
Maison >Périphériques technologiques >IA >GPT-4 : Oserez-vous utiliser le code que j'ai écrit ? La recherche montre que son taux d'utilisation abusive de l'API dépasse 62 %
GPT-4 : Oserez-vous utiliser le code que j'ai écrit ? La recherche montre que son taux d'utilisation abusive de l'API dépasse 62 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-13 09:13:01813parcourir
Une nouvelle ère de modélisation du langage est arrivée. Les grands modèles de langage (LLM) ont des capacités extraordinaires. Ils peuvent non seulement comprendre le langage naturel, mais même générer du code personnalisé en fonction des besoins des utilisateurs.
Par conséquent, de plus en plus d'ingénieurs logiciels choisissent d'interroger de grands modèles de langage pour répondre à des questions de programmation, telles que l'utilisation d'API pour générer des extraits de code ou détecter des bogues dans le code. Les grands modèles de langage peuvent récupérer des réponses mieux adaptées aux questions de programmation que la recherche sur des forums de programmation en ligne comme Stack Overflow.
LLM est rapide, mais cela masque également des risques potentiels dans sa génération de code. Du point de vue du génie logiciel, la robustesse et la fiabilité de la capacité de LLM à générer du code n'ont pas été étudiées de manière approfondie, même si de nombreux résultats de recherche ont été publiés (en termes d'évitement des erreurs syntaxiques et d'amélioration de la compréhension sémantique du code généré).
Contrairement à la situation dans les forums de programmation en ligne, le code généré par LLM n'est pas examiné par les pairs de la communauté, des problèmes d'utilisation abusive de l'API peuvent donc survenir, tels que des vérifications de limites manquantes lors de la lecture de fichiers et de l'indexation de variables, des fermetures d'E/S de fichiers manquantes, la transaction échoue, etc. Même si l'exemple de code généré peut exécuter ou exécuter des fonctions correctement, une mauvaise utilisation peut entraîner de graves risques potentiels pour le produit, tels que des fuites de mémoire, des plantages de programmes, des échecs de garbage collection, etc.
Ce qui est pire, c'est que les programmeurs qui posent ces questions sont les plus vulnérables car ils sont plus susceptibles d'être nouveaux dans l'API et incapables de discerner les problèmes potentiels dans les extraits de code générés.
La figure ci-dessous montre un exemple d'ingénieur logiciel posant des questions de programmation à LLM. On peut voir que Llama-2 peut fournir des extraits de code avec une syntaxe correcte, des fonctions correctes et un alignement de syntaxe, mais il y a un problème. n'est pas assez robuste et fiable, car il ne prend pas en compte le fait que le fichier existe déjà ou que le dossier n'existe pas.

Par conséquent, lors de l'évaluation des capacités de génération de code de grands modèles de langage, la fiabilité du code doit être prise en compte.
En termes d'évaluation des capacités de génération de code des grands modèles de langage, la plupart des benchmarks existants se concentrent sur l'exactitude fonctionnelle des résultats d'exécution du code généré, ce qui signifie que tant que le code généré peut répondre aux exigences fonctionnelles de l'utilisateur, l'utilisateur l'accepte simplement.
Mais dans le domaine du développement logiciel, il ne suffit pas que le code s'exécute correctement. Ce dont les ingénieurs logiciels ont besoin, c'est d'un code capable d'utiliser la nouvelle API correctement et de manière fiable, sans risques potentiels à long terme.
De plus, la portée de la plupart des problèmes de programmation actuels est très éloignée du génie logiciel. La plupart de ses sources de données sont des réseaux de défis de programmation en ligne, tels que Codeforces, Kattis, Leetcode, etc. Bien que cette réalisation soit remarquable, elle ne suffit pas à aider le développement de logiciels dans des scénarios d’application pratiques.
À cette fin, Li Zhong et Zilong Wang de l'Université de Californie à San Diego ont proposé RobustAPI, un framework capable d'évaluer la fiabilité et la robustesse du code généré par de grands modèles de langage, qui contient un ensemble de données de problèmes de programmation et un grammaire abstraite utilisant Evaluator for Trees (AST).

Adresse papier : https://arxiv.org/pdf/2308.10335.pdf
L'objectif de l'ensemble de données est de créer un cadre d'évaluation proche du développement logiciel réel. À cette fin, les chercheurs ont collecté des questions représentatives sur Java auprès de Stack Overflow. Java est l'un des langages de programmation les plus populaires et est largement utilisé pour le développement de logiciels grâce à sa fonctionnalité d'écriture une fois exécutée n'importe où (WORA).
Pour chaque question, le chercheur fournit une description détaillée et l'API Java associée. Ils ont également conçu un ensemble de modèles permettant d'appeler de grands modèles de langage afin de générer des extraits de code et les explications correspondantes.
Les chercheurs fournissent également un évaluateur qui utilise un arbre de syntaxe abstraite (AST) pour analyser les extraits de code générés et les comparer aux modèles d'utilisation attendus de l'API.
Les chercheurs ont également formalisé le modèle d'utilisation de l'IA en une séquence d'appels structurée selon la méthode de Zhang et al. Cette séquence structurée d'appels peut démontrer comment ces API peuvent être utilisées correctement pour éliminer les risques potentiels du système. Du point de vue du génie logiciel, toute violation de cette séquence d'appels structurée est considérée comme un échec.
Les chercheurs ont collecté 1 208 vraies questions de Stack Overflow, impliquant 24 API Java représentatives. Les chercheurs ont également mené des évaluations expérimentales, incluant non seulement des modèles de langage à code source fermé (GPT-3.5 et GPT-4), mais également des modèles de langage à code source ouvert (Llama-2 et Vicuna-1.5). Pour les paramètres d'hyperparamètres du modèle, ils ont utilisé les paramètres par défaut et n'ont pas effectué d'autres ajustements d'hyperparamètres. Ils ont également conçu deux formes expérimentales : zéro-shot et one-shot, qui fournissent respectivement zéro ou un échantillon de démonstration dans l'invite.
Les chercheurs ont analysé de manière approfondie le code généré par LLM et étudié les utilisations abusives courantes de l'API. Ils espèrent que cela mettra en lumière le problème important de l’utilisation abusive des API par les LLM lors de la génération de code, et que cette recherche fournira également une nouvelle dimension à l’évaluation des LLM au-delà de l’exactitude fonctionnelle couramment utilisée. De plus, l'ensemble de données et l'estimateur seront open source.
Les contributions de cet article sont résumées comme suit :
- Un nouveau benchmark pour évaluer la fiabilité et la robustesse de la génération de code LLM est proposé : RobustAPI.
- fournit un cadre d'évaluation complet qui comprend un ensemble de données de questions Stack Overflow et un vérificateur d'utilisation de l'API utilisant AST. Sur la base de ce cadre, les chercheurs ont analysé les performances des LLM couramment utilisés, notamment GPT-3.5, GPT-4, Llama-2 et Vicuna-1.5.
- Analyse complète des performances du code généré par LLM. Ils résument les utilisations abusives courantes des API pour chaque modèle et indiquent des pistes d'amélioration pour les recherches futures.
Présentation de la méthode
RobustAPI est un cadre permettant d'évaluer de manière exhaustive la fiabilité et la robustesse du code généré par LLM.
Le processus de collecte de données et le processus de génération d'invites lors de la construction de cet ensemble de données seront décrits ci-dessous. Ensuite, les modèles d'utilisation abusive d'API évalués dans RobustAPI seront présentés et les conséquences potentielles d'une utilisation abusive seront discutées. être donnée. Analyse statique des cas d’utilisation abusive à l’aide d’arbres de syntaxe abstraits.
Il a été constaté que, par rapport aux méthodes basées sur des règles telles que la correspondance de mots clés, la nouvelle méthode peut évaluer l'utilisation abusive par l'API du code généré par LLM avec une plus grande précision.
Collecte de données
Afin de tirer parti des résultats de recherche existants dans le domaine du génie logiciel, le point de départ lorsque les chercheurs ont construit RobustAPI a été l'ensemble de données d'ExampleCheck (Zhang et al. 2018). ExempleCheck est un cadre permettant d'étudier les utilisations abusives courantes de l'API Java dans les forums de questions-réponses Web.
Le chercheur a sélectionné 23 API Java courantes à partir de cet ensemble de données, comme le montre le tableau 1 ci-dessous. Ces 23 API couvrent 5 domaines, notamment le traitement des chaînes, les structures de données, le développement mobile, le cryptage et les opérations de bases de données.

génération d'invite
RobustAPI contient également un modèle d'invite qui peut être rempli à l'aide d'échantillons de l'ensemble de données. Les chercheurs ont ensuite collecté les réponses de LLM à l'invite et ont utilisé un vérificateur API pour évaluer la fiabilité de leur code.

Dans cette invite, l'introduction de la tâche et le format de réponse requis seront d'abord donnés. Ensuite, si l’expérience réalisée est une expérience sur quelques échantillons, une démonstration sur quelques échantillons sera également donnée. Voici un exemple :
Échantillon de démonstration
Il a été prouvé que les échantillons de démonstration aident LLM à comprendre le langage naturel. Afin d'analyser en profondeur la capacité de génération de code de LLM, les chercheurs ont conçu deux paramètres en quelques étapes : une démonstration non pertinente sur un seul échantillon et une démonstration dépendante sur un seul échantillon.
Dans un paramètre de démonstration agnostique à échantillon unique, les exemples de démonstration fournis pour LLM utilisent des API agnostiques. Les chercheurs ont émis l’hypothèse que de tels exemples de démonstration élimineraient les erreurs syntaxiques dans le code généré. Les exemples sans rapport utilisés dans RobustAPI sont les suivants :

Dans un paramètre de démonstration de corrélation à échantillon unique, les exemples de démonstration fournis pour LLM utilisent la même API que celle utilisée pour le problème donné. Cet exemple contient une paire de questions et de réponses. Les questions de cette démo n'étaient pas incluses dans l'ensemble de données de test et les réponses ont été corrigées manuellement pour garantir qu'il n'y avait pas d'utilisation abusive de l'API et que la sémantique des réponses et des questions était bien alignée.
Utilisation abusive de l'API Java
Les chercheurs ont résumé 40 règles d'API pour 23 API dans RobustAPI, qui ont été vérifiées dans la documentation de ces API. Ces règles incluent :
(1) Conditions de garde pour les API, qui doivent être vérifiées avant les appels d'API. Par exemple, le résultat de File.exists() doit être vérifié avant File.createNewFile().
(2) La séquence d'appel de l'API requise, c'est-à-dire que l'API doit être appelée dans un certain ordre. Par exemple, close() doit être appelé après File.write().
(3) Structure de contrôle API. Par exemple, SimpleDateFormat.parse () doit être inclus dans une structure try-catch.
Un exemple est donné ci-dessous :

Détection d'une utilisation abusive de l'API
Afin d'évaluer l'exactitude de l'utilisation de l'API dans le code, RobustAPI peut détecter une utilisation abusive de l'API selon les règles d'utilisation de l'API, L'approche consiste à extraire les résultats de l'appel et les structures de contrôle du segment de code, comme le montre la figure 2 ci-dessous.

Le vérificateur de code vérifie d'abord l'extrait de code généré pour voir s'il s'agit d'un morceau de code dans une méthode ou d'une méthode d'une classe afin qu'il puisse encapsuler l'extrait et l'utiliser Construire un arbre de syntaxe abstraite ( AST).
L'inspecteur parcourt ensuite l'AST et enregistre tous les appels de méthode et les structures de contrôle dans l'ordre, ce qui génère une séquence d'appels.
Ensuite, le vérificateur compare cette séquence d'appels aux règles d'utilisation de l'API. Il déduit le type d'instance pour chaque appel de méthode et utilise ce type et cette méthode comme clés pour récupérer les règles d'utilisation de l'API correspondantes.
Enfin, le vérificateur calcule la séquence commune la plus longue entre cette séquence d'appel et les règles d'utilisation de l'API.
Si la séquence d'appel ne correspond pas aux règles d'utilisation de l'API attendues, le vérificateur signale une utilisation abusive de l'API.
Résultats expérimentaux
Les chercheurs ont évalué RobustAPI sur 4 LLM : GPT-3.5, GPT-4, Llama-2 et Vicuna-1.5.
Les indicateurs d'évaluation utilisés dans l'expérience comprennent : le taux d'utilisation abusive de l'API, le pourcentage d'échantillons d'exécutables et le pourcentage global d'utilisation abusive de l'API.
Le but de l'expérience est d'essayer de répondre aux questions suivantes :
- Question 1 : Quel est le taux d'utilisation abusive des API de ces LLM pour résoudre des problèmes de programmation réels ?
- Question 2 : Quel impact les échantillons de démonstration non pertinents auront-ils sur les résultats ?
- Question 3 : Des exemples corrects d'utilisation d'API peuvent-ils réduire les taux d'utilisation abusive des API ?
- Question 4 : Pourquoi le code généré par LLM ne parvient-il pas à passer le contrôle d'utilisation de l'API ?
Veuillez vous référer à l'article original pour connaître le processus expérimental spécifique. Voici 5 résultats obtenus par les chercheurs :
Constatation 1 : Le meilleur modèle de langage à grande échelle actuel contient généralement des erreurs d'API dans ses réponses aux réponses réelles. -problèmes de programmation mondiale. Utilisez des questions.

Constatation 2 : Parmi toutes les réponses LLM contenant du code exécutable, 57 à 70 % des extraits de code présentent des problèmes d'utilisation abusive de l'API, ce qui peut avoir de graves conséquences en production.
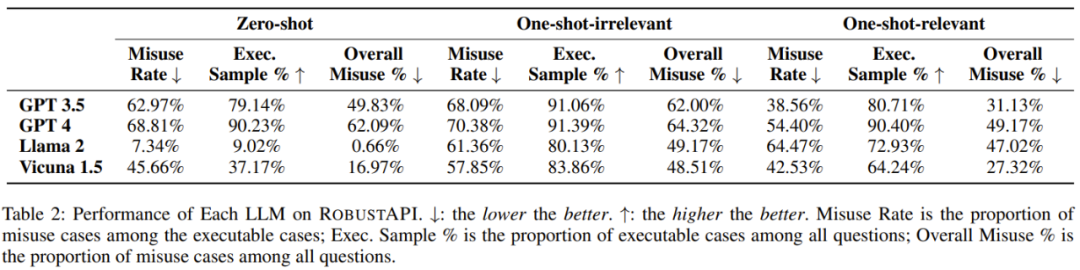
Constatation 3 : des exemples d'exemples non pertinents n'aident pas à réduire le taux d'utilisation abusive des API, mais déclenchent des réponses plus efficaces, qui peuvent être utilisées efficacement pour comparer les performances du modèle.
Constatation 4 : Certains LLM peuvent apprendre des exemples d'utilisation corrects, ce qui peut réduire les taux d'utilisation abusive des API.
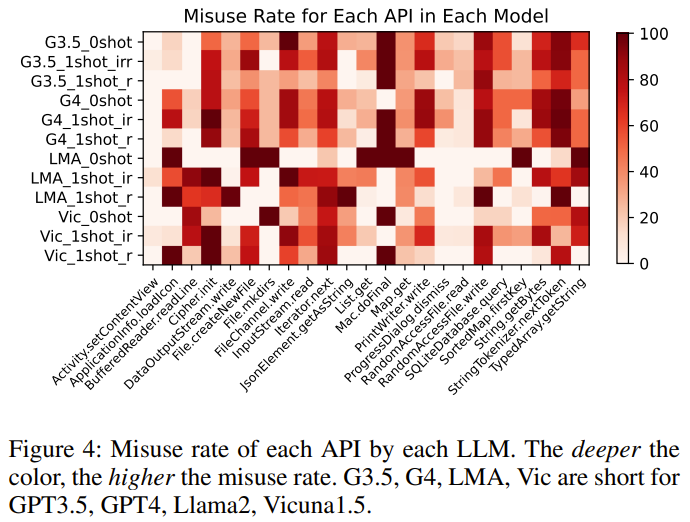
Résultat 5 : GPT-4 a le plus grand nombre de réponses contenant du code exécutable. Pour l'API de référence, différents LLM présentent également des tendances différentes en matière de taux d'utilisation abusive.
De plus, le chercheur a également démontré un cas typique basé sur GPT-3.5 dans l'article : le modèle a différentes réponses dans différents contextes expérimentaux.
La tâche consiste à demander au modèle d'aider à écrire une chaîne dans un fichier à l'aide de l'API PrintWriter.write.

Les réponses sont légèrement différentes dans les paramètres de démonstration agnostiques à échantillon zéro et à échantillon unique, mais les deux présentent des problèmes d'utilisation abusive de l'API - aucune exception n'est prise en compte. Une fois que le modèle a reçu des exemples d'utilisation corrects de l'API, le modèle apprend à utiliser l'API et produit un code fiable.
Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer des modèles redondants dans ZBrush
- Présentation de l'un des modèles de gestion de branche de code GIT
- Qu'est-ce que le modèle de données utilisant la structure arborescente ?
- Lors de l'examen d'entrée à l'université d'anglais de cette année, la CMU a utilisé la pré-formation en reconstruction pour obtenir un score élevé de 134, dépassant largement le GPT3.
- Médias américains : Musk et d'autres ont raison d'appeler à la suspension de la formation en IA et à la nécessité de ralentir pour des raisons de sécurité