Hier, Meta a open source le modèle de base spécialisé dans la génération de code Code Llama, qui peut être utilisé gratuitement à des fins de recherche et commerciales. Les modèles de la série Code Llama ont trois versions de paramètres, avec des quantités de paramètres de 7B, 13B et 34B respectivement. Et prend en charge plusieurs langages de programmation, notamment Python, C++, Java, PHP, Typescript (Javascript), C# et Bash. Meta fournit des versions de Code Llama comprenant :
Code Llama, modèle de code de base
Code Sheep-Python, une version affinée de Python
Code Llama-Instruct, naturel ; Version de réglage fin de l'enseignement du langage
En termes d'efficacité, le taux de réussite de la génération unique (pass@1) des différentes versions de Code Llama sur les ensembles de données HumanEval et MBPP dépasse GPT-3.5. De plus, le pass@1 de la version « Unnatural » 34B de Code Llama sur l'ensemble de données HumanEval est proche de GPT-4 (62,2 % contre 67,0 %). Cependant, Meta n'a pas publié cette version, mais des améliorations significatives des performances ont été obtenues grâce à la formation sur un petit ensemble de données codées de haute qualité.  Source de l'image : https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Source de l'image : https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Juste après un jour, un chercheur a fait rapport à GPT-4 Un défi a été lancé. Ils viennent de Phind (une organisation qui vise à créer un moteur de recherche d'IA pour les développeurs), et la recherche a utilisé Code Llama-34B finement réglé pour battre GPT-4 dans l'évaluation HumanEval. Le co-fondateur de Phind, Michael Royzen, a déclaré : « Il ne s'agit que d'une première expérience, visant à reproduire (et surpasser) les résultats du « Unnatural Code Llama » dans l'article Meta. À l'avenir, nous disposerons d'un portefeuille expert de différents modèles CodeLlama qui, je pense, seront compétitifs dans les flux de travail du monde réel. ”
Les deux modèles ont été open source :
Les chercheurs ont publié ces deux modèles sur Huggingface, vous pouvez aller les découvrir.
- Phind-CodeLlama-34B-v1 : https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind-CodeLlama-34B-Python-v1 : https://huggingface.co /Phind/Phind-CodeLlama-34B-Python-v1
Voyons ensuite comment cette recherche a été mise en œuvre. Code Llama-34B affiné pour battre GPT-4Regardons d'abord les résultats. Cette étude a utilisé des ensembles de données internes de Phind pour affiner Code Llama-34B et Code Llama-34B-Python, ce qui a abouti à deux modèles Phind-CodeLlama-34B-v1 et Phind-CodeLlama-34B-Python-v1 respectivement. Les deux modèles nouvellement obtenus ont obtenu respectivement 67,6% et 69,5% de pass@1 sur HumanEval. À titre de comparaison, CodeLlama-34B pass@1 est de 48,8 % ; CodeLlama-34B-Python pass@1 est de 53,7 %. Et le pass@1 de GPT-4 sur HumanEval est de 67 % (données publiées par OpenAI dans le « Rapport technique GPT-4 » publié en mars de cette année). Source de l'image : https://ai.meta.com/blog/code-llama-large-langue-model-coding/
Source de l'image : https://cdn. openai.com/papers/gpt-4.pdf
En parlant de réglage fin, bien sûr, les ensembles de données sont indispensables. Cette étude a affiné Code Llama-34B et Code Llama-34B-Python sur un ensemble de données propriétaire contenant environ 80 000 problèmes et solutions de programmation de haute qualité. Cet ensemble de données ne prend pas d'exemples de complétion de code mais des paires instruction-réponse, ce qui est différent de la structure de données HumanEval. L’étude a ensuite entraîné le modèle Phind sur deux époques, avec un total d’environ 160 000 exemples. Les chercheurs ont déclaré que la technologie LoRA n’avait pas été utilisée dans la formation, mais qu’un réglage local avait été utilisé. De plus, l'étude a également utilisé les technologies DeepSpeed ZeRO 3 et Flash Attention 2. Ils ont passé trois heures sur 32 GPU A100-80GB pour entraîner ces modèles, avec une longueur de séquence de 4096 jetons. De plus, l'étude a également appliqué la méthode de décontamination d'OpenAI à l'ensemble de données pour rendre les résultats du modèle plus efficaces. Il est bien connu que même le très puissant GPT-4 sera confronté au dilemme de la pollution des données. En termes simples, le modèle entraîné peut avoir été entraîné sur les données d'évaluation. Ce problème est très difficile pour le LLM. Par exemple, dans le processus d'évaluation des performances d'un modèle, afin de faire une évaluation scientifiquement crédible, le chercheur doit vérifier si le problème utilisé pour l'évaluation est dans la formation. données du modèle. Si tel est le cas, le modèle peut mémoriser ces problèmes et sera évidemment plus performant sur ces problèmes spécifiques lors de l’évaluation du modèle. C'est comme si une personne connaissait les questions de l'examen avant de passer l'examen. Afin de résoudre ce problème, OpenAI a révélé comment GPT-4 évalue la pollution des données dans le document technique public GPT-4 "GPT-4 Technical Report". Ils dévoilent leurs stratégies pour quantifier et évaluer cette contamination des données. Plus précisément, OpenAI utilise la correspondance de sous-chaînes pour mesurer la contamination croisée entre l'ensemble de données d'évaluation et les données de pré-entraînement. Les données d'évaluation et de formation sont traitées en supprimant tous les espaces et symboles, ne laissant que les caractères (y compris les chiffres). Pour chaque exemple d'évaluation, OpenAI sélectionne au hasard trois sous-chaînes de 50 caractères (s'il y a moins de 50 caractères, l'exemple entier est utilisé). Une correspondance est déterminée si l'une des trois sous-chaînes d'évaluation échantillonnées est une sous-chaîne de l'exemple d'apprentissage traité. Cela produira une liste d'exemples corrompus, qu'OpenAI ignorera et réexécutera pour obtenir un score intact. Mais cette méthode de filtrage présente certaines limites : la correspondance de sous-chaînes peut conduire à des faux négatifs (s'il existe de petites différences entre les données d'évaluation et d'entraînement) ainsi qu'à des faux positifs. Ainsi, OpenAI n'utilise qu'une partie des informations de l'exemple d'évaluation, en exploitant uniquement les questions, le contexte ou des données équivalentes et en ignorant les réponses ou les données équivalentes. Dans certains cas, les options à choix multiples sont également exclues. Ces exclusions peuvent entraîner une augmentation des faux positifs. Concernant cette partie, les lecteurs intéressés peuvent se référer au journal pour en savoir plus. Adresse papier : https://cdn.openai.com/papers/gpt-4.pdfCependant, il existe une certaine controverse sur le score HumanEval utilisé par Phind lors de l'analyse comparative de GPT-4. Certaines personnes disent que le dernier score au test GPT-4 a atteint 85 %. Mais Phind a répondu que les recherches pertinentes qui ont abouti à ce score n'avaient pas mené de recherche sur la contamination et qu'il était impossible de déterminer si GPT-4 avait vu les données de test de HumanEval lorsqu'il avait reçu une nouvelle série de tests. Compte tenu de certaines recherches récentes sur "GPT-4 devient stupide", il est plus sûr d'utiliser les données du rapport technique original.
Cependant, compte tenu de la complexité de l'évaluation des grands modèles, la question de savoir si ces résultats d'évaluation peuvent refléter les véritables capacités du modèle reste une question controversée. Vous pouvez télécharger le modèle et en faire l'expérience vous-même. Le contenu réécrit est le suivant : Lien de référence :
Le contenu qui doit être réécrit est : https://benjaminmarie.com/the-decontaminated-evaluation-of-gpt-4/
Le contenu qui doit être réécrit est Le contenu est : https://www.phind.com/blog/code-llama-beats-gpt4
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


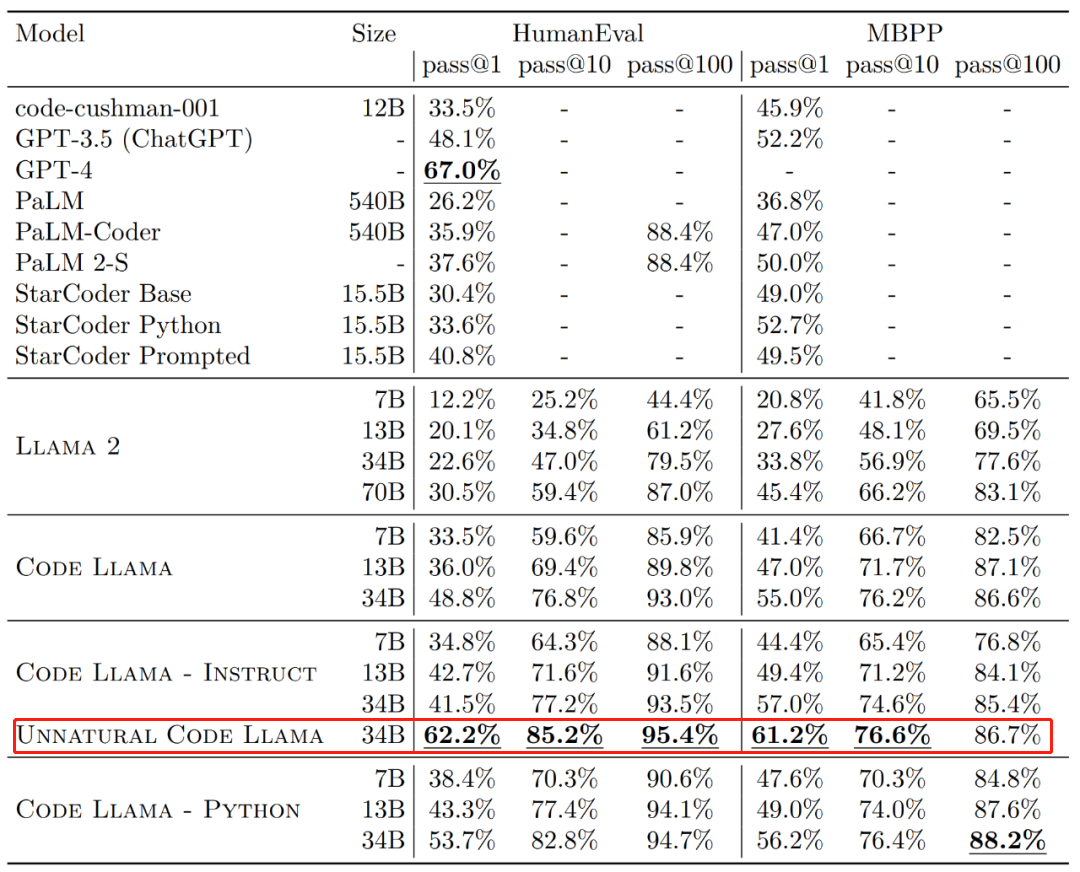 Source de l'image : https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Source de l'image : https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
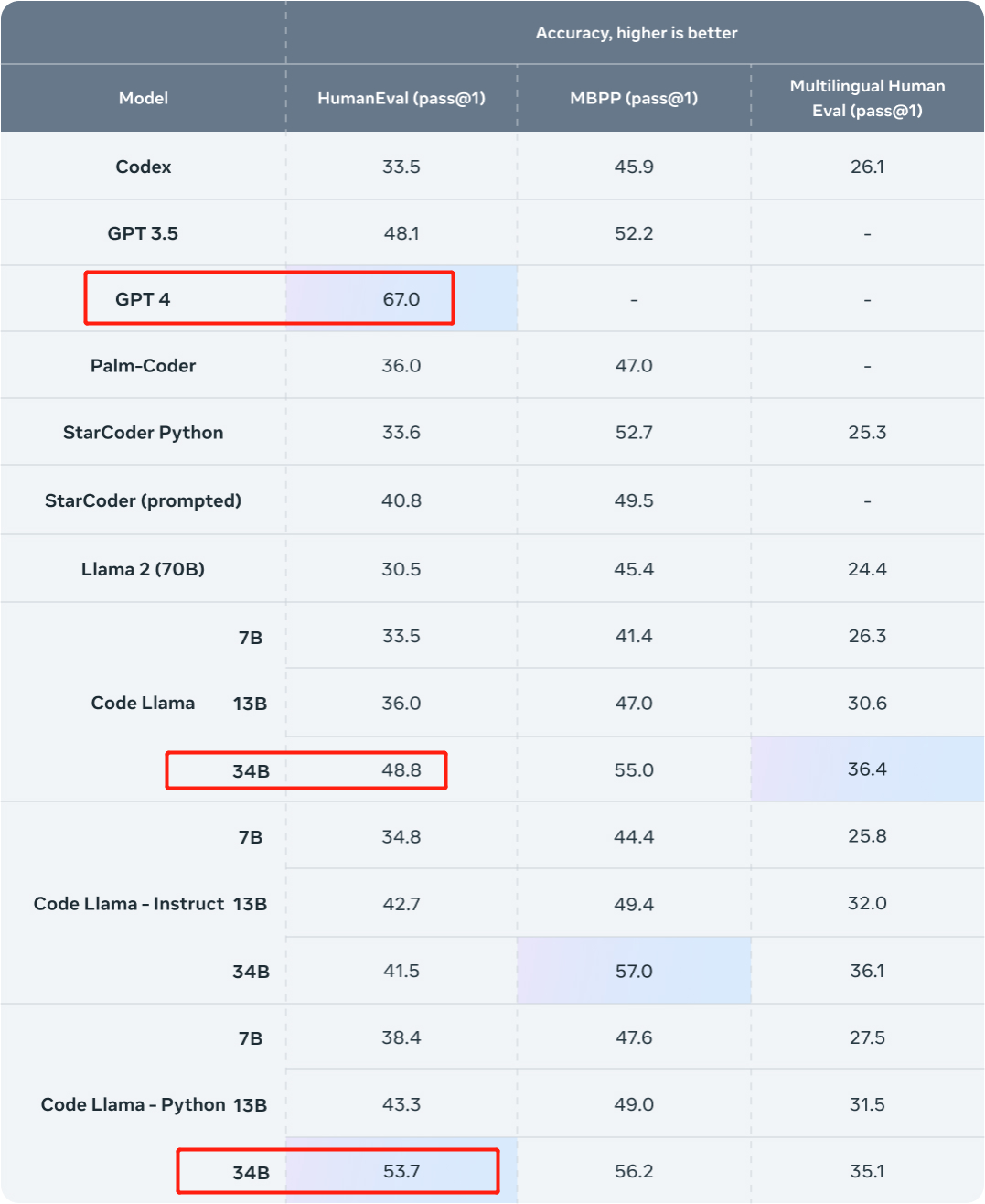 Source de l'image : https://ai.meta.com/blog/code-llama-large-langue-model-coding/
Source de l'image : https://ai.meta.com/blog/code-llama-large-langue-model-coding/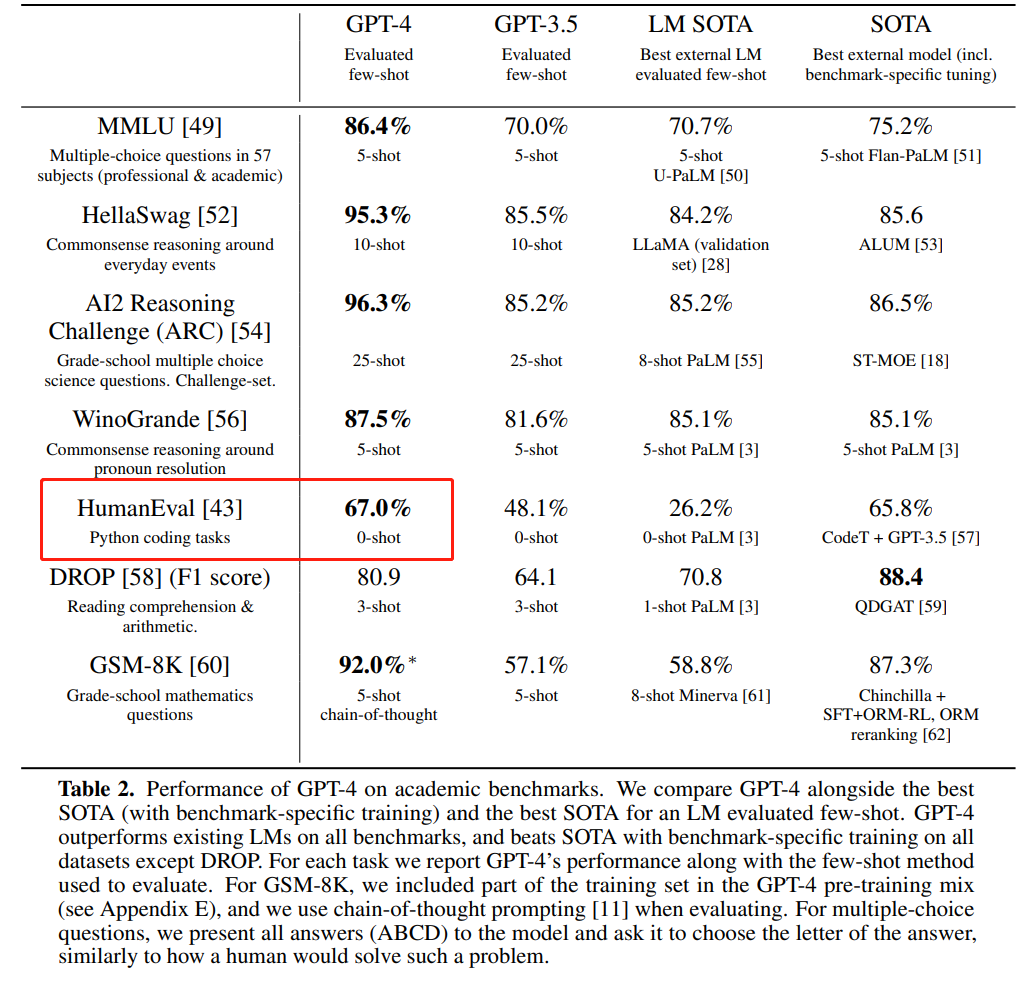 Source de l'image : https://cdn. openai.com/papers/gpt-4.pdf
Source de l'image : https://cdn. openai.com/papers/gpt-4.pdf