
Maison >base de données >tutoriel mysql >Interview Meituan : Quels pièges avez-vous rencontrés en utilisant MySQL ?
Interview Meituan : Quels pièges avez-vous rencontrés en utilisant MySQL ?
- Java后端技术全栈avant
- 2023-08-24 15:23:391288parcourir
Intervieweur : Vous maîtrisez encore assez bien le verrouillage.
Rookie moi : (souriant légèrement pour exprimer sa réponse)
Intervieweur : Après avoir utilisé MySQL pendant tant d'années, quels sont les pièges que vous n'oublierez jamais.
Rookie me : Balabala commence à parler (j'ai déjà préparé ce genre de question d'entretien avant l'entretien, alors saupoudrez-la d'eau)
Ci-dessous, j'ai compilé quelques utilisations standardisées du développement de bases de données basées sur mon expérience réelle d'utilisation. 6 "Eviter" pour résumer. 避免”来概括。
1、避免在数据库中做运算
有句话叫做“别让脚趾头想事情,那是脑瓜子的职责”,用在数据库开发中,说的就是避免让数据库做她不擅长的事情。MySQL
1. Évitez de faire des calculs dans la base de données
Il y a un dicton appelé "Ne laissez pas vos orteils réfléchir, c'est la responsabilité de votre cerveau", utilisé dans le développement de bases de données, signifie éviter de laisser la base de données faire des choses qu'elle n'est pas bon à. MySQL n'est pas doué pour les opérations mathématiques et logiques jugements, essayez donc de ne pas faire de calculs dans la base de données, et les calculs complexes peuvent être déplacés vers le processeur côté programme. 🎜🎜🎜2. Évitez de faire des opérations sur les colonnes d'index🎜🎜 🎜🎜🎜Une fois, un collègue m'a demandé de regarder un SQL, disant qu'il est très rapide d'interroger au premier plan, mais lorsque le SQL est retiré et exécuté dans la base de données, aucun résultat n'est sorti après 10 minutes d'exécution. Après avoir regardé le SQL, j'ai finalement localisé une sous-requête dans une vue. Le texte SQL de cette sous-requête est le suivant : 🎜## 以下SQL来源于网络
SELECT acinv_07.id_item ,
SUM(acinv_07.dec_endqty) dec_endqty
FROM acinv_07
WHERE acinv_07.fiscal_year * 100 + acinv_07.fiscal_period
= ( SELECT DISTINCT
ctlm1101.fiscal_year * 100 + ctlm1101.fiscal_period
FROM ctlm1101 WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
AND acinv_07.id_wh = ctlm1101.id_table)
GROUP BY acinv_07.id_itemLes colonnes fiscal_year et la colonne fiscal_period de la table acinv_07 sont indexées. Cependant, si des opérations sont effectuées sur les colonnes d'index, l'index ne sera pas disponible pour celles qui auraient pu être indexées. Je l'ai donc réécrit dans le SQL suivant :
## 以下SQL来源于网络
SELECT id_item ,
SUM(dec_qty) dec_qty
FROM dpurreq_03
GROUP BY id_item
) a ,
( SELECT a.id_item ,
SUM(a.dec_endqty) dec_endqty
FROM acinv_07 a ,
( SELECT DISTINCT
ctlm1101.fiscal_year ,
ctlm1101.fiscal_period ,
id_table
FROM ctlm1101
WHERE flag_curr = 'Y'
AND id_oprcode = 'acinv'
) b
WHERE a.fiscal_year = b.fiscal_year
AND a.fiscal_period = b.fiscal_period
AND a.id_wh = b.id_table
GROUP BY a.id_itemEnsuite, exécutez-le, et les résultats seront disponibles dans environ 4 secondes. En général, lors de l'écriture de SQL, n'effectuez pas de calculs sur les colonnes d'index, sauf en cas d'absolue nécessité.
3. Évitez count(*)
Lors de l'exécution de requêtes de pagination, certaines personnes sont toujours habituées à utiliser select count() pour obtenir le nombre total d'enregistrements. En fait, ce n'est pas efficace. , parce que les données ont été interrogées une fois auparavant, select count() équivaut à interroger la même instruction deux fois, et la surcharge sur la base de données sera naturellement importante. Nous devrions utiliser l'API fournie avec la base de données ou le système. variables pour faire le travail.
4. Évitez d'utiliser des champs NULL
Tout le monde devrait essayer d'ajouter NOT NULL DEFAULT' lors de la conception des champs de table de base de données. L'utilisation de champs NULL aura de nombreux effets néfastes, tels que : il est difficile d'optimiser les requêtes, l'ajout d'index aux colonnes NULL nécessite de l'espace supplémentaire et les index composés contenant NULL ne sont pas valides...
Regardez le cas suivant :
数据初始化:
create table table1 (
`id` INT (11) NOT NULL,
`name` varchar(20) NOT NULL
)
create table table2 (
`id` INT (11) NOT NULL,
`name` varchar(20)
)
insert into table1 values (4,"tianweichang"),(2,"zhangsan"),(3,"lisi")
insert into table2 values (1,"tianweichang"),(2, null)(1) La sous-requête NOT IN renvoie des résultats toujours vides lorsqu'il y a une valeur NULL, et la requête est sujette aux erreurs
select name from table1 where name not in (select name from table2 where id!=1)
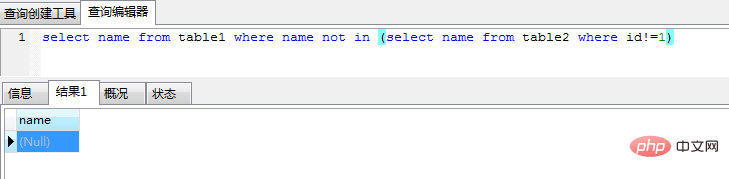
(2) Valeurs de colonne sont autorisés à être vides, l'index ne stocke pas les valeurs nulles et ces enregistrements ne seront pas inclus dans le jeu de résultats.
select * from table2 where name != 'tianweichang'
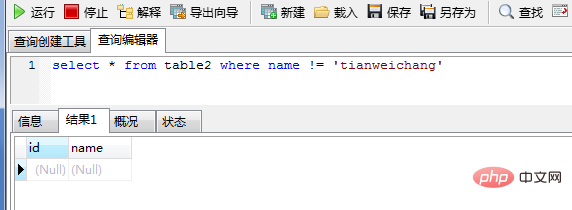
select * from table2 where name != 'zhaoyun1'
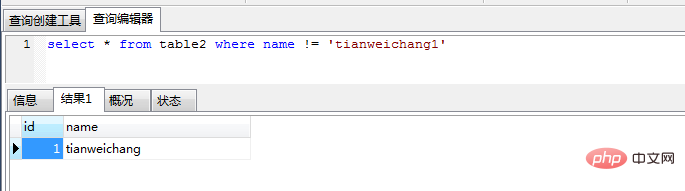
(3) Lorsque vous utilisez concatsplicing, vous devez d'abord faire un jugement non nul sur chaque champ, sinon tant qu'un champ est vide, le résultat de l'épissage sera nul
select concat("1", null) from dual;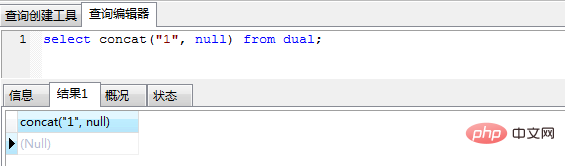
(4) 当计算count时候,name为null 的不会计入统计
select count(name) from table2;
5、避免select
使用 select *可能会返回不使用的列的数据。它在MySQL数据库服务器和应用程序之间产生不必要的I/O磁盘和网络流量。如果明确指定列,则结果集更可预测并且更易于管理。想象一下,当您使用 select *并且有人通过添加更多列来更改表格数据时,将会得到一个与预期不同的结果集。使用 select *可能会将敏感信息暴露给未经授权的用户。
6、避免在数据库里存图片
图片确实是可以存储到数据库里的,例如通过二进制流将图片存到数据库中。
但是,强烈不建议把图片存储到数据库中!!!!首先对数据库的读/写的速度永远都赶不上文件系统处理的速度,其次数据库备份变的巨大,越来越耗时间,最后对文件的访问需要穿越你的应用层和数据库层。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les différences entre sqlserver et mysql ?
- Quels sont les types d'index dans MySQL
- Quelle est la différence entre le serveur SQL et MySQL
- Cet article vous donnera une compréhension approfondie de l'installation et de la configuration de MySQL (tutoriel image et texte)
- Comment convertir une date en chaîne dans MySQL