
Maison >développement back-end >C++ >Traitement en plusieurs étapes des programmes utilisateur
Traitement en plusieurs étapes des programmes utilisateur

- 王林avant
- 2023-08-31 16:45:201523parcourir
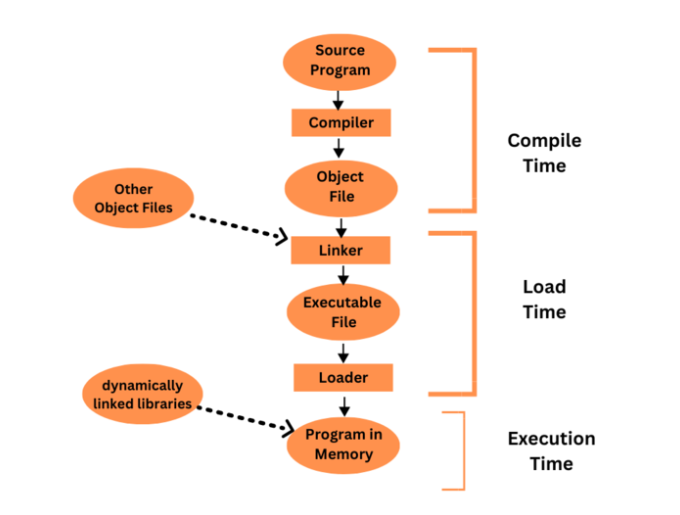
Le système informatique doit convertir le programme de langage de programmation de haut niveau de l'utilisateur en code machine afin que le processeur de l'ordinateur puisse l'exécuter. Le multi-stepping est un terme utilisé pour décrire les multiples processus impliqués dans la conversion d'un programme utilisateur en code exécutable.
Les programmes utilisateur passent généralement par de nombreuses étapes différentes au cours de leur traitement en plusieurs étapes, notamment l'analyse lexicale, l'analyse syntaxique, l'analyse sémantique, la création de code, l'optimisation et la liaison. Chaque étape est essentielle pour convertir un programme utilisateur d'un formulaire de haut niveau en code machine pouvant s'exécuter sur un système informatique.
Programme utilisateur
Contrairement aux composants d'un système d'exploitation ou d'un autre logiciel système, les programmes utilisateur sont des programmes informatiques écrits et exécutés par les utilisateurs. La plupart du temps, les programmes utilisateur sont créés dans des langages de programmation de haut niveau et sont conçus pour effectuer des activités spécifiques, telles que le traitement de données, la gestion de fichiers ou l'interaction avec l'interface utilisateur.
Les applications de productivité telles que les éditeurs de texte, les navigateurs Web, les lecteurs de musique et les logiciels de feuilles de calcul et de présentation sont quelques exemples de programmes utilisateur. Les utilisateurs installent et exécutent généralement ces programmes sur des systèmes informatiques pour effectuer une tâche spécifique ou un ensemble de responsabilités.
Les programmes utilisateur peuvent être créés à l'aide de divers langages de programmation, notamment C, C++, Java, Python ou JavaScript. Selon la plateforme cible et le langage de programmation, ils peuvent être compilés ou interprétés. Une fois le programme utilisateur créé, il peut être publié en ligne pour téléchargement ou distribué à d'autres utilisateurs.
Lier l'adresse à la mémoire
Le processus de mappage des adresses logiques utilisées par un programme avec des adresses physiques dans la mémoire de l'ordinateur est appelé liaison des adresses à la mémoire. Le système informatique doit savoir où charger les instructions et les données du programme en mémoire. Ce processus est donc essentiel à l'exécution du programme.
Il existe trois types de liaison de mémoire pour les adresses -
Liaison au moment de la compilation - Les liaisons qui sont déterminées au moment de la compilation et restent inchangées pendant l'exécution du programme sont appelées liaisons au moment de la compilation. Ces adresses exactes sont incluses dans le code machine généré et le système d'exploitation charge simplement ce code en mémoire.
Liaison au temps de chargement - Dans cette liaison, les adresses mémoire des variables et des instructions sont choisies lors du chargement du programme. Le système d'exploitation charge le code en mémoire, convertit les références symboliques en adresses physiques, puis exécute le programme. Le compilateur crée du code déplaçable qui contient des références symboliques aux emplacements mémoire.
Runtime Binding - Dans cette liaison, les adresses mémoire des variables et des instructions sont sélectionnées selon les besoins. Avec cette stratégie, la mémoire peut être allouée dynamiquement selon les besoins pendant l'exécution du programme. Cette liaison est généralement utilisée par les programmes qui utilisent des bibliothèques dynamiques ou des plug-ins.
Compiler
Le processus de conversion du code source écrit dans un langage de programmation de haut niveau en langage machine afin qu'un ordinateur puisse l'exécuter est appelé compilation. Cette traduction est effectuée par un programme informatique appelé compilateur. Un fichier exécutable ou objet pouvant être exécuté sur le système cible est généralement la sortie d'un compilateur.
Analyse lexicale, analyse syntaxique, analyse sémantique, création et optimisation de code sont quelques-unes des étapes du processus de compilation. Vous trouverez ci-dessous une brève description de chaque étape -
Analyse lexicale - Cette étape nécessite que le code source soit marqué comme mots-clés, identifiants, littéraux, opérateurs, etc.
Analyse de la syntaxe - Analyser la syntaxe d'un programme pour s'assurer qu'il est conforme aux règles du langage de programmation est la tâche de la phase d'analyse syntaxique. Comparez-le à la syntaxe d'un langage de programmation de manière à garantir que la syntaxe crée un programme valide.
Analyse sémantique - Cette étape vérifie la signification ou la sémantique du programme. Il garantit que le programme respecte les restrictions du langage sur les types de variables, les appels de fonction et d'autres sujets.
Génération de code - Cette étape nécessite la conversion du code source en code machine ou code assembleur. Le code généré est immédiatement exécutable par le processeur de l'ordinateur et est souvent personnalisé pour la plateforme cible.
Optimisation - Durant cette phase, le code sera modifié pour améliorer les performances. Pour réduire le nombre d'instructions requises pour exécuter un programme, le compilateur peut utiliser des techniques d'optimisation telles que le déroulement de boucles, l'insertion de fonctions et le déplacement de code.
Cas d'utilisation pour le traitement en plusieurs étapes des programmes utilisateur
Compilation de langages de programmation - Le principal cas d'utilisation du traitement en plusieurs étapes consiste à compiler des langages de programmation de haut niveau en code machine. Cela permet aux utilisateurs d'écrire des programmes dans un langage expressif et lisible par l'homme et de les traduire en code exécutable pouvant s'exécuter sur un système informatique.
Détection d'erreurs et débogage - Les erreurs et les incohérences dans les programmes utilisateur sont détectées à différentes étapes du traitement en plusieurs étapes, telles que l'analyse lexicale, l'analyse syntaxique et l'analyse sémantique. Cela permet d'identifier et de déboguer les problèmes dès le début du processus de développement, garantissant ainsi l'exactitude et la fiabilité du programme.
Optimisation des performances du programme - La phase d'optimisation du traitement en plusieurs étapes se concentre sur l'amélioration des performances du programme. Grâce à des techniques telles que la réorganisation du code, le déroulement des boucles et l'intégration de fonctions, le compilateur peut générer un code optimisé qui s'exécute plus efficacement, ce qui donne lieu à des programmes plus rapides et plus efficaces.
Génération de code spécifique à la plate-forme - L'étape de génération de code d'un processus en plusieurs étapes convertit les programmes de haut niveau en code machine ou en code assembleur spécifique à la plate-forme cible. Cela permet aux programmes d'utiliser efficacement les ressources et les capacités de l'architecture matérielle sous-jacente pour des performances et une compatibilité optimales.
Intégration avec des bibliothèques externes - La phase de liaison dans un traitement en plusieurs étapes consiste à combiner le programme utilisateur avec des bibliothèques ou des modules externes. Cela permet à un programme de tirer parti des fonctionnalités et des ressources préexistantes, en étendant ses capacités sans avoir à réinventer la roue. Il permet aux développeurs d'exploiter le vaste écosystème de bibliothèques disponibles dans l'écosystème des langages de programmation.
Exemple
Le code C ci-dessous montre un programme simple qui calcule la somme de deux entiers et imprime le résultat. Les variables a et b sont initialisées aux valeurs 5 et 10 respectivement, et leur somme est stockée dans la somme variable. La fonction printf permet d'afficher la somme au format souhaité.
#include <stdio.h>
int main() {
int a = 5;
int b = 10;
int sum = a + b;
printf("The sum of %d and %d is %d\n", a, b, sum);
return 0;
}
Sortie
La sortie du programme sera :
"The sum of 5 and 10 is 15"
Conclusion
Le processus de conversion d'un langage de programmation de haut niveau en langage machine exécutable par ordinateur est appelé traitement en plusieurs étapes des programmes utilisateur. L'analyse lexicale, l'analyse syntaxique, l'analyse sémantique, la génération de code, l'optimisation, la liaison, le chargement et l'exécution sont quelques-unes des étapes qui composent ce processus. Pour garantir que le programme de l'utilisateur est sans erreur, optimisé et prêt à être exécuté, chaque étape effectue des tâches spécifiées. Un fichier exécutable ou objet pouvant être exécuté sur la plate-forme cible est généralement une sortie de processus. Comprendre ce processus est essentiel pour que les développeurs de logiciels puissent produire des programmes efficaces et optimisés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!