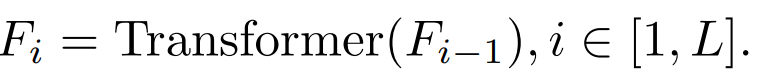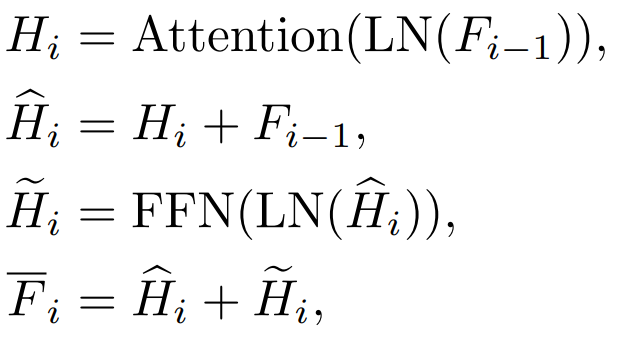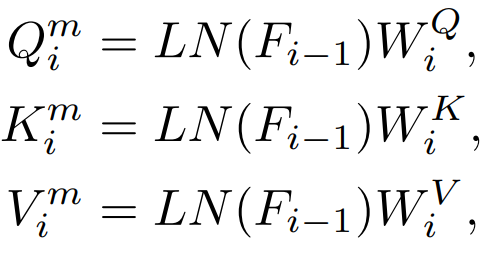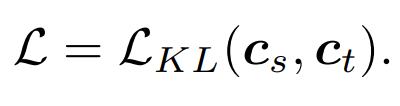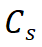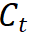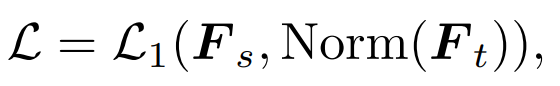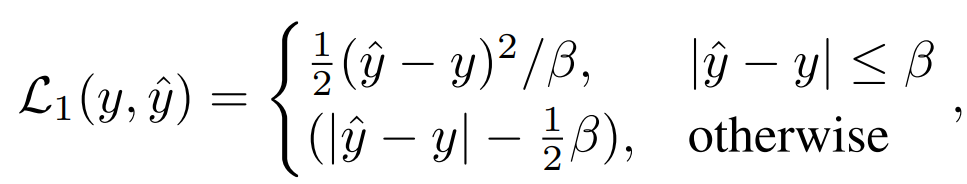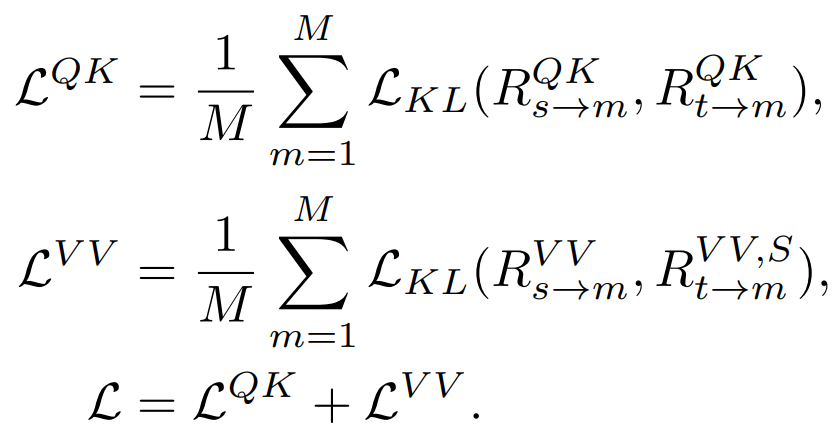Ré-exprimée : Motivation pour la recherche
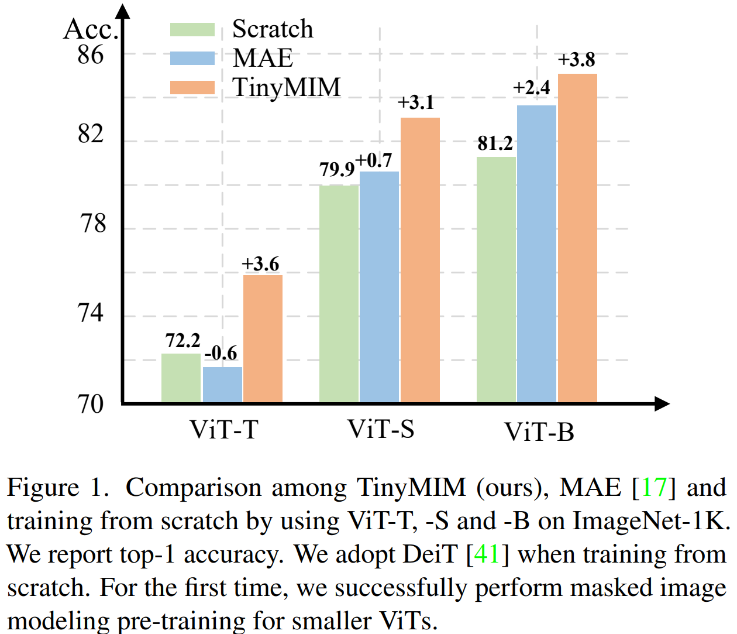
La modélisation de masques (MIM, MAE) s'avère être une méthode d'entraînement auto-supervisée très efficace. Cependant, comme le montre la figure 1, MIM fonctionne relativement mieux pour les modèles plus grands. Lorsque le modèle est très petit (comme les paramètres ViT-T 5M, un tel modèle est très important pour le monde réel), MIM peut même réduire dans une certaine mesure l'effet du modèle. Par exemple, l'effet de classification de ViT-L formé avec MAE sur ImageNet est 3,3 % supérieur à celui du modèle formé avec supervision ordinaire, mais l'effet de classification de ViT-T formé avec MAE sur ImageNet est 0,6 % inférieur à celui du modèle formé avec supervision ordinaire. modèle formé avec une supervision ordinaire. Dans ce travail, nous avons proposé TinyMIM, qui utilise une méthode de distillation pour transférer les connaissances des grands modèles vers ViT tout en gardant la structure inchangée et en ne modifiant pas la structure pour introduire d'autres biais inductifs. 
- Adresse papier : https://arxiv.org/pdf/2301.01296.pdf
- Adresse code : https://github.com/OliverRensu /PetitMIM
Nous avons systématiquement étudié l'impact des objectifs de distillation, de l'enrichissement des données, de la régularisation, des fonctions auxiliaires de perte, etc. sur la distillation. Dans le cas de l'utilisation stricte d'ImageNet-1K comme données de formation (y compris le modèle Teacher utilisant également uniquement la formation ImageNet-1K) et de ViT-B comme modèle, notre méthode atteint actuellement les meilleures performances. Comme le montre la figure : comparez notre méthode (TinyMIM) avec la méthode basée sur la reconstruction de masque MAE et la méthode d'apprentissage supervisé DeiT formée à partir de zéro. MAE présente des améliorations de performances significatives lorsque le modèle est relativement grand, mais lorsque le modèle est relativement petit, l'amélioration est limitée et peut même nuire à l'effet final du modèle. Notre méthode, TinyMIM, permet d'obtenir des améliorations substantielles sur différentes tailles de modèles. Nos contributions sont les suivantes :
1) Distiller la relation entre les jetons est plus efficace que distiller les jetons de classe ou les cartes de fonctionnalités seuls 2) Il est plus efficace d'utiliser le milieu ; couche comme cible pour la distillation.
2. Amélioration des données et régularisation du modèle (régularisation des données et du réseau) : 1) L'effet de l'utilisation d'images masquées est pire ; 2) Le modèle étudiant a besoin d'un petit chemin de chute, mais pas le modèle enseignant. 3. Pertes auxiliaires : MIM n’a aucun sens en tant que fonction de perte auxiliaire. 4. Stratégie de macro distillation : nous avons constaté que la distillation sérialisée (ViT-B -> ViT-S -> ViT-T) fonctionne le mieux.
Nous avons systématiquement étudié les objectifs de distillation, les images d'entrée et les modules d'objectifs de distillation. 2.1 Facteurs affectant l'effet de distillation
Dang Lorsque i = L, cela fait référence aux caractéristiques de la couche de sortie du transformateur. Lorsque i
b. Fonctionnalités Attention (Attention) et fonctionnalités de couche Feed-forward (FFN)
Transformer Chaque bloc a une couche Attention et une couche FFN, et distille différents calques auront des effets différents.
Il y aura des fonctionnalités Q, K, V dans la couche Attention. Ces fonctionnalités sont utilisées pour calculer le mécanisme d'attention. le direct Distiller ces caractéristiques.
Q, K, V sont utilisés pour calculer la carte d'attention, et la relation entre ces caractéristiques peut également être utilisée comme cible de connaissances distillation.
3) Entrée : masquée ou non
La distillation des connaissances traditionnelles consiste à saisir directement l'image complète. Notre méthode consiste à explorer le modèle de modélisation du masque de distillation. Nous examinons donc également si les images masquées conviennent comme entrées pour la distillation des connaissances. 2.2 Comparaison des méthodes de distillation des connaissances 1) Distillation du jeton de classe :
La méthode la plus simple consiste à distiller directement le jeton de classe du modèle pré-entraîné MAE comme DeiT :
où fait référence au jeton de classe du modèle étudiant, et
fait référence au jeton de classe du modèle enseignant. 2) Distillation de caractéristiques : Nous nous référons directement à la distillation de caractéristiques [1] pour comparaison
3) Distillation par relation : Nous avons également proposé Le stratégie de distillation par défaut dans cet article
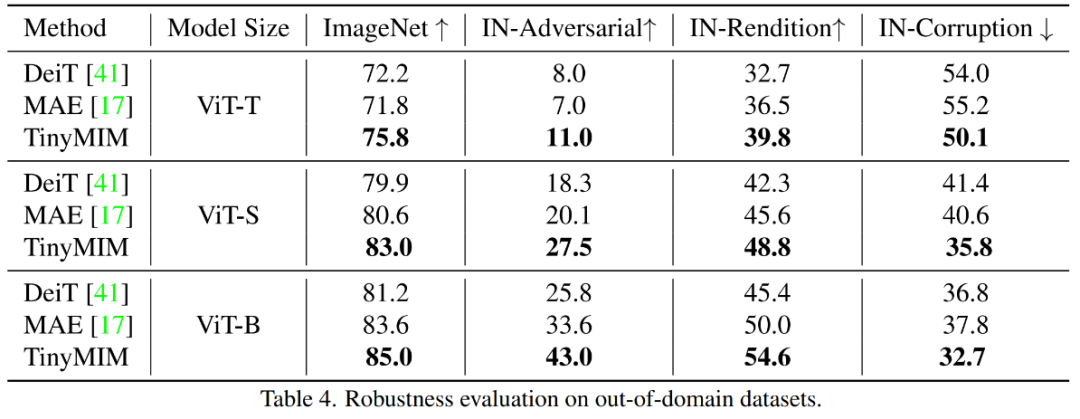
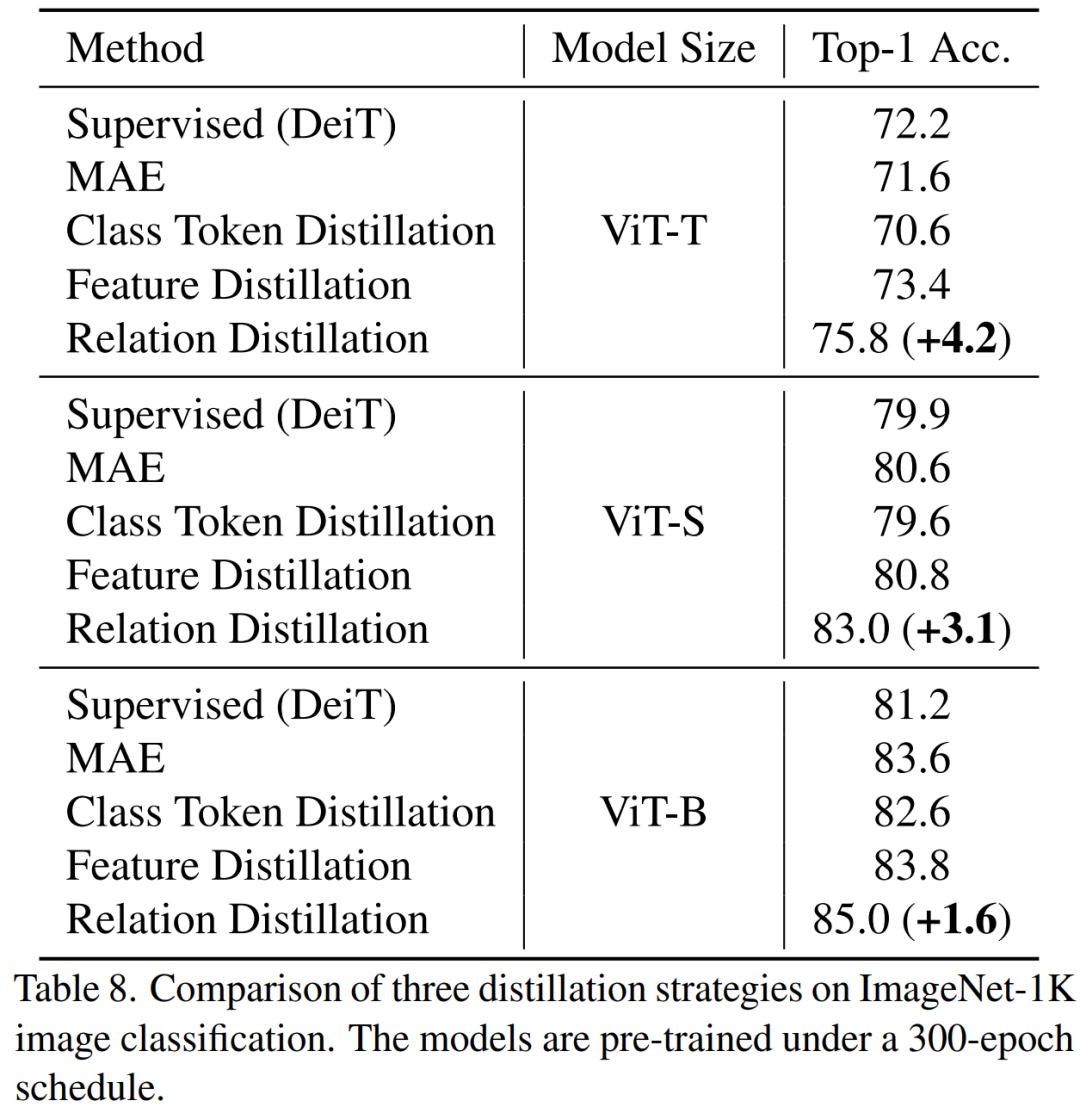
3.1 Principaux résultats expérimentaux Notre méthode est pré-entraînée sur ImageNet- 1K, et le modèle d'enseignant est également pré-entraîné sur ImageNet-1K. Nous avons ensuite affiné notre modèle pré-entraîné sur les tâches en aval (classification, segmentation sémantique). Les performances du modèle sont telles qu'indiquées sur la figure : Notre méthode surpasse considérablement les précédentes méthodes basées sur MAE, en particulier pour les petits modèles. Plus précisément, pour le modèle ultra-petit ViT-T, notre méthode atteint une précision de classification de 75,8 %, soit une amélioration de 4,2 par rapport au modèle de base MAE. Pour le petit modèle ViT-S, nous obtenons une précision de classification de 83,0 %, soit une amélioration de 1,4 par rapport à la meilleure méthode précédente. Pour les modèles de taille de base, notre méthode surpasse le modèle de base MAE et le meilleur modèle précédent de CAE 4.1 et 2.0, respectivement. En parallèle, nous avons également testé la robustesse du modèle, comme le montre la figure :
TinyMIM-B par rapport à MAE-B, dans ImageNet -A et ImageNet-R améliorés respectivement de +6,4 et +4,6. 3.2 Expérience d'ablation1) Distiller différentes relations
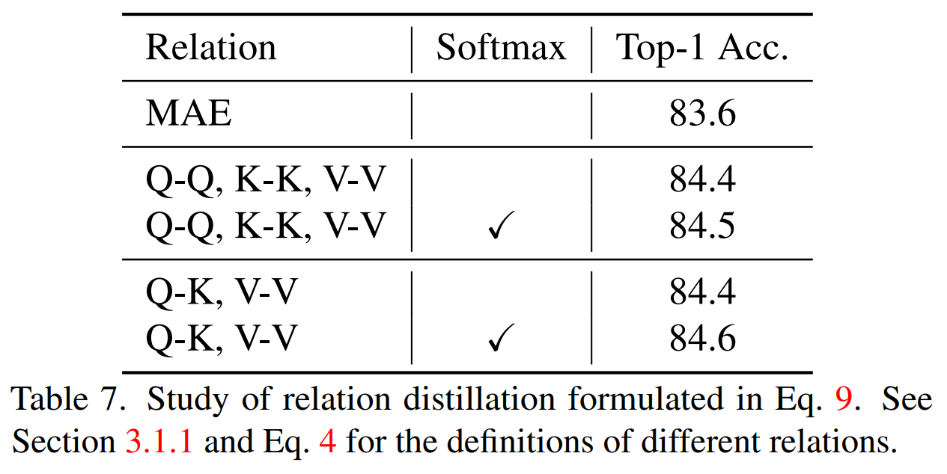
Simultane La distillation systématique de la relation QK, V V et Softmax est mise en œuvre lors du calcul de la relation Best. résultats. 2) Différentes stratégies de distillation
TinyMIM Cette méthode de distillation des relations permet d'obtenir de meilleurs résultats que le modèle de base MAE, la distillation de jetons de classe et la distillation par carte de caractéristiques. L'effet est le idem sur les modèles de toutes tailles. 3) Couche intermédiaire de distillation
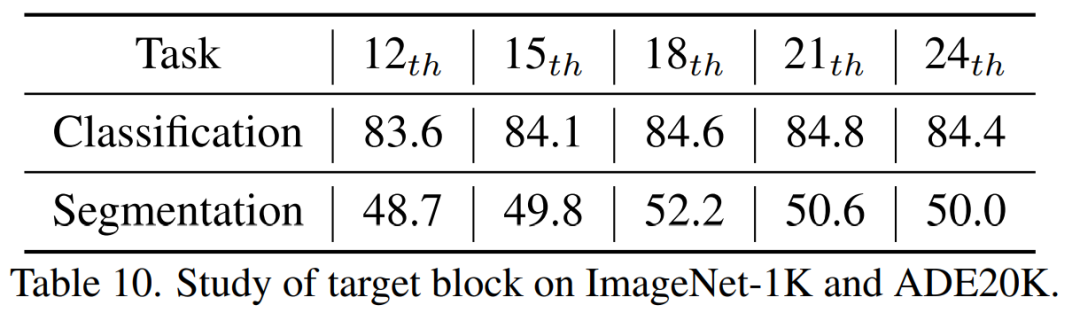
Nous avons constaté que la dix-huitième couche de distillation obtenait les meilleurs résultats. Dans cet article, nous avons proposé TinyMIM, qui est le premier modèle qui permet avec succès aux petits modèles de bénéficier d'une pré-formation en modélisation de reconstruction de masque (MIM). Au lieu d'adopter la reconstruction de masque comme tâche, nous pré-entraînons le petit modèle en l'entraînant pour simuler les relations du grand modèle de manière à distiller les connaissances. Le succès de TinyMIM peut être attribué à une étude approfondie de divers facteurs pouvant affecter la pré-formation TinyMIM, notamment les objectifs de distillation, les intrants de distillation et les couches intermédiaires. Grâce à des expériences approfondies, nous concluons que la distillation relationnelle est supérieure à la distillation de caractéristiques et à la distillation d'étiquettes de classe, etc. Grâce à sa simplicité et à ses performances puissantes, nous espérons que notre méthode fournira une base solide pour les recherches futures. [1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022) L'apprentissage contrasté rivalise avec la modélisation d'images masquées en affinant via la distillation des fonctionnalités arXiv pré-imprimée arXiv : 2205.14141..Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!