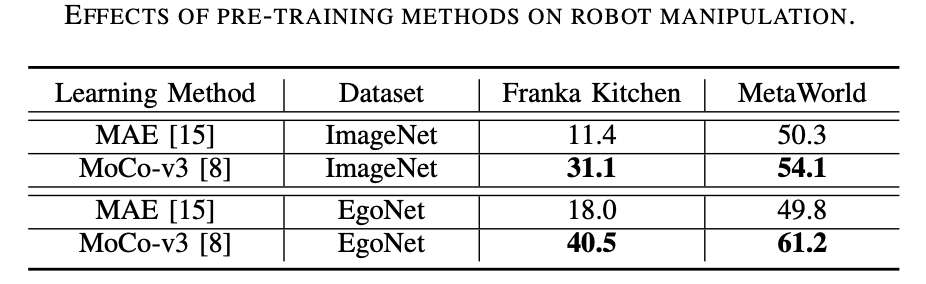
Selon le sens du texte original, le contenu à réécrire est : « La méthode de pré-formation privilégie l'apprentissage contrastif. Comme le montre le tableau 3 ci-dessous, MoCo-v3 fonctionne bien sur ImageNet et les données EgoNet sont meilleures que MAE sur tous les ensembles, ce qui prouve que l'apprentissage contrastif est plus efficace que la modélisation d'images de masque. les informations structurelles apprises grâce à la modélisation d’images de masques. Contenu réécrit : L'apprentissage contrastif est la méthode de pré-formation privilégiée. Comme le montre le tableau 3, MoCo-v3 surpasse MAE sur les ensembles de données ImageNet et EgoNet, indiquant que l'apprentissage contrastif est plus efficace que la modélisation d'images de masque. De plus, la sémantique visuelle obtenue par apprentissage contrastif est plus importante pour le fonctionnement du robot que les informations structurelles apprises par la modélisation d'images de masques
Introduction à l'algorithme
Sur la base de l'exploration ci-dessus, cette étude propose une Solution de pré-formation visuelle pour le fonctionnement des robots (Vi-PRoM). Cette solution extrait une représentation visuelle complète des opérations du robot en pré-entraînant ResNet-50 sur l'ensemble de données EgoNet. Plus précisément, nous utilisons d'abord l'apprentissage contrastif pour obtenir les modèles d'interaction entre les personnes et les objets à partir de l'ensemble de données EgoNet par auto-supervision. Ensuite, deux objectifs d'apprentissage supplémentaires, à savoir la prédiction sémantique visuelle et la prédiction dynamique temporelle, sont proposés pour enrichir davantage la représentation de l'encodeur. La figure ci-dessous montre le processus de base de Vi-PRoM. Notamment, cette étude ne nécessite pas d'étiquetage manuel pour apprendre la sémantique visuelle et la dynamique temporelle
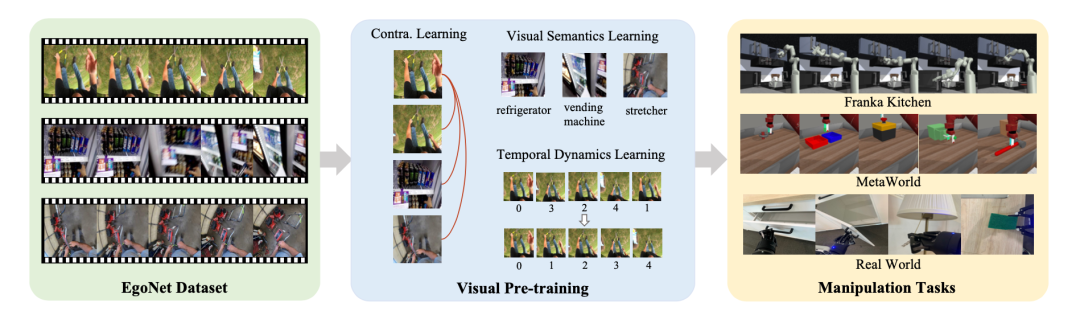
Résultats expérimentaux
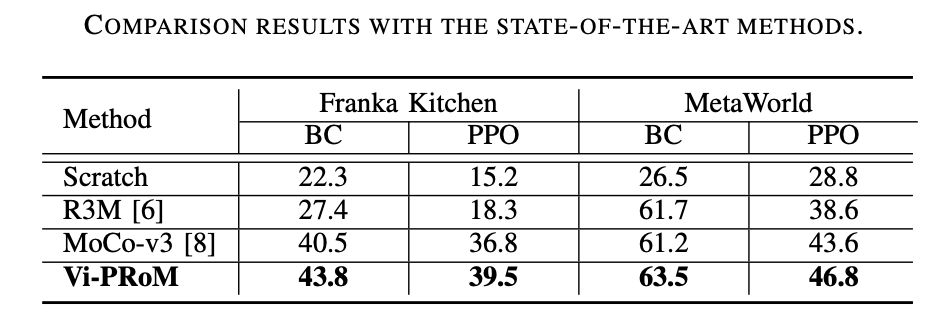
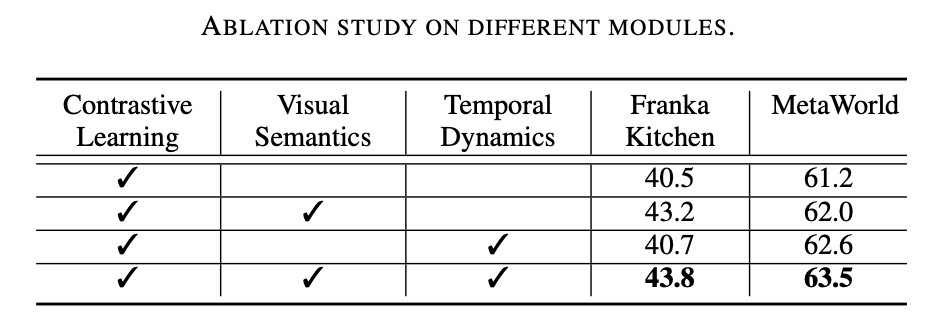
Ce travail de recherche a mené des expériences approfondies sur deux environnements de simulation (Franka Kitchen et MetaWorld). Les résultats expérimentaux montrent que le programme de pré-formation proposé surpasse les précédentes méthodes de pointe en matière de fonctionnement des robots. Les résultats de l'expérience d'ablation sont présentés dans le tableau ci-dessous, ce qui peut prouver l'importance de l'apprentissage sémantique visuel et de l'apprentissage dynamique temporel pour le fonctionnement du robot. De plus, lorsque les deux cibles d’apprentissage sont absentes, le taux de réussite de Vi-PRoM diminue considérablement, démontrant l’efficacité de la collaboration entre l’apprentissage sémantique visuel et l’apprentissage dynamique temporel.
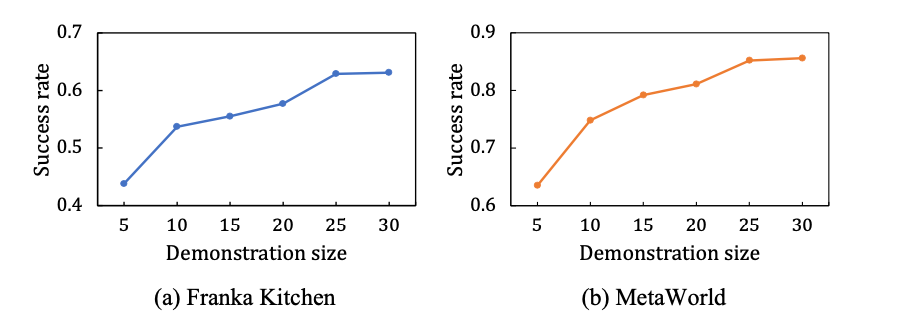
Ce travail étudie également l'évolutivité de Vi-PRoM. Comme le montre la figure ci-dessous à gauche, dans les environnements de simulation Franka Kitchen et MetaWorld, le taux de réussite de Vi-PRoM s'améliore régulièrement à mesure que la taille des données de démonstration augmente. Après une formation sur un ensemble de données de démonstration expert plus large, le modèle Vi-PRoM montre son évolutivité sur les tâches de manipulation de robots.

Grâce aux puissantes capacités de représentation visuelle de Vi-PRoM, de vrais robots peuvent ouvrir avec succès les tiroirs et les portes d'armoires
Comme le montrent les résultats expérimentaux sur Franka Kitchen, Vi- PRoM Il a un taux de réussite et un degré d'achèvement des actions plus élevés que R3M dans les cinq tâches.
R3M :





Vi-PRoM :





Sur MetaWorld, de bonnes performances ont été apprises grâce à la représentation visuelle de Vi- PRoM Fonctionnalités sémantiques et dynamiques, il peut être mieux utilisé pour la prédiction d'actions, donc par rapport à R3M, Vi-PRoM nécessite moins d'étapes pour terminer l'opération.
R3M:

Vi-PRoM:


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment exporter un modèle dans Navicat
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Application et recherche de recherche d'industrie basée sur un modèle de langage pré-entraîné
- Lors de l'examen d'entrée à l'université d'anglais de cette année, la CMU a utilisé la pré-formation en reconstruction pour obtenir un score élevé de 134, dépassant largement le GPT3.
- Musk annonce qu'il poursuivra Microsoft pour avoir utilisé les données de Twitter pour entraîner un système d'intelligence artificielle