
Maison >Périphériques technologiques >IA >Formez rapidement de petits modèles professionnels : 1 seule commande, 5 $ et 20 minutes, essayez Prompt2Model !
Formez rapidement de petits modèles professionnels : 1 seule commande, 5 $ et 20 minutes, essayez Prompt2Model !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-11 16:33:021280parcourir
Les modèles linguistiques à grande échelle (LLM) permettent aux utilisateurs de créer de puissants systèmes de traitement du langage naturel grâce à des astuces et à un apprentissage contextuel. Cependant, d'un autre point de vue, LLM montre certaines régressions dans certaines tâches spécifiques de traitement du langage naturel : le déploiement de ces modèles nécessite beaucoup de ressources informatiques, et l'interaction avec les modèles via des API peut soulever des problèmes potentiels de confidentialité
Afin de. Pour résoudre ces problèmes, des chercheurs de l'Université Carnegie Mellon (CMU) et de l'Université Tsinghua ont lancé conjointement le cadre Prompt2Model. L'objectif de ce cadre est de combiner des méthodes de génération et de récupération de données basées sur LLM pour surmonter les défis ci-dessus. Grâce au framework Prompt2Model, les utilisateurs n'ont qu'à fournir les mêmes invites que LLM pour collecter automatiquement des données et former efficacement de petits modèles spécialisés adaptés à des tâches spécifiques.
Les chercheurs ont mené une expérience sur trois tâches de sous-systèmes de traitement du langage naturel qui ont été étudiées. Ils ont utilisé un petit nombre d'exemples d'invites comme entrée et n'ont dépensé que 5 $ pour collecter les données et 20 minutes de formation. Les performances du modèle généré via le framework Prompt2Model sont 20 % supérieures à celles du puissant modèle LLM gpt-3.5-turbo. Dans le même temps, la taille du modèle a été réduite de 700 fois. Les chercheurs ont en outre vérifié l'impact de ces données sur les performances du modèle dans des scénarios réels, permettant aux développeurs de modèles d'estimer la fiabilité du modèle avant son déploiement. Le framework a été fourni sous forme open source :

- Adresse du référentiel GitHub du framework : https://github.com/neulab/prompt2model
- Lien vidéo de démonstration du framework : youtu. be/LYYQ_EhGd -Q
- Lien papier lié au framework : https://arxiv.org/abs/2308.12261
Contexte
Construire un système pour une tâche spécifique de traitement du langage naturel est généralement assez complexe. Le constructeur du système doit définir clairement la portée de la tâche, obtenir un ensemble de données spécifique, choisir une architecture de modèle appropriée, former et évaluer le modèle, puis le déployer pour une application pratique
Modèle de langage à grande échelle ( LLM) tel que GPT-3 offre une solution plus simple à ce processus. Les utilisateurs doivent uniquement fournir des instructions de tâche et quelques exemples, et LLM peut générer la sortie texte correspondante. Cependant, la génération de texte à partir d'indices peut nécessiter beaucoup de calculs, et l'utilisation d'indices est moins stable qu'un modèle spécialement entraîné. De plus, la convivialité de LLM est également limitée par le coût, la vitesse et la confidentialité. Pour résoudre ces problèmes, les chercheurs ont développé le framework Prompt2Model. Ce cadre combine des techniques de génération et de récupération de données basées sur LLM pour surmonter les limitations ci-dessus. Le système extrait d'abord les informations clés des informations d'invite, puis génère et récupère les données de formation, et enfin génère un modèle spécialisé prêt à être déployé
Le framework Prompt2Model effectue automatiquement les étapes principales suivantes : 1. Prétraitement des données : nettoyez et standardisez les données d'entrée pour garantir qu'elles conviennent à la formation du modèle. 2. Sélection du modèle : sélectionnez l'architecture et les paramètres du modèle appropriés en fonction des exigences de la tâche. 3. Formation du modèle : utilisez les données prétraitées pour entraîner le modèle sélectionné afin d'optimiser les performances du modèle. 4. Évaluation du modèle : évaluation des performances du modèle formé au moyen d'indicateurs d'évaluation pour déterminer ses performances sur des tâches spécifiques. 5. Ajustement du modèle : sur la base des résultats de l'évaluation, ajustez le modèle pour améliorer encore ses performances. 6. Déploiement du modèle : déployez le modèle formé dans l'environnement d'application réel pour réaliser des fonctions de prédiction ou d'inférence. En automatisant ces étapes principales, le framework Prompt2Model peut aider les utilisateurs à créer et déployer rapidement des modèles de traitement du langage naturel hautes performances
Récupération d'ensembles de données et de modèles : collectez des ensembles de données pertinents et des modèles pré-entraînés.
- Génération d'ensembles de données : utilisez LLM pour créer des ensembles de données pseudo-étiquetés.
- Réglage fin du modèle : affinez le modèle en mélangeant les données récupérées et les données générées.
- Test de modèle : testez le modèle sur un ensemble de données de test et un ensemble de données réel fourni par l'utilisateur.
- Grâce à une évaluation empirique sur plusieurs tâches différentes, nous avons constaté que le coût de Prompt2Model est considérablement réduit et que la taille du modèle est également considérablement réduite, mais que les performances dépassent gpt-3.5-turbo. Le framework Prompt2Model peut non seulement être utilisé comme un outil pour créer efficacement des systèmes de traitement du langage naturel, mais également comme une plate-forme pour explorer la technologie de formation à l'intégration de modèles
Framework
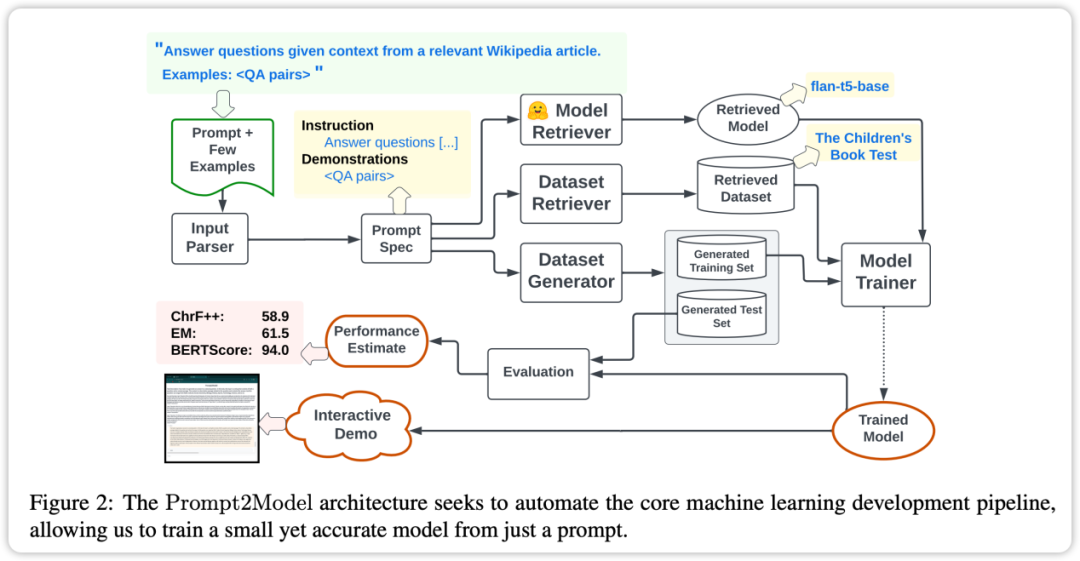
La fonctionnalité principale du framework Prompt2Model est un degré élevé d'automatisation. Son processus comprend la collecte de données, la formation du modèle, l'évaluation et le déploiement, comme le montre la figure ci-dessus. Parmi eux, le système automatisé de collecte de données joue un rôle clé en obtenant des données étroitement liées aux besoins des utilisateurs grâce à la récupération d'ensembles de données et à la génération de données basées sur LLM. Ensuite, le modèle pré-entraîné est récupéré et affiné sur l'ensemble de données acquis. Enfin, le modèle formé est évalué sur l'ensemble de test et une interface utilisateur Web (UI) est créée pour interagir avec le modèle. est qu'en utilisant l'invite comme pilote, les utilisateurs peuvent décrire directement les tâches requises sans entrer dans les détails spécifiques de mise en œuvre de l'apprentissage automatique.
Collecte automatique de données : le cadre utilise une technologie de récupération et de génération d'ensembles de données pour obtenir des données qui correspondent parfaitement aux tâches de l'utilisateur, établissant ainsi l'ensemble de données requis pour la formation.
- Modèles pré-entraînés : le framework utilise des modèles pré-entraînés et les affine, économisant ainsi beaucoup de temps et de coûts de formation.
- Évaluation des effets : Prompt2Model prend en charge les tests et l'évaluation de modèles sur des ensembles de données réels, permettant d'effectuer des prédictions préliminaires et des évaluations de performances avant de déployer le modèle, améliorant ainsi la fiabilité du modèle.
- Le framework Prompt2Model présente les caractéristiques suivantes, ce qui en fait un outil puissant qui peut compléter efficacement le processus de construction de systèmes de traitement du langage naturel et fournit des fonctions avancées, telles que la collecte automatique de données, l'évaluation de modèles et l'interface d'interaction utilisateur Créer
- Expériences et résultats
Afin d'évaluer les performances du système Prompt2Model, dans la conception expérimentale, le chercheur a choisi trois tâches différentes
AQ en lecture automatique : utilisation de SQuAD comme ensemble de données d'évaluation pratique.
Japanese NL-to-Code : utilisation de MCoNaLa comme ensemble de données d'évaluation réel.
- Normalisation de l'expression temporelle : utilisez l'ensemble de données temporelles comme ensemble de données d'évaluation réel.
- De plus, les chercheurs ont également utilisé GPT-3.5-turbo comme modèle de base à des fins de comparaison. Les résultats expérimentaux conduisent aux conclusions suivantes :
- Dans toutes les tâches à l'exception de la tâche de génération de code, le modèle généré par le système Prompt2Model est nettement meilleur que le modèle de référence GPT-3.5-turbo, bien que l'échelle des paramètres du modèle généré soit beaucoup plus petit que le GPT-3.5-turbo.
En mélangeant l'ensemble de données de récupération avec l'ensemble de données généré pour la formation, vous pouvez obtenir des résultats comparables à ceux utilisant directement la formation de l'ensemble de données réel. Cela vérifie que le framework Prompt2Model peut réduire considérablement le coût de l'annotation manuelle.
- L'ensemble de données de test généré par le générateur de données peut distinguer efficacement les performances de différents modèles sur des ensembles de données réels. Cela indique que les données générées sont de haute qualité et ont une efficacité suffisante dans la formation du modèle.
- Dans la tâche de conversion du japonais en code, le système Prompt2Model est moins performant que GPT-3.5-turbo.
- Cela peut être dû à la faible qualité de l'ensemble de données généré et au manque de modèles pré-entraînés appropriés
- En résumé, le système Prompt2Model a généré avec succès de petits modèles de haute qualité sur plusieurs tâches, réduisant considérablement la nécessité d’une annotation manuelle des données. Cependant, des améliorations supplémentaires sont encore nécessaires sur certaines tâches
Résumé
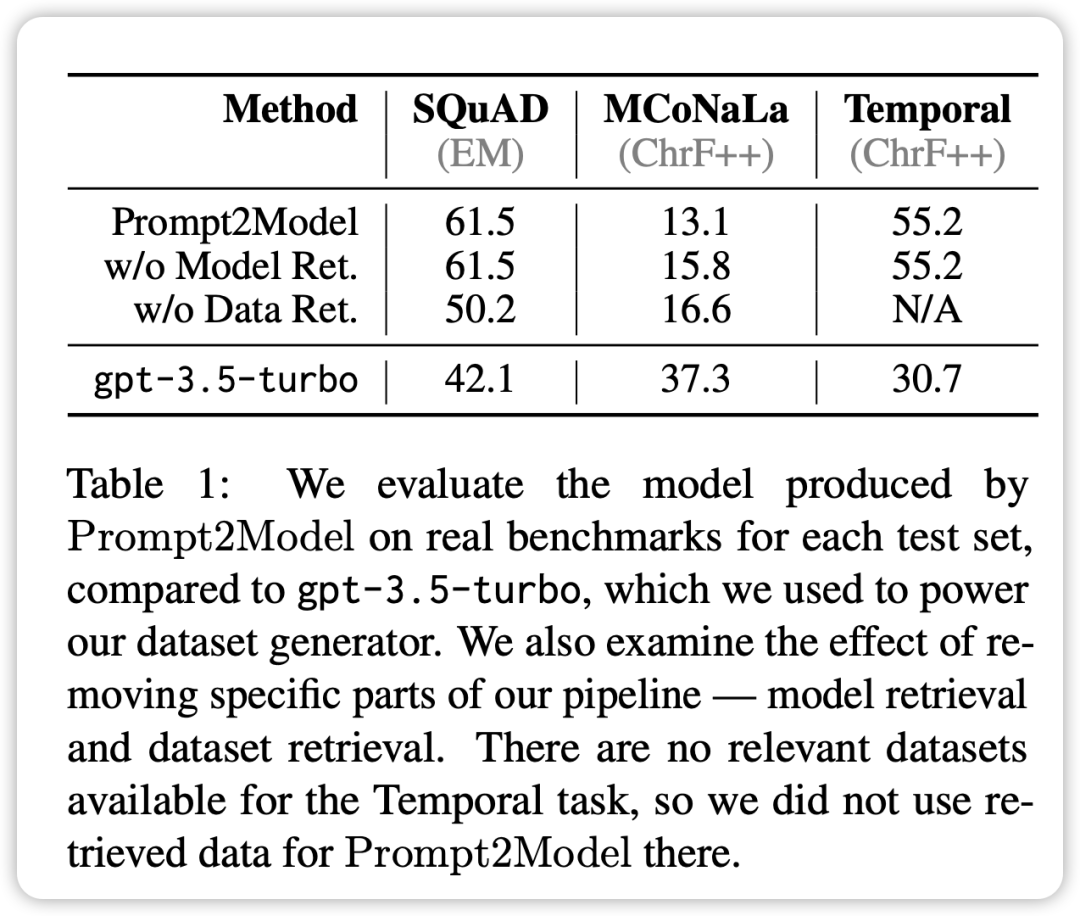
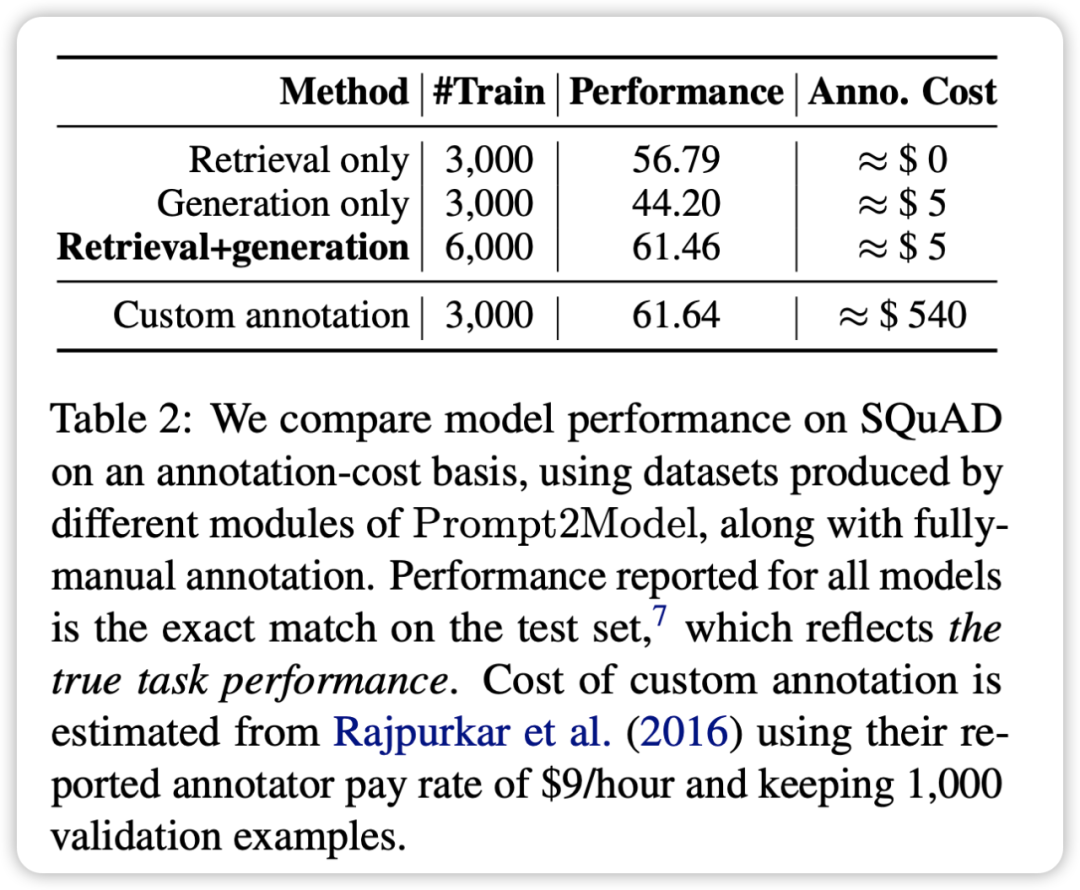
Les résultats de l'expérience de vérification montrent que la taille du modèle généré par le framework Prompt2Model est considérablement réduite par rapport au modèle de langage plus grand et qu'il fonctionne mieux que GPT-3.5-turbo et d'autres modèles sur plusieurs tâches. Dans le même temps, l'ensemble de données d'évaluation généré par ce cadre s'est également avéré efficace pour évaluer les performances de différents modèles sur des ensembles de données réels. Cela apporte une valeur importante pour guider le déploiement final du modèle
Le framework Prompt2Model offre aux industries et aux utilisateurs un moyen peu coûteux et facile à utiliser d'obtenir des modèles NLP qui répondent à des besoins spécifiques. Ceci est d’une grande importance pour promouvoir l’application généralisée de la technologie PNL. Les travaux futurs continueront d'être consacrés à l'optimisation supplémentaire des performances du framework
Dans l'ordre des articles, les auteurs de cet article sont les suivants : Contenu réécrit : Selon l'ordre des articles, les auteurs de cet article sont les suivants :
Vijay Viswanathan : http://www.cs.cmu.edu/~vijayv/
Zhao Chenyang : https ://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch : https://www.cs.cmu.edu/~abertsch/ Amanda Belch : https://www.cs.cmu.edu/~abertsch/
Wu Tongshuang : https://www.cs.cmu.edu/~sherryw/
Graham · Newbig : http : //www.phontron.com/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!