
Maison >Java >JavaQuestions d'entretien >Intervieweur : Comment MySQL implémente-t-il ACID ?
Intervieweur : Comment MySQL implémente-t-il ACID ?
- Java后端技术全栈avant
- 2023-08-17 14:39:00817parcourir
Lors de l'interview, l'intervieweur n'a qu'à poser des questions sur l'ACID de MySQL, puis il peut immédiatement réciter l'essai en huit parties (certaines personnes ne seront peut-être pas encore en mesure d'y répondre). Ce qui est encore plus dégoûtant, c'est que certains intervieweurs ne suivent pas la routine et continuent de se demander comment MySQL implémente-t-il ACID ?
Vous êtes confus. Pour être honnête, cette question peut dissuader 95% des gens.
Aujourd'hui, cet article traite principalement du principe de mise en œuvre d'ACID sous le moteur MySQL InnoDB . Il ne développe pas trop les connaissances de base telles que ce qu'est une transaction et la signification du niveau d'isolement.
ACID
En tant que base de données relationnelle, comment MySQL garantit-il ACID en termes de moteur InnoDB le plus courant.
(Atomicité)Atomicité : La transaction est la plus petite unité d'exécution et ne permet pas de division. Atomicité garantit que les actions sont entièrement terminées ou n'ont aucun effet (Cohérence) : Les données restent cohérentes avant et après l'exécution d'une transaction ; (Isolement) Isolation : Lors de l'accès au base de données simultanément, une transaction n'est pas interférée par d'autres transactions. (Durabilité) Durabilité : Après qu'une transaction soit engagée. Les modifications apportées aux données de la base de données sont persistantes, même en cas de défaillance de la base de données.
Isolement
Parlons d’abord de l’isolement. Le premier concerne les quatre niveaux d’isolement.
Niveau d'isolement Après la soumission, les modifications apportées seront visibles par les autres transactions| Lecture répétable | Dans une transaction, le résultat de la lecture des mêmes données est toujours le même, que d'autres transactions opèrent sur les données et que la transaction soit validée. Niveau par défaut d'InnoDB. |
| Sérialisation | Les transactions sont exécutées en série. Chaque lecture doit obtenir un verrou partagé au niveau de la table. La lecture et l'écriture se bloqueront mutuellement. Le niveau d'isolement est le plus élevé, sacrifiant la concurrence du système. |
Différents niveaux d'isolement permettent de résoudre différents problèmes. Autrement dit, les lectures sales, les lectures fantômes et les lectures non répétables.
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Lire non validé | Peut apparaître | Peut apparaître | Peut apparaître |
| Lire soumis | Non autorisé | Peut apparaître | Peut apparaître |
| Lecture répétable | Non autorisé à apparaître | Interdit de comparaître | Peut apparaître |
| Sérialisation | non autorisée | non autorisée | non autorisée |
Des niveaux d'isolement si différents, comment l'isolement est-il réalisé et pourquoi différentes choses ne peuvent-elles pas interférer les unes avec les autres ? La réponse est Locks et MVCC.
Verrous
Parlons d’abord des verrous. Combien de verrous MySQL possède-t-il ?
Granularité
En termes de granularité, cela signifie les verrous de table, les verrous de page et les verrous de ligne. Les verrous de table incluent les verrous partagés intentionnels, les verrous exclusifs intentionnels, les verrous auto-croissants, etc. Les verrous de rangée sont mis en œuvre au niveau moteur par chaque moteur. Mais tous les moteurs ne prennent pas en charge les verrous de ligne. Par exemple, le moteur MyISAM ne prend pas en charge les verrous de ligne.
Types de verrous de ligne
Dans les transactions InnoDB, les verrous de ligne sont implémentés en verrouillant les entrées d'index sur l'index. Cela signifie qu'InnoDB utilise des verrous au niveau des lignes uniquement lorsque les données sont récupérées via des conditions d'index, sinon des verrous de table sont utilisés. Les verrous au niveau des lignes sont également divisés en deux types : les verrous partagés et les verrous exclusifs, ainsi que les verrous partagés d'intention et les verrous exclusifs d'intention qui doivent être obtenus avant le verrouillage.
Verrouillage partagé : verrouillage en lecture, d'autres transactions sont autorisées à ajouter un verrou S, d'autres transactions ne sont pas autorisées à ajouter un verrou X, c'est-à-dire que d'autres transactions ne peuvent que lire mais pas écrire. sélectionner...verrouiller en mode partageVerrouiller.select...lock in share mode加锁。排它锁:写锁,不允许其他事务再加S锁或者X锁。 insert、update、delete、for update
insérer, mettre à jour, supprimer, pour la mise à jourVerrouiller. Le verrou de ligne est ajouté
lorsqu'il est nécessaire, mais il n'est pas libéré immédiatement lorsqu'il n'est plus nécessaire, mais il n'est libéré qu'à la fin de la transaction. Il s'agit du protocole de verrouillage en deux phases. 🎜🎜Algorithme de mise en œuvre du verrouillage de ligne
Verrouillage d'enregistrement
Un verrou sur un enregistrement à une seule ligne verrouillera toujours l'enregistrement d'index.
Gap Lock
Gap Lock, réfléchissez à la raison de la lecture fantôme. En fait, les verrous de ligne ne peuvent verrouiller que les lignes, mais lors de l'insertion de nouveaux enregistrements, ce qui doit être mis à jour est "l'écart" entre les enregistrements. Ajoutez donc un verrouillage d'espacement pour résoudre la lecture fantôme.
Next-Key Lock
Gap Lock + Record Lock, laissé ouvert et fermé.
Isolement des serrures
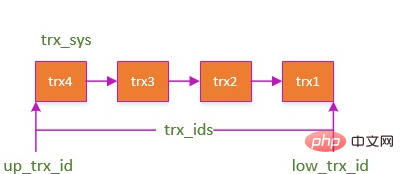
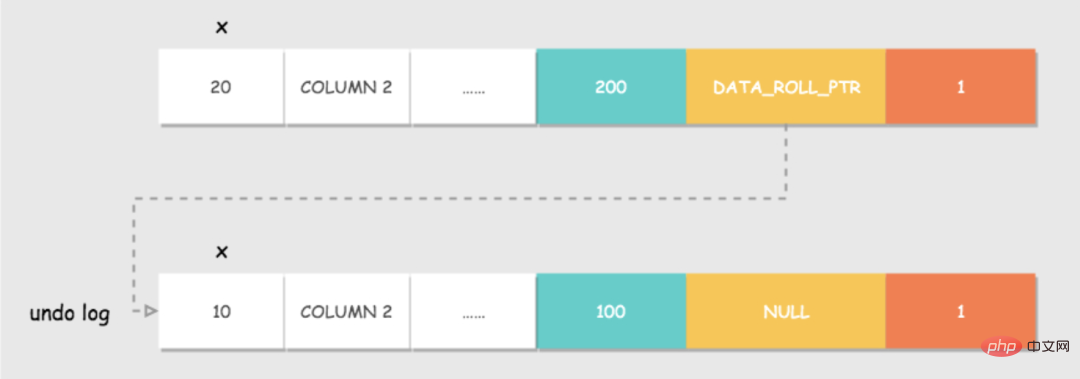
Une introduction générale à la serrure inférieure, vous pouvez la voir. Avec les verrous, lorsqu'une transaction écrit des données, les autres transactions ne peuvent pas obtenir le verrou en écriture et ne peuvent pas écrire de données, ce qui garantit dans une certaine mesure l'isolement entre les transactions. Mais comme mentionné précédemment, si un verrou en écriture est ajouté, pourquoi d’autres transactions peuvent-elles également lire des données ? Le verrou en lecture ne peut-il pas être obtenu ? Comme mentionné précédemment, avec le verrou, la transaction en cours ne peut pas modifier les données sans verrou en écriture, mais elles peuvent toujours être lues, même si la ligne de données a été modifiée et validée par d'autres transactions, la même ligne de données peut toujours être lue à plusieurs reprises. Il s'agit de MVCC, contrôle de concurrence multi-version, contrôle de concurrence multi-version. Le format de stockage des enregistrements de ligne dans Innodb, il y a quelques champs supplémentaires : DATA_TRX_ID et DATA_ROLL_PTR. annuler le journal : enregistrez le journal avant que les données ne soient modifiées, ce qui sera expliqué en détail plus tard. est créé au début de chaque SQL et possède plusieurs attributs importants : DATA_TRX_ID 876ef644ab7335403789efe98ffb1531= low_limit_id : Indique que les données sont générées après la création de la vue de lecture actuelle et que les données ne sont pas affichées. up_limit_id Avec les verrous et MVCC, l'isolation des transactions est résolue. Permettez-moi de développer ici. Le niveau RR par défaut résout-il la lecture fantôme ? La lecture fantôme cible généralement INSERT et les cibles de non-répétabilité UPDATE. Nous nous attendions à ce que ce soit Il s'est en fait avéré être En fait, le niveau d'isolement de la lecture répétable MySQL ne résout pas complètement le problème de la lecture fantôme, mais résout le problème de la lecture fantôme lors de la lecture des données. Il existe toujours un problème de lecture fantôme pour les opérations de modification, ce qui signifie que MVCC ne résout pas complètement les lectures fantômes. Parlons d’atomicité. Comme mentionné précédemment, l'annulation du journal restaure le journal. L'isolement MVCC en dépend en fait, tout comme l'atomicité. La clé pour parvenir à l'atomicité est de pouvoir annuler toutes les instructions SQL exécutées avec succès lorsque la transaction est annulée. Lorsqu'une transaction modifie la base de données, InnoDB générera le journal d'annulation correspondant ; si l'exécution de la transaction échoue ou si un rollback est appelé, provoquant l'annulation de la transaction, les informations du journal d'annulation peuvent être utilisées pour restaurer les données. comme c'était le cas avant la modification. Le journal d'annulation est un journal logique qui enregistre les informations relatives à l'exécution de SQL. Lorsqu'une restauration se produit, InnoDB fera le contraire du travail précédent en fonction du contenu du journal d'annulation : Prenons comme exemple l'opération de mise à jour : lorsqu'une transaction exécute une mise à jour, le undo log généré contiendra la clé primaire de la ligne modifiée (afin de savoir quelles lignes ont été modifiées), quelles colonnes ont été modifiées, et les valeurs de ces colonnes avant et après modification Lors de la restauration, vous pouvez utiliser ces informations pour restaurer les données à l'état avant la mise à jour. Innnodb a de nombreux journaux et la persistance repose sur le journal redo. La persistance est définitivement liée à l'écriture. La technologie WAL souvent mentionnée dans MySQL, le nom complet de WAL est Write-Ahead Logging. Son point clé est d'écrire d'abord le journal, puis d'y écrire. le disque. Tout comme faire des affaires dans un petit magasin, il y a un tableau rose et un livre de comptes Lorsque les invités viennent, écrivez d'abord sur le tableau rose, puis écrivez le livre de comptes lorsque vous n'êtes pas occupé. redo log est ce tableau rose Lorsqu'un enregistrement doit être mis à jour, le moteur InnoDB écrira d'abord l'enregistrement dans le journal redo (et mettra à jour la mémoire). Au moment opportun, cet enregistrement d'opération est mis à jour sur le disque, et cette mise à jour est souvent effectuée lorsque le système est relativement inactif, tout comme ce que fait le commerçant après la fermeture. redo log a deux fonctionnalités : L'utilisation de Buffer Pool améliore considérablement l'efficacité de la lecture et de l'écriture des données, mais elle entraîne également de nouveaux problèmes : si MySQL tombe en panne et que les données modifiées dans le Buffer Pool n'ont pas été vidées sur le disque, cela entraînera des données corruption. Perdue, la pérennité de la transaction n’est pas garantie. J'ai donc rejoint le redo log. Lorsque les données sont modifiées, en plus de modifier les données dans le Buffer Pool, l'opération sera également enregistrée dans le redo log ; Lorsque la transaction est soumise, l'interface fsync sera appelée pour vider le redo log ; Si MySQL tombe en panne, vous pouvez lire les données dans le journal redo et restaurer la base de données au redémarrage. redo log utilise WAL (Write-ahead logging, write-ahead log). Toutes les modifications sont d'abord écrites dans le journal, puis mises à jour dans le pool de tampons, garantissant que les données ne seront pas perdues en raison du temps d'arrêt de MySQL, garantissant ainsi la durabilité. Exiger. Et il y a deux avantages à faire cela : En parlant de cela, vous vous demandez peut-être s'il existe également un journal bin qui est également utilisé pour les opérations d'écriture et qui est utilisé pour la récupération de données. pour les déclarations Pourquoi écrire le journal de rétablissement en premier ? La cohérence est le but ultime poursuivi par les transactions. L'atomicité, la persistance et l'isolement mentionnés dans la question précédente visent en fait à assurer la cohérence de l'état de la base de données. Bien entendu, tout ce qui précède est une garantie au niveau de la base de données, et la mise en œuvre de la cohérence nécessite également des garanties au niveau de l'application. C'est-à-dire que pour votre entreprise par exemple, l'opération d'achat ne déduit que le solde de l'utilisateur et ne réduit pas l'inventaire. Il est définitivement impossible de garantir la cohérence du statut. Nous connaissons tous MySQL, et nous savons également ce qu'est l'ACID, mais comment l'ACID de MySQL est-il implémenté ? Parfois, tout comme vous savez qu'il existe des journaux d'annulation et de rétablissement, mais vous ne savez peut-être pas pourquoi il y en a. Lorsque vous connaîtrez le but de la conception, cela deviendra plus clair. MVCC
Chaîne de versions
undo log. 
ReadView
Lecture fantôme de niveau RR
chose 1
chose 2
begin
begin
sélectionner * du département
-
insérer dans le service (nom) les valeurs ("A")
-
commit
mettre à jour le service défini nom="B"
commit
id name
1 A
2 B
id name
1 B
2 B
Atomicité
Persistence
Comment exécuter une instruction de mise à jour SQL
redo log
binlog
binlog et redo log
update T set c=c+1 where ID=2;
Cohérence
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!