
Maison >Périphériques technologiques >IA >Différents styles de conseils VCT, le tout avec une seule image, vous permettant de le mettre facilement en œuvre
Différents styles de conseils VCT, le tout avec une seule image, vous permettant de le mettre facilement en œuvre

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-08-22 13:49:041415parcourir
Ces dernières années, la technologie de génération d’images a réalisé de nombreuses avancées clés. Surtout depuis la sortie de grands modèles tels que DALLE2 et Stable Diffusion, la technologie d'image de génération de texte a progressivement mûri et la génération d'images de haute qualité offre de larges scénarios pratiques. Cependant, l'édition détaillée des images existantes reste un problème difficile
D'une part, en raison des limitations de la description textuelle, le modèle d'image textuelle de haute qualité existant ne peut utiliser le texte que pour éditer les images de manière descriptive, et pour certaines effets, le texte est difficile à décrire ; d'autre part, dans les scénarios d'application réels, les tâches d'édition de raffinement d'image n'ont souvent qu'un petit nombre d'images de référence, Cela crée de nombreuses solutions qui nécessitent une grande quantité de données pour la formation, en Small des quantités de données, en particulier lorsqu’il n’existe qu’une seule image de référence, sont difficiles à gérer.
Récemment, des chercheurs de NetEase Interactive Entertainment AI Lab ont proposé une solution d'édition d'image à image basée sur le guidage d'une seule image, étant donné une seule image de référence, les objets ou les styles de l'image de référence peuvent être migrés vers l'image source sans modification. la structure globale de l’image source.Le document de recherche a été accepté par l'ICCV 2023 et le code correspondant est open source.
- Adresse papier : https://arxiv.org/abs/2307.14352
- Adresse code : https://github.com/CrystalNeuro/visual-concept-translator
- Jetons d'abord un coup d'œil à une série d'images pour ressentir son effet.
 Rendu de thèse : le coin supérieur gauche de chaque ensemble d'images est l'image source, le coin inférieur gauche est l'image de référence et le côté droit est l'image de résultat générée
Rendu de thèse : le coin supérieur gauche de chaque ensemble d'images est l'image source, le coin inférieur gauche est l'image de référence et le côté droit est l'image de résultat générée
Cadre principal
L'auteur de l'article a proposé un cadre d'édition d'images basé sur
Inversion-Fusion - VCT (traducteur de concept visuel, convertisseur de concept visuel).Comme le montre la figure ci-dessous, le cadre global de VCT comprend deux processus : le processus d'inversion contenu-concept (Content-concept Inversion) et le processus de fusion contenu-concept (Content-concept Fusion). Le processus d'inversion de contenu-concept utilise deux algorithmes d'inversion différents pour apprendre et représenter respectivement les vecteurs latents des informations structurelles de l'image d'origine et les informations sémantiques de l'image de référence ; le processus de fusion contenu-concept utilise les vecteurs latents des informations structurelles ; et des informations sémantiques pour générer le résultat final.
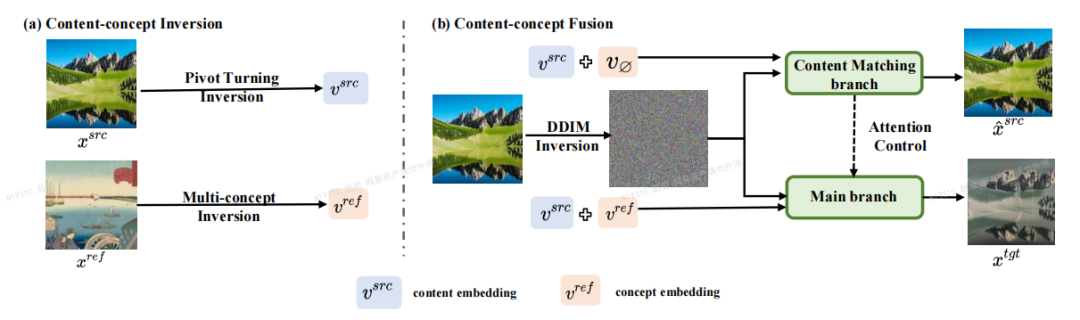 Le contenu qui doit être réécrit est : le cadre principal de l'article
Le contenu qui doit être réécrit est : le cadre principal de l'article
Il convient de mentionner que dans le domaine des réseaux contradictoires génératifs (GAN) ces dernières années, la méthode d'inversion a été largement utilisé et utilisé dans de nombreux résultats remarquables ont été obtenus sur les tâches de génération d'images [1]. Lorsque GAN réécrit le contenu, le texte original doit être réécrit en chinois. La phrase originale n'a pas besoin d'apparaître. Une image peut être mappée sur l'espace caché du générateur GAN formé, et l'objectif de l'édition peut être atteint en contrôlant le. espace caché. Ce schéma d'inversion peut exploiter pleinement la puissance générative des modèles génératifs pré-entraînés. Cette étude réécrit en fait le contenu avec GAN. Le texte original doit être réécrit en chinois, et la phrase originale n'a pas besoin d'être appliquée aux tâches d'édition d'images basées sur le guidage d'image avec le modèle de diffusion comme a priori.
.
 Lors de la réécriture du contenu, le texte original doit être réécrit en chinois, et la phrase originale n'a pas besoin d'apparaître
Lors de la réécriture du contenu, le texte original doit être réécrit en chinois, et la phrase originale n'a pas besoin d'apparaître
Introduction à la méthode
Basé sur l'idée d'inversion, VCT a conçu un processus de diffusion à deux branches, qui comprend une branche B* de reconstruction de contenu et une branche principale B pour l'édition. Ils partent du même bruit xT obtenu à partir de DDIM Inversion
【2】, un algorithme qui utilise des modèles de diffusion pour calculer le bruit des images, respectivement pour la reconstruction et l'édition de contenu. Le modèle de pré-formation utilisé dans cet article est le modèle de diffusion latente (LDM en abrégé). Le processus de diffusion se produit dans l'espace vectoriel latent z. Le processus à double branche peut être exprimé comme suit :
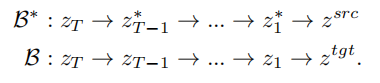
.
Processus de diffusion à double branche La branche de reconstruction de contenu B* apprend T vecteurs de caractéristiques de contenu Autrement dit, lorsque le nombre d'étapes en cours du modèle de diffusion se situe dans une certaine plage, la carte des caractéristiques d'attention du modèle de diffusion. La branche principale d'édition sera remplacée par la carte des fonctionnalités de la branche de reconstruction de contenu pour obtenir un contrôle structurel de l'image générée. La branche principale d'édition B combine le vecteur de caractéristiques de contenu Fusion de l'espace de bruit ( À chaque étape du modèle de diffusion, la fusion des vecteurs de caractéristiques se produit dans l'espace de l'espace de bruit, qui est la pondération du bruit prédit après la les vecteurs de caractéristiques sont entrés dans le modèle de diffusion. Le mixage des fonctionnalités de la branche de reconstruction de contenu s'effectue sur le vecteur de fonctionnalités de contenu mixage de l'édition branche principale Il s'agit d'un mélange de vecteur de caractéristiques de contenu À ce stade, la clé de la recherche est de savoir comment obtenir le vecteur de caractéristiques des informations structurelles à partir de une image source unique Afin de restaurer l'image source, l'article fait référence au schéma d'optimisation NULL-text[5] et apprend les vecteurs caractéristiques des étapes T pour correspondre et s'adapter à l'image source. Mais contrairement au texte NULL, qui optimise le vecteur de texte vide pour s'adapter au chemin DDIM, cet article s'adapte directement au vecteur de caractéristiques propres estimé en optimisant le vecteur de caractéristiques de l'image source : À la différence de l'apprentissage des informations structurelles, les informations conceptuelles dans l'image de référence doivent être représentées par un seul vecteur de caractéristiques hautement généralisé. Les étapes T du modèle de diffusion partagent un vecteur de caractéristiques conceptuel L'article mène des expériences sur les tâches de remplacement de sujet et de stylisation, qui peuvent changer le contenu en sujet ou en style de l'image de référence tout en conservant mieux les informations structurelles de l'image source. Contenu réécrit : Article sur les effets expérimentaux Par rapport aux solutions précédentes, le framework VCT proposé dans cet article présente les avantages suivants : (1 ) Généralisation des applications : Par rapport aux tâches d'édition d'images précédentes basées sur le guidage d'images, VCT ne nécessite pas une grande quantité de données pour la formation et offre une meilleure qualité de génération et une meilleure généralisation. Il est basé sur l'idée d'inversion et repose sur des modèles de graphiques vincentiens de haute qualité pré-entraînés sur des données du monde ouvert. Dans l'application réelle, une seule image d'entrée et une seule image de référence sont nécessaires pour obtenir de meilleurs effets d'édition d'image. . (2) Précision visuelle : Par rapport aux solutions récentes d'édition d'images de texte, VCT utilise des images comme guide de référence. La référence d’image vous permet de modifier des images avec plus de précision que les descriptions textuelles. La figure suivante montre les résultats de la comparaison entre VCT et d'autres solutions : Comparaison de l'effet de la tâche de remplacement de sujet Comparaison de la tâche de transfert de style (3) Aucune information supplémentaire n'est requise : Par rapport à certaines solutions récentes qui nécessitent l'ajout d'informations de contrôle supplémentaires (telles que des cartes de masque ou des cartes de profondeur) pour le contrôle du guidage, VCT apprend directement les informations structurelles et les informations sémantiques à partir de l'image source et de l'image de référence Fusion. génération, la figure suivante montre quelques résultats de comparaison. Parmi eux, Paint-by-example remplace les objets correspondants par des objets dans l'image de référence en fournissant une carte de masque de l'image source ; Controlnet contrôle les résultats générés via des dessins au trait, des cartes de profondeur, etc. et VCT dessine directement à partir de la source ; image et images de référence, apprenant des informations structurelles et des informations de contenu à fusionner dans des images cibles sans restrictions supplémentaires. Effet de contraste d'une solution d'édition d'image basée sur le guidage d'image NetEase Interactive Entertainment AI Lab a été créé en 2017 et est affilié au NetEase Interactive Entertainment Business Group. laboratoire d'intelligence artificielle leader dans l'industrie du jeu vidéo. Le laboratoire se concentre sur la recherche et l'application de la vision par ordinateur, du traitement de la parole et du langage naturel et de l'apprentissage par renforcement dans des scénarios de jeu. Il vise à améliorer le niveau technique des jeux et produits populaires de NetEase Interactive Entertainment grâce à la technologie de l’IA. Actuellement, cette technologie a été utilisée dans de nombreux jeux populaires, tels que "Fantasy Westward Journey", "Harry Potter: Magic Awakening", "Onmyoji", "Westward Journey", etc.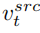 , qui est utilisé pour restaurer les informations structurelles de l'image originale, et grâce au schéma de contrôle de l'attention douce, la structure Les informations est transmis à l'éditeur de la branche principale B. Le schéma de contrôle de l'attention douce s'appuie sur le travail prompt2prompt [3] de Google. La formule est la suivante :
, qui est utilisé pour restaurer les informations structurelles de l'image originale, et grâce au schéma de contrôle de l'attention douce, la structure Les informations est transmis à l'éditeur de la branche principale B. Le schéma de contrôle de l'attention douce s'appuie sur le travail prompt2prompt [3] de Google. La formule est la suivante : 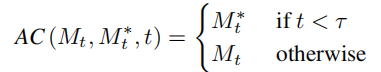
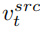 appris de l'image originale et le vecteur de caractéristiques de concept
appris de l'image originale et le vecteur de caractéristiques de concept 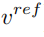 appris de l'image de référence pour générer l'image modifiée.
appris de l'image de référence pour générer l'image modifiée. 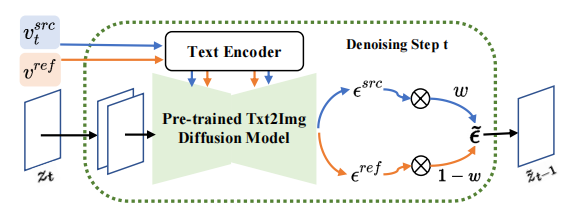
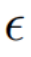 espace)
espace)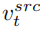 et le vecteur de texte vide, cohérent avec la forme de guidage de diffusion sans classificateur [4] :
et le vecteur de texte vide, cohérent avec la forme de guidage de diffusion sans classificateur [4] : 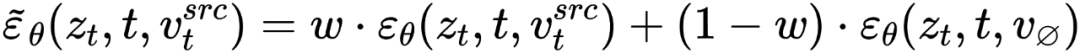
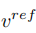 et de vecteur de caractéristiques de concept
et de vecteur de caractéristiques de concept 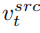 , qui est
, qui est 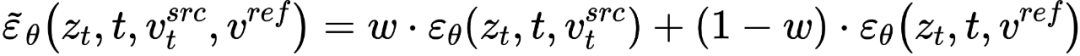
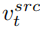 , et à partir d'une image source unique Une image de référence pour obtenir le vecteur caractéristique de l'information conceptuelle
, et à partir d'une image source unique Une image de référence pour obtenir le vecteur caractéristique de l'information conceptuelle 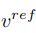 . L’article atteint cet objectif grâce à deux schémas d’inversion différents.
. L’article atteint cet objectif grâce à deux schémas d’inversion différents. 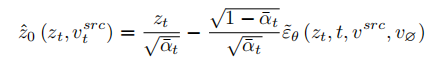
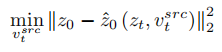
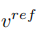 . L'article optimise les schémas d'inversion existants Textual Inversion [6] et DreamArtist [7]. Il utilise un vecteur de caractéristiques multi-concepts pour représenter le contenu de l'image de référence. La fonction de perte comprend un terme d'estimation du bruit du modèle de diffusion et un terme de perte de reconstruction estimé dans l'espace vectoriel latent :
. L'article optimise les schémas d'inversion existants Textual Inversion [6] et DreamArtist [7]. Il utilise un vecteur de caractéristiques multi-concepts pour représenter le contenu de l'image de référence. La fonction de perte comprend un terme d'estimation du bruit du modèle de diffusion et un terme de perte de reconstruction estimé dans l'espace vectoriel latent : 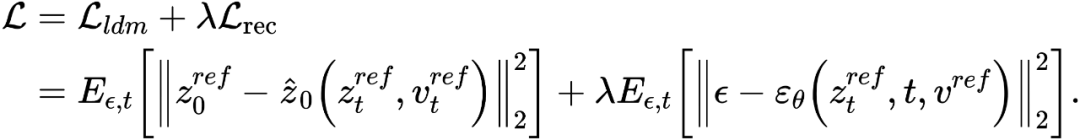
. Résultats expérimentaux




NetEase Interactive Entertainment AI Lab
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est l'unité la plus basique des images Photoshop
- Quels sont les trois principaux contenus de la recherche sur la structure des données ?
- Qu'est-ce que l'étude des structures de données ?
- Une plongée approfondie dans les générateurs asynchrones et l'itération asynchrone dans Node.js
- Laissez-moi vous emmener étudier le SugaredLogger de Go Zap !