
Maison >Périphériques technologiques >IA >Utilisez BigDL-LLM pour accélérer instantanément des dizaines de milliards d'inférences de paramètres LLM
Utilisez BigDL-LLM pour accélérer instantanément des dizaines de milliards d'inférences de paramètres LLM

- 王林avant
- 2023-09-05 13:49:041299parcourir
Nous entrons dans une nouvelle ère d'IA pilotée par Large Language Model (LLM). LLM joue un rôle de plus en plus important dans diverses applications telles que le service client, les assistants virtuels, la création de contenu, l'aide à la programmation, etc.
Cependant, à mesure que l'échelle du LLM continue de croître, la consommation de ressources nécessaire à l'exécution de grands modèles augmente également, ce qui rend son fonctionnement de plus en plus lent, ce qui pose des défis considérables aux développeurs d'applications d'IA.
À cette fin, Intel a récemment lancé une bibliothèque open source de grands modèles appelée BigDL-LLM[1], qui peut aider les développeurs et les chercheurs en IA à accélérer l'optimisation des grands modèles de langage sur la plate-forme Intel® et à améliorer L'expérience de l'utilisation de grands modèles de langage sur la plateforme Intel ® .

Ce qui suit montre le modèle de langage large de 33 milliards de paramètres Vicuna-33b-v1.3[2] qui est accéléré à l'aide de BigDL-LLM sur une machine équipée d'Intel® Xeon® Platinum 8468. Le processeur exécute les effets en temps réel sur le serveur.
△Vitesse réelle d'exécution d'un grand modèle de langage de 33 milliards de paramètres sur un serveur équipé d'un processeur Intel® Xeon® Platinum 8468 (enregistrement d'écran en temps réel)
BigDL-LLM : Intel® Bibliothèque d'accélération de grands modèles de langage open source sur la plate-forme
BigDL-LLM est une bibliothèque open source axée sur l'optimisation et l'accélération de grands modèles de langage. Elle fait partie de BigDL et est publiée sous la licence Apache 2.0
Elle fournit une variété de modèles de langage faibles. niveau d'optimisation de précision (telle que INT4/INT5/INT8), et peut utiliser une variété de technologies d'accélération matérielle intégrées au processeur Intel® (AVX/VNNI/AMX, etc.) et la dernière optimisation logicielle pour permettre de grands modèles de langage sur Intel® Obtenez une optimisation plus efficace et un fonctionnement plus rapide sur la plate-forme.
Une caractéristique importante de BigDL-LLM est que pour les modèles basés sur l'API Hugging Face Transformers, il vous suffit de modifier une ligne de code pour accélérer le modèle. En théorie, il peut prendre en charge l'exécution de n'importe quelModèle Transformers, ce qui est utile pour ceux qui connaissent Transformers. Les développeurs d'API sont très sympathiques.
En plus de l'API Transformers, de nombreuses personnes utilisent également LangChain pour développer de grandes applications de modèle de langage.
À cette fin, BigDL-LLM fournit également une intégration LangChain facile à utiliser[3], permettant aux développeurs d'utiliser facilement BigDL-LLM pour développer de nouvelles applications ou migrer des applications existantes basées sur l'API Transformers ou l'API LangChain.
De plus, pour les grands modèles de langage PyTorch généraux (modèles qui n'utilisent pas l'API Transformer ou LangChain), vous pouvez également utiliser l'accélération en un clic de l'API BigDL-LLM optimise_model pour améliorer les performances. Pour plus de détails, veuillez vous référer au README GitHub[4] et à la documentation officielle[5].
BigDL-LLM fournit également un grand nombre d'échantillons d'accélération LLM open source couramment utilisés (par exemple, des échantillons utilisant l'API Transformers[6] et des échantillons utilisant l'API LangChain[7], ainsi que des didacticiels (y compris la prise en charge des notebooks Jupyter) [8], pratique pour les développeurs qui souhaitent démarrer et l'essayer rapidement
Installation et utilisation : processus d'installation simple et interface API facile à utiliser
Il est très pratique d'installer BigDL-LLM, exécutez simplement ce qui suit commande :
pip install --pre --upgrade bigdl-llm[all]
△Si le code n'est pas entièrement affiché, veuillez glisser vers la gauche ou la droite
Il est également très simple d'utiliser BigDL-LLM pour accélérer de grands modèles (ici nous utilisons uniquement l'API de style Transformers à titre d'exemple)
Utilisez l'API de style BigDL-LLM Transformer. Pour accélérer le modèle, il vous suffit de modifier la partie de chargement du modèle. Le processus d'utilisation ultérieur est complètement le même que celui des Transformers natifs. L'utilisation de l'API BigDL-LLM est presque la même que celle de l'API Transformers - l'utilisateur n'a qu'à modifier l'importation et à la définir dans le paramètre from_pretrained
load_in_4bit=True BigDL-LLM effectuera un low-4 bits. quantification de précision pendant le processus de chargement du modèle et utilisation de diverses technologies d'accélération logicielle et matérielle pour l'optimisation lors du processus d'inférence ultérieur
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
△ Si le code n'est pas entièrement affiché, veuillez glisser vers la gauche ou la droite 下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分: 以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程: 在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。 只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。 △若代码显示不全,请左右滑动 第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。 △若代码显示不全,请左右滑动 在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。 可以使用这个 API 来加载 Hugging Face Transformers 的任何模型 △若代码显示不全,请左右滑动 然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。 △若代码显示不全,请左右滑动 以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下: △若代码显示不全,请左右滑动 最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧! 黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作示例:快速实现一个基于大语言模型的语音助手应用
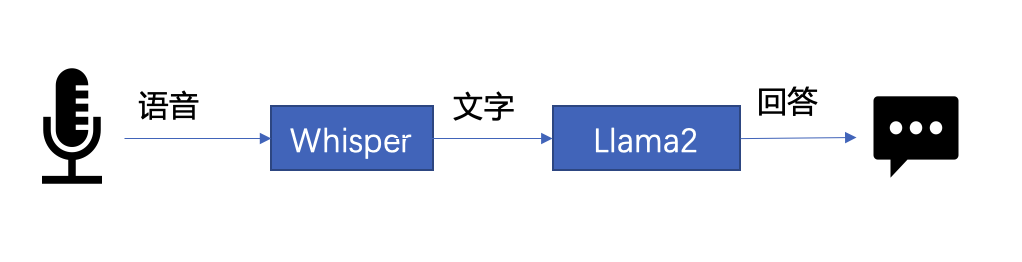
△图 1. 语音助手工作流程示意
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
作者简介
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les types de données simples en langage C ?
- Comment créer une base de données dans MySQL
- La chaîne industrielle de l'intelligence artificielle comprend
- À quelle catégorie appartient l'intelligence artificielle ?
- Quelles sont les caractéristiques d'application de la technologie de l'intelligence artificielle dans l'armée ?