
Maison >base de données >SQL >Question d'entretien : Comment optimiser MySQL dans le travail quotidien ?
Question d'entretien : Comment optimiser MySQL dans le travail quotidien ?
- Java后端技术全栈avant
- 2023-08-17 16:26:101155parcourir
Avant-propos
Les méthodes d'optimisation courantes de MySQL sont divisées en les aspects suivants :
Optimisation SQL, optimisation de la conception, optimisation du matériel, etc., chacune comprenant plusieurs petites optimisations.
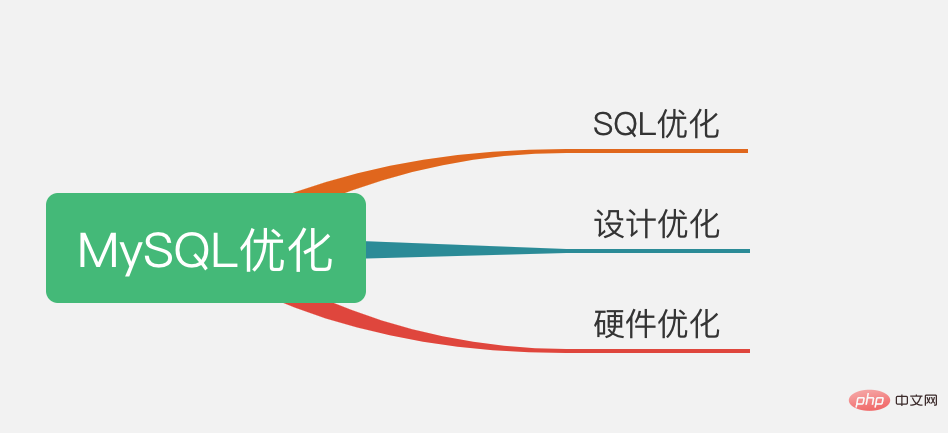 Regardons de plus près ci-dessous
Regardons de plus près ci-dessousCe plan d'optimisation fait référence à l'amélioration de l'efficacité opérationnelle de la base de données MySQL en optimisant les instructions et les index SQL. Le contenu spécifique est le suivant :
. Par exemple :
select * from table where type = 2 and level = 9 order by id asc limit 190289,10;
Plan d'optimisation :
- Association retardée
Extrayez d'abord la clé primaire via la condition Where, puis associez la table à la table de données d'origine, extrayez les lignes de données via la identifiant de clé primaire, au lieu d'extraire les lignes de données via l'index secondaire d'origine
Par exemple :
select a.* from table a, (select id from table where type = 2 and level = 9 order by id asc limit 190289,10 ) b where a.id = b.id
- Méthode Bookmark
Pour parler franchement, la méthode bookmark consiste à trouver la valeur de clé primaire correspondant à l'index secondaire d'origine. premier paramètre de limite, puis en fonction de cette valeur de clé primaire Allez dans filtre et limite
Par exemple :
select * from table where id > (select * from table where type = 2 and level = 9 order by id asc limit 190289, 1) limit 10;
Utilisez l'index correctement
假如我们没有添加索引,那么在查询时就会触发全表扫描,因此查询的数据就会很多,并且查询效率会很低,为了提高查询的性能,我们就需要给最常使用的查询字段上,添加相应的索引,这样才能提高查询的性能 建立覆盖索引 InnoDB使用辅助索引查询数据时会回表,但是如果索引的叶节点中已经包含要查询的字段,那它没有必要再回表查询了,这就叫覆盖索引 例如对于如下查询: 我们将被查询的字段建立到联合索引中,这样查询结果就可以直接从索引中获取 在 MySQL 5.0 之前的版本尽量避免使用or查询 在 MySQL 5.0 之前的版本要尽量避免使用 or 查询,可以使用 union 或者子查询来替代,因为早期的 MySQL 版本使用 or 查询可能会导致索引失效,在 MySQL 5.0 之后的版本中引入了索引合并 索引合并简单来说就是把多条件查询,比如or或and查询对多个索引分别进行条件扫描,然后将它们各自的结果进行合并,因此就不会导致索引失效的问题了 如果从Explain执行计划的type列的值是 避免在 where 查询条件中使用 != 或者 a8093152e673feb7aba1828c43532094 操作符 SQL中,不等于操作符会导致查询引擎放弃索引索引,引起全表扫描,即使比较的字段上有索引 解决方法:通过把不等于操作符改成or,可以使用索引,避免全表扫描 例如,把 适当使用前缀索引 MySQL 是支持前缀索引的,也就是说我们可以定义字符串的一部分来作为索引 我们知道索引越长占用的磁盘空间就越大,那么在相同数据页中能放下的索引值也就越少,这就意味着搜索索引需要的查询时间也就越长,进而查询的效率就会降低,所以我们可以适当的选择使用前缀索引,以减少空间的占用和提高查询效率 比如,邮箱的后缀都是固定的“ 使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本 需要注意的是,前缀索引也存在缺点,MySQL无法利用前缀索引做order by和group by 操作,也无法作为覆盖索引 查询具体的字段而非全部字段 要尽量避免使用 优化子查询 尽量使用 Join 语句来替代子查询,因为子查询是嵌套查询,而嵌套查询会新创建一张临时表,而临时表的创建与销毁会占用一定的系统资源以及花费一定的时间,同时对于返回结果集比较大的子查询,其对查询性能的影响更大 小表驱动大表 我们要尽量使用小表驱动大表的方式进行查询,也就是如果 B 表的数据小于 A 表的数据,那执行的顺序就是先查 B 表再查 A 表,具体查询语句如下: 不要在列上进行运算操作 不要在列字段上进行算术运算或其他表达式运算,否则可能会导致查询引擎无法正确使用索引,从而影响了查询的效率 一个很容易踩的坑:隐式类型转换: skuId这个字段上有索引,但是explain的结果却显示这条语句会全表扫描 原因在于skuId的字符类型是varchar(32),比较值却是整型,故需要做类型转换 适当增加冗余字段 增加冗余字段可以减少大量的连表查询,因为多张表的连表查询性能很低,所有可以适当的增加冗余字段,以减少多张表的关联查询,这是以空间换时间的优化策略 正确使用联合索引 使用了 B+ 树的 MySQL 数据库引擎,比如 InnoDB 引擎,在每次查询复合字段时是从左往右匹配数据的,因此在创建联合索引的时候需要注意索引创建的顺序 例如,我们创建了一个联合索引是 MySQL的join语句连接表使用的是nested-loop join算法,这个过程类似于嵌套循环,简单来说,就是遍历驱动表(外层表),每读出一行数据,取出连接字段到被驱动表(内层表)里查找满足条件的行,组成结果行 要提升join语句的性能,就要尽可能减少嵌套循环的循环次数 一个显著优化方式是对被驱动表的join字段建立索引,利用索引能快速匹配到对应的行,避免与内层表每一行记录做比较,极大地减少总循环次数。另一个优化点,就是连接时用小结果集驱动大结果集,在索引优化的基础上能进一步减少嵌套循环的次数 如果难以判断哪个是大表,哪个是小表,可以用inner join连接,MySQL会自动选择小表去驱动大表 避免使用JOIN关联太多的表 对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大 如果程序中大量的使用了多表关联的操作,同时 利用索引扫描做排序 MySQL有两种方式生成有序结果:其一是对结果集进行排序的操作,其二是按照索引顺序扫描得出的结果自然是有序的 但是如果索引不能覆盖查询所需列,就不得不每扫描一条记录回表查询一次,这个读操作是随机IO,通常会比顺序全表扫描还慢 因此,在设计索引时,尽可能使用同一个索引既满足排序又用于查找行 例如: 只有当索引的列顺序和ORDER BY子句的顺序完全一致,并且所有列的排序方向都一样时,才能够使用索引来对结果做排序 MySQL处理union的策略是先创建临时表,然后将各个查询结果填充到临时表中最后再来做查询,很多优化策略在union查询中都会失效,因为它无法利用索引 最好手工将where、limit等子句下推到union的各个子查询中,以便优化器可以充分利用这些条件进行优化 此外,除非确实需要服务器去重,一定要使用union all,如果不加all关键字,MySQL会给临时表加上distinct选项,这会导致对整个临时表做唯一性检查,代价很高 出现慢查询通常的排查手段是先使用慢查询日志功能,查询出比较慢的 SQL 语句,然后再通过 Explain 来查询 SQL 语句的执行计划,最后分析并定位出问题的根源,再进行处理 Le journal des requêtes lentes fait référence à la fonction d'enregistrement du journal des requêtes lentes qui peut être activée via la configuration dans MySQL, dépassant 我们可以通过设置 Essayez d'éviter d'utiliser NULL Longueur minimale des données Utilisez les types de données les plus simples Stratégie appropriée de sous-table et de sous-base de données La sous-base de données fait référence à la division d'une base de données en. plusieurs bases de données. Par exemple, nous divisons une base de données en plusieurs bases de données. Une base de données principale est utilisée pour écrire et modifier les données, et les autres sont utilisées pour synchroniser les données principales et les fournir au client pour interrogation. De cette manière, la lecture et l'écriture. la pression d'une base de données est partagée. Plusieurs bibliothèques sont fournies, améliorant ainsi l'efficacité opérationnelle globale de la base de données Paramètre de largeur de type entier MySQL peut spécifier la largeur des types entiers, tels que int(11), ce qui n'a en fait aucun sens, il ne limite pas la plage de valeurs, pour le stockage et calculé, int(1) et int(20) sont les mêmes Types VARCHAR et CHAR Le type char est de longueur fixe et varchar stocke des chaînes variables, ce qui permet d'économiser plus d'espace qu'une longueur fixe, mais varchar It nécessite 1 ou 2 octets supplémentaires pour enregistrer la longueur de la chaîne, et il est également sujet à la fragmentation lors de la mise à jour. Il doit être sélectionné en fonction du scénario d'utilisation : si la longueur maximale de la colonne de chaîne est beaucoup plus grande que la longueur moyenne, ou la colonne est rarement mise à jour, il est plus pratique de choisir varchar Convient si vous souhaitez stocker une chaîne très courte, ou si les valeurs de la chaîne sont de la même longueur, comme les valeurs MD5, ou si les données de la colonne changent fréquemment ; , choisissez d'utiliser les types char datetime a une plage plus large et peut représenter les années de 1001 à 9999, et l'horodatage ne peut représenter que les années de 1970 à 2038. datetime n'a rien à voir avec le fuseau horaire, la valeur d'affichage de l'horodatage dépend du fuseau horaire. Dans la plupart des scénarios, les deux types peuvent bien fonctionner, mais il est recommandé d'utiliser l'horodatage, car datetime occupe 8 octets, l'horodatage n'occupe que 4 octets, l'espace d'horodatage est plus efficace blob et text sont tous deux types de données chaîne conçus pour stocker de grandes quantités de données. Ils sont stockés respectivement en modes binaire et caractère. En utilisation réelle, ces deux types doivent être utilisés avec prudence, car leur efficacité de requête est très faible si un champ doit les utiliser. types, vous pouvez séparer ce champ en une sous-table. Lorsque vous avez besoin d'interroger ce champ, utilisez une requête conjointe. Cela peut améliorer l'efficacité des requêtes de la table principale Partie 1 en premier forme normale : les champs sont inséparables et la base de données le prend en charge par défaut. Deuxième forme normale : élimine la dépendance partielle à la clé primaire. Vous pouvez ajouter un champ qui n'a rien à voir avec la logique métier comme clé primaire dans la table. en utilisant un identifiant à incrémentation automatique. Troisième forme normale : éliminez la dépendance transitive à l'égard de la clé primaire et divisez la table pour réduire la redondance des données Les exigences matérielles de MySQL se reflètent principalement dans trois aspects : disque, réseau et mémoire Disque Les disques devraient essayer d'utiliser des disques dotés de capacités de lecture et d'écriture hautes performances, telles que des capacités solides- disques d'état. De cette façon, le temps d'exécution des E/S peut être réduit, améliorant ainsi l'efficacité globale de fonctionnement de MySQL. Pour les disques, vous pouvez également essayer d'utiliser plusieurs petits disques au lieu d'un grand disque, en raison de la vitesse de rotation du disque. Le disque est fixe. Cela équivaut à avoir plusieurs disques fonctionnant en parallèle Assurer une bande passante réseau fluide (faible latence) et une bande passante réseau suffisante sont les conditions de base pour le fonctionnement normal de MySQL. Si les conditions le permettent, vous pouvez. configurez également plusieurs cartes réseau. , pour améliorer l'efficacité de fonctionnement du serveur MySQL pendant les périodes de pointe du réseau Plus la mémoire du serveur MySQL est grande, plus d'informations sont stockées et mises en cache, ainsi que les performances du serveur MySQL. la mémoire est très élevée, améliorant ainsi toute l'efficacité opérationnelle de MySQLselect name from test where city='上海'
alter table test add index idx_city_name (city, name);
index_merge可以看出MySQL使用索引合并的方式来执行对表的查询columna8093152e673feb7aba1828c43532094’aaa’,改成column>’aaa’ or column<’aaa’,就可以使用索引了@xxx.com”,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引alter table test add index index2(email(6));
select *,而是查询需要的字段,这样可以提升速度,以及减少网络传输的带宽压力select name from A where id in (select id from B);
select * from test where id + 1 = 50;
select * from test where month(updateTime) = 7;
select * from test where skuId=123456
idx(name,age,sex),那么当我们使用,姓名+年龄+性别、姓名+年龄、姓名等这种最左前缀查询条件时,就会触发联合索引进行查询;然而如果非最左匹配的查询条件,例如,性别+姓名这种查询条件就不会触发联合索引
Join优化
join_buffer_size参数进行设置join_buffer_size设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性
排序优化
--建立索引(date,staff_id,customer_id)
select staff_id, customer_id from test where date = '2010-01-01' order by staff_id,customer_id;
UNION优化
慢查询日志
long_query_time la valeur SQL sera enregistrée dans le journallong_query_time值的 SQL 将会被记录在日志中“slow_query_log=1”"slow_query_log=1" pour activer la requête lenteIl convient de noter qu'après avoir activé la fonction de journal lent, cela affectera le performances de MySQL Cela aura un certain impact, cette fonction doit donc être utilisée avec prudence dans l'environnement de production
Optimisation de la conception
Sélection de type commun
Lorsque les données sont meilleures. normalisé Lors de la normalisation, moins de données sont modifiées, et la table normalisée est généralement plus petite, et plus de données peuvent être mises en cache en mémoire, donc l'opération d'exécution sera plus rapideL'inconvénient est que plus d'associations sont nécessaires lors de la requête
Optimisation du matériel
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel est le niveau d'isolation des transactions par défaut de MySQL ?
- Comment créer une base de données dans MySQL
- Comment créer une base de données en mysql ?
- mysql n'est pas reconnu comme une commande interne ou externe, un programme exploitable ou un fichier batch
- Quelles sont les situations dans lesquelles l'index MySQL échoue ?