
Maison >Périphériques technologiques >IA >Technologie universelle d'amélioration des données, la quantification aléatoire convient à toutes les modalités de données
Technologie universelle d'amélioration des données, la quantification aléatoire convient à toutes les modalités de données

- 王林avant
- 2023-09-06 12:13:101321parcourir
Les algorithmes d'apprentissage auto-supervisé ont fait des progrès significatifs dans des domaines tels que le traitement du langage naturel et la vision par ordinateur. Bien que ces algorithmes d’apprentissage auto-supervisés soient conceptuellement généraux, leurs opérations spécifiques reposent sur des modalités de données spécifiques. Cela signifie que différents algorithmes d’apprentissage auto-supervisés doivent être développés pour différentes modalités de données. À cette fin, cet article propose une technique générale d’augmentation des données qui peut être appliquée à n’importe quelle modalité de données. Par rapport à l'apprentissage auto-supervisé à usage général existant, cette méthode peut permettre d'obtenir des améliorations significatives des performances et peut remplacer une série de méthodes complexes d'amélioration des données conçues pour des modalités spécifiques et obtenir des performances similaires.

- Adresse papier : https://arxiv.org/abs/2212.08663
- Code : https://github.com/microsoft/random_quantize
Présentation
Contenu réécrit : Actuellement, l'apprentissage des représentations siamoises/l'apprentissage contrasté nécessite l'utilisation de techniques d'augmentation de données pour construire différents échantillons des mêmes données et les saisir dans deux structures de réseau parallèles pour générer un signal de supervision suffisamment fort. Cependant, ces techniques d’augmentation des données s’appuient généralement fortement sur des connaissances préalables spécifiques à la modalité, nécessitant souvent une conception manuelle ou la recherche de la meilleure combinaison adaptée à la modalité actuelle. En plus d’être longues et exigeantes en main-d’œuvre, les meilleures méthodes d’augmentation des données trouvées sont également difficiles à transférer à d’autres domaines. Par exemple, l'instabilité des couleurs courante pour les images RVB naturelles ne peut pas être appliquée à d'autres modalités de données, à l'exception des images naturelles. De manière générale, les données d'entrée peuvent être représentées sous la forme d'un binaire composé de dimensions de séquence et de dimensions de canal. La dimension séquence est souvent liée à la modalité des données, comme la dimension spatiale des images, la dimension temporelle de la parole et la dimension syntaxique du langage. La dimension du canal est indépendante de la modalité. Dans l'apprentissage auto-supervisé, la modélisation de l'occlusion ou l'utilisation de l'occlusion comme augmentation des données est devenue une méthode d'apprentissage efficace. Cependant, ces opérations sont effectuées sur la dimension séquence. Afin d'être largement applicable aux différentes modalités de données, cet article propose une méthode d'amélioration des données qui agit sur la dimension du canal : la quantification aléatoire. En quantifiant dynamiquement les données dans chaque canal à l'aide d'un quantificateur non uniforme, les valeurs quantifiées sont échantillonnées de manière aléatoire à partir d'intervalles divisés de manière aléatoire. De cette façon, la différence d'informations de l'entrée d'origine dans le même intervalle est supprimée, tout en conservant la taille relative des données dans différents intervalles, obtenant ainsi l'effet de masquage
Cette méthode peut être utilisée dans diverses données modalités Il surpasse les méthodes d'apprentissage auto-supervisées existantes dans toutes les modalités, y compris les images naturelles, les nuages de points 3D, la parole, le texte, les données de capteurs, les images médicales, etc. Dans une variété de tâches d'apprentissage préalable à la formation, telles que l'apprentissage contrastif (comme MoCo-v3) et l'apprentissage auto-supervisé par auto-distillation (comme BYOL), les fonctionnalités apprises sont meilleures que les méthodes existantes. La méthode a également été validée pour différentes structures de réseau fédérateur telles que CNN et Transformer. 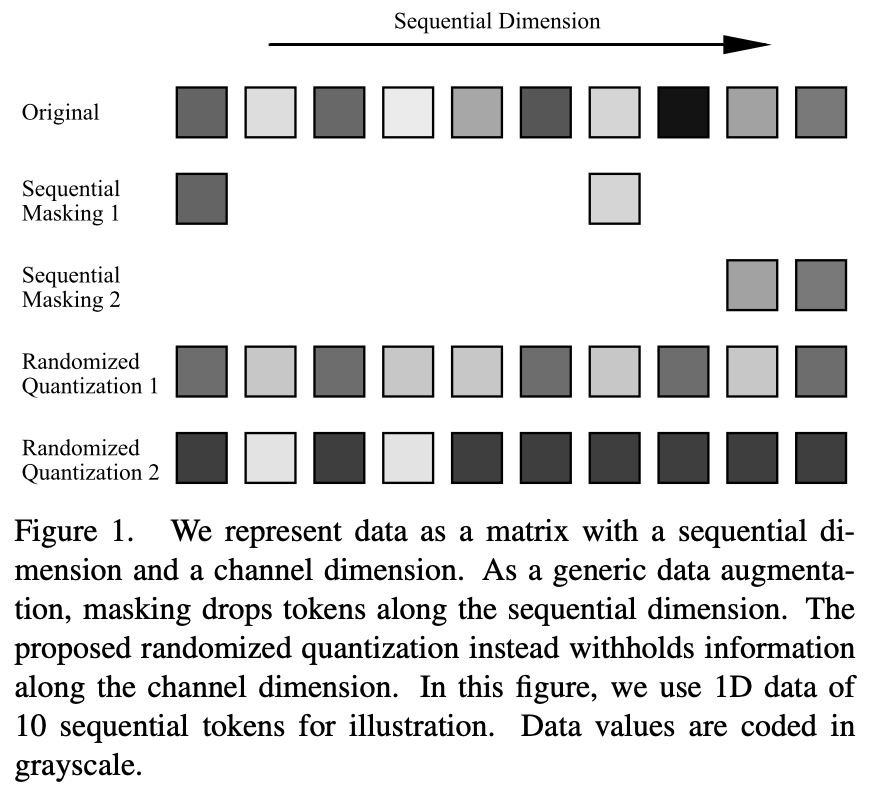
Méthode
La quantification fait référence à l'utilisation d'un ensemble de valeurs discrètes pour représenter des données continues afin de faciliter le stockage, le fonctionnement et la transmission efficaces des données. Cependant, l'objectif général des opérations de quantification est de compresser les données sans perdre en précision. Le processus est donc déterministe et conçu pour être aussi proche que possible des données d'origine. Cela limite sa force en tant que moyen d'amélioration et la richesse des données de sa production.
Cet article propose une opération de quantification aléatoire, qui divise indépendamment les données de chaque canal d'entrée en plusieurs intervalles aléatoires qui ne se chevauchent pas (
), et divise l'entrée d'origine tombant dans chaque intervalle en une constante 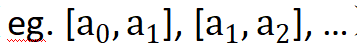 échantillonnée de manière aléatoire de l'intervalle.
échantillonnée de manière aléatoire de l'intervalle. 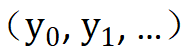
La capacité de la quantification aléatoire en tant que masquage des données de dimension de canal dans les tâches d'apprentissage auto-supervisées dépend de la conception des trois aspects suivants : 1) division aléatoire des intervalles numériques 2) échantillonnage aléatoire des valeurs de sortie et 3 ; ) nombre d'intervalles numériques divisés. 
Plus précisément, le processus aléatoire apporte des échantillons plus riches, et les mêmes données peuvent générer des échantillons de données différents à chaque fois qu'une opération de quantification aléatoire est effectuée. Dans le même temps, le processus aléatoire apporte également une plus grande amélioration aux données d'origine. Par exemple, de grands intervalles de données sont divisés de manière aléatoire, ou lorsque le point de mappage s'écarte du point médian de l'intervalle, l'entrée et la sortie d'origine peuvent être modifiées. tomber entre l'intervalle.
En réduisant de manière appropriée le nombre d'intervalles divisés, l'intensité de l'amélioration peut être facilement augmentée. De cette manière, lorsqu'elles sont appliquées à l'apprentissage des représentations siamoises, les deux branches du réseau sont capables de recevoir des données d'entrée avec suffisamment de différences d'informations, construisant ainsi un signal d'apprentissage fort qui facilite l'apprentissage des fonctionnalités
La figure ci-dessous visualise différents modèles de données L'effet de en utilisant cette méthode d'augmentation des données :
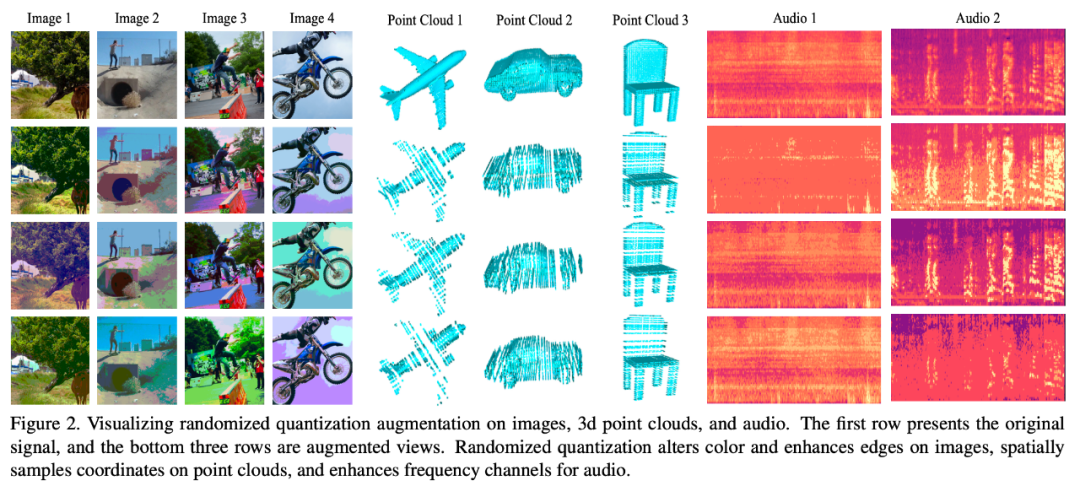
Résultats expérimentaux
Le contenu réécrit est : Mode 1 : Image
Cet article est évalué sur l'ensemble de données ImageNet-1K. L'effet de la quantification aléatoire appliquée à MoCo-v3 et BYOL, l'indice d'évaluation est une évaluation linéaire. Lorsqu'elle est utilisée seule comme seule méthode d'augmentation des données, c'est-à-dire que l'augmentation dans cet article est appliquée au recadrage central de l'image d'origine, et lorsqu'elle est utilisée conjointement avec le recadrage aléatoire redimensionné (RRC), cette méthode a obtenu de meilleurs résultats. que les méthodes d’étude générales auto-supervisées existantes pour de meilleurs résultats.
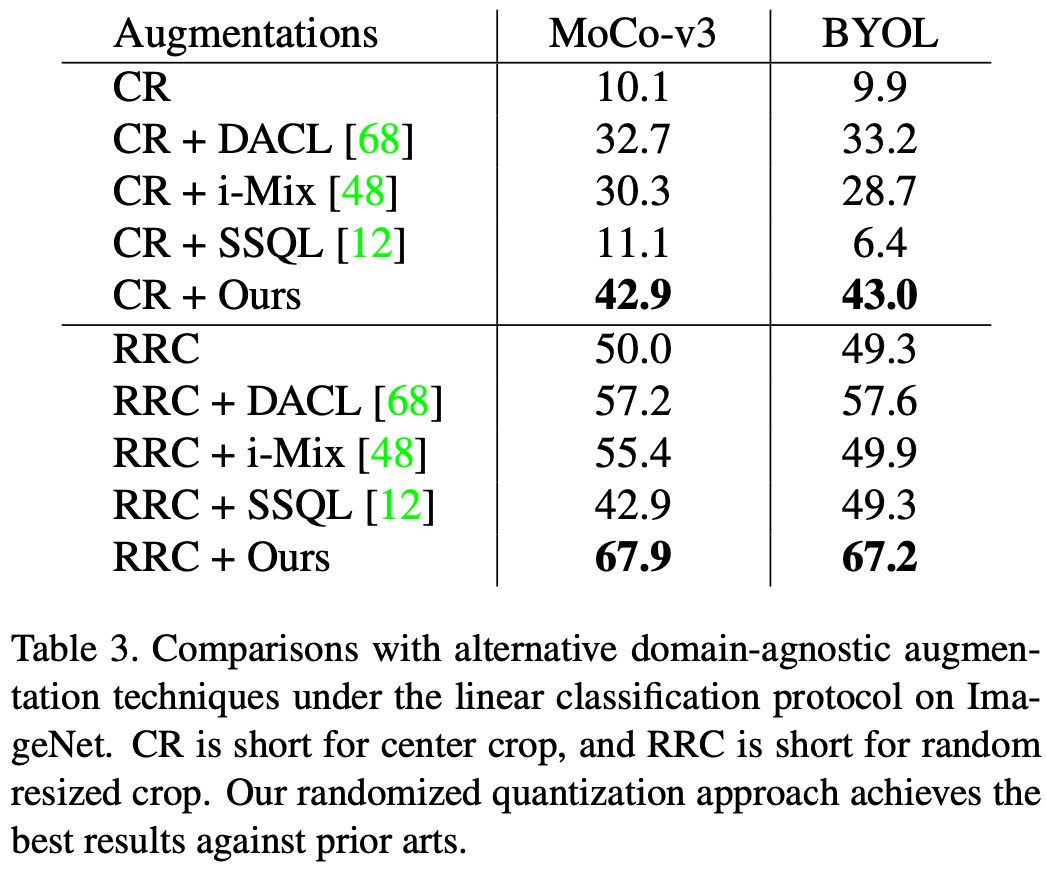
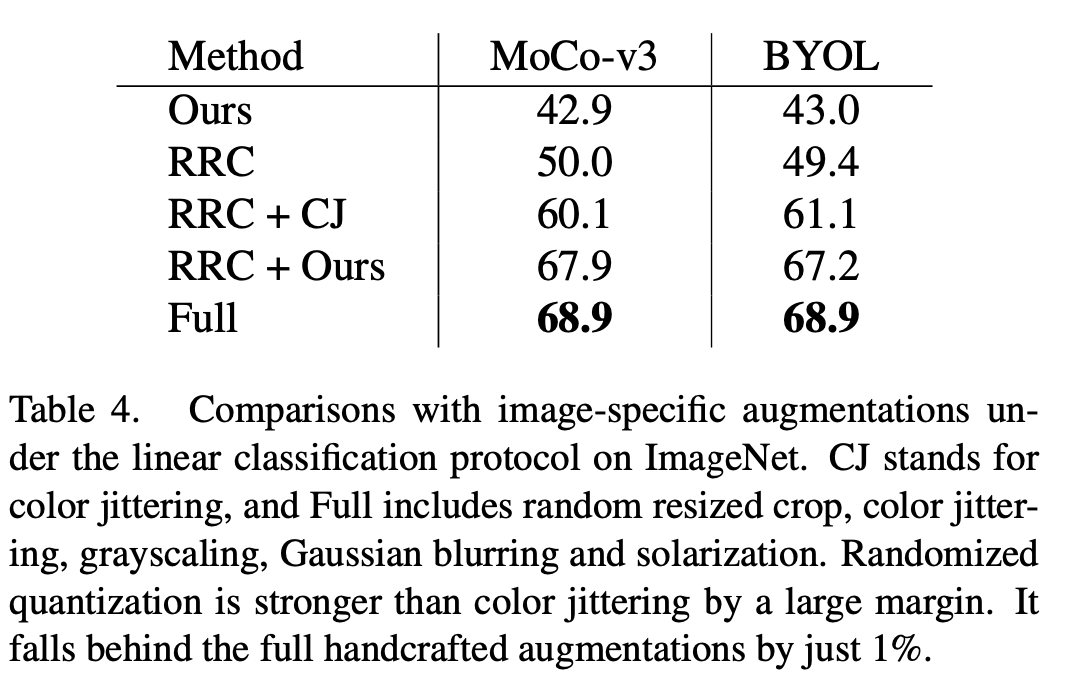
Par rapport aux méthodes d'amélioration des données existantes développées pour les données d'image, telles que le jittering des couleurs (CJ), la méthode décrite dans cet article présente des avantages évidents en termes de performances. Dans le même temps, cette méthode peut également remplacer une série de méthodes complexes d'amélioration des données (complètes) dans MoCo-v3/BYOL, notamment l'instabilité des couleurs, l'échelle de gris aléatoire, le flou gaussien aléatoire, l'exposition aléatoire (solarisation) et obtenir des effets similaires à méthodes complexes d’amélioration des données.
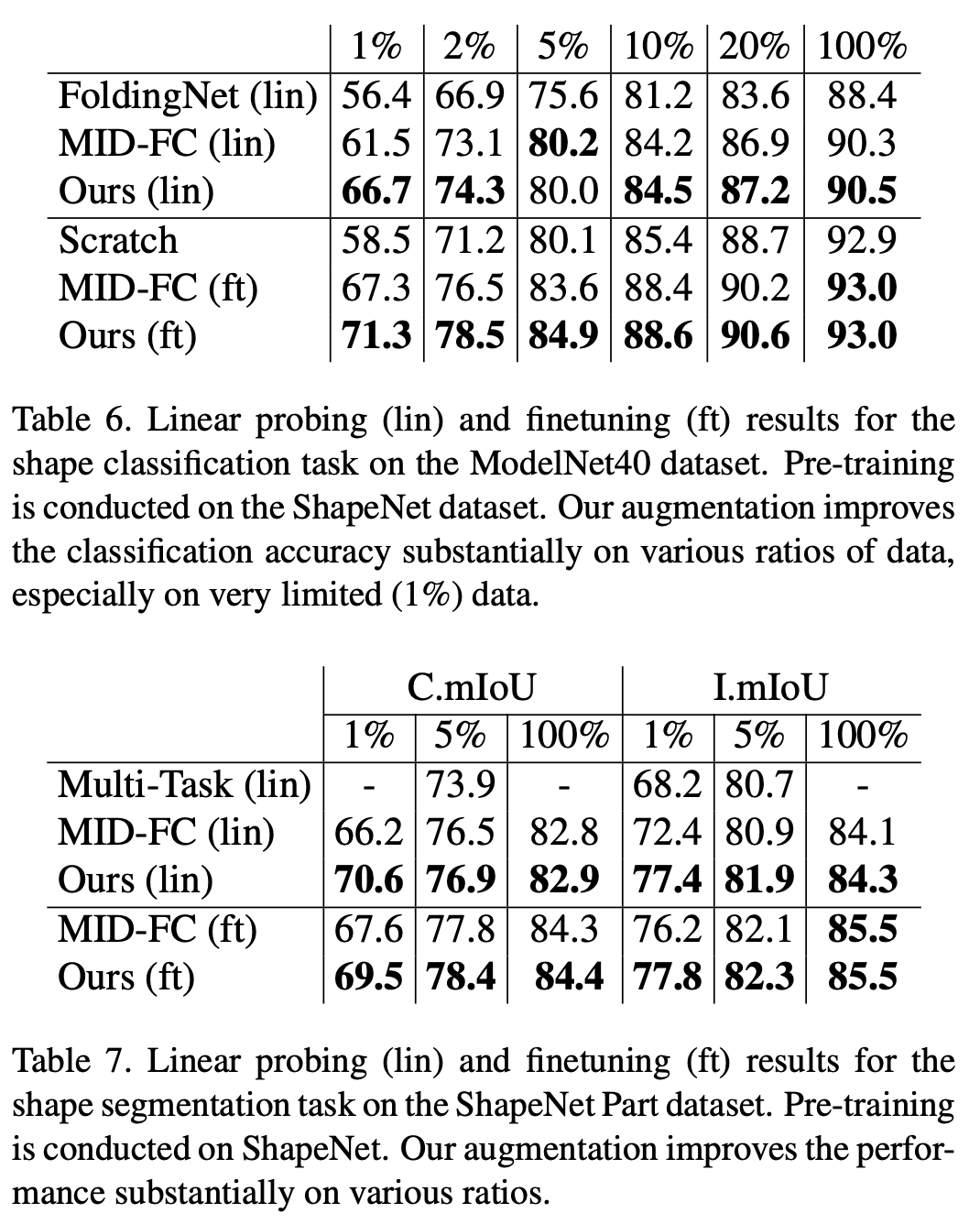
Le contenu qui doit être réécrit est : Mode 2 : nuage de points 3D
Dans la tâche de classification de l'ensemble de données ModelNet40 et la tâche de segmentation de l'ensemble de données ShapeNet Part, cette étude a vérifié des résultats aléatoires quantification Supériorité par rapport aux méthodes auto-supervisées existantes. Surtout lorsque la quantité de données dans l'ensemble de formation en aval est faible, la méthode de cette étude dépasse largement l'algorithme auto-supervisé de nuage de points existant
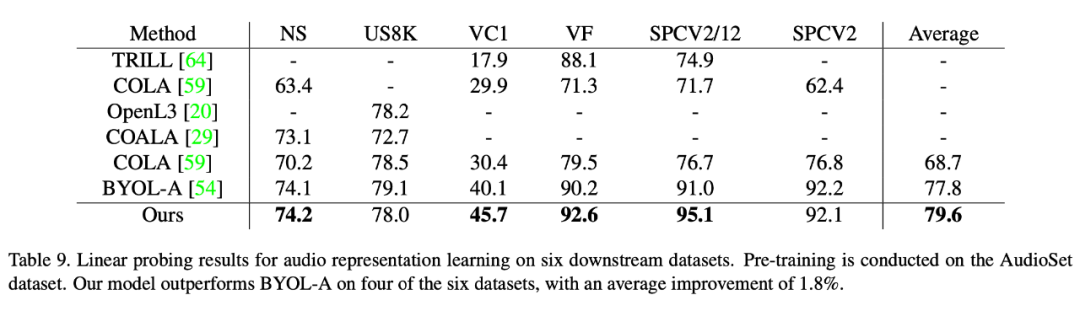
Contenu réécrit : La troisième modalité : la parole
Cette méthode permet également d'obtenir de meilleures performances que les méthodes d'apprentissage auto-supervisées existantes sur des ensembles de données vocales. Cet article vérifie la supériorité de cette méthode sur six ensembles de données en aval. Parmi eux, sur l'ensemble de données le plus difficile VoxCeleb1 (qui contient le plus grand nombre de catégories et dépasse de loin le nombre d'autres ensembles de données), cette méthode a permis d'obtenir une amélioration significative des performances. (5,6 points).
Le contenu réécrit est : Mode 4 : DABS
DABS est un benchmark général d'apprentissage auto-supervisé, couvrant une variété de données modales, notamment des images naturelles, du texte, de la parole, des capteurs. données, images et graphiques médicaux, etc. Notre méthode est également meilleure que n'importe quelle méthode d'apprentissage modal auto-supervisé existante sur diverses données modales différentes couvertes par DABS

Les lecteurs intéressés peuvent lire l'article original pour comprendre le contenu de la recherche. Détails
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!