
Maison >Java >JavaQuestions d'entretien >Interview : Savez-vous quelles méthodes sont disponibles pour optimiser les performances Java ?
Interview : Savez-vous quelles méthodes sont disponibles pour optimiser les performances Java ?
- Java后端技术全栈avant
- 2023-08-16 16:49:141113parcourir
Il y a deux jours, un ami du groupe est venu discuter avec moi. Lors de l'entretien, on lui a demandé comment répondre aux méthodes d'optimisation des performances. Discutons aujourd'hui. Cet article se concentre principalement sur l'analyse théorique. Jetons un coup d'œil global aux règles qui peuvent être suivies pour l'optimisation des performances Java.
Cet article se concentre sur la théorie, sur la pratique, les articles suivants utiliseront davantage de cas pour affiner les points de connaissance de cet article, qui conviennent à la réflexion et à l'induction répétées.
Aperçu
L'optimisation des performances est divisée en optimisation commerciale et optimisation technique selon la catégorie d'optimisation. L'effet de l'optimisation des affaires est également très important, mais il appartient à la catégorie des produits et de la gestion. En tant que programmeurs, dans notre travail quotidien, les méthodes d'optimisation auxquelles nous sommes confrontés passent principalement par une série de moyens techniques pour atteindre les objectifs d'optimisation établis. Je peux résumer grossièrement cette série de moyens techniques dans les sept catégories suivantes :
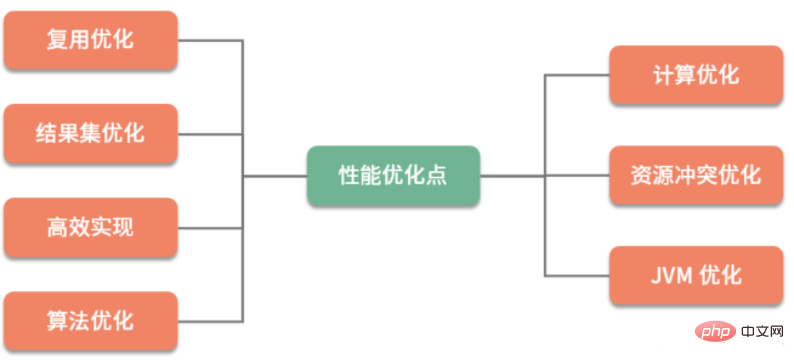
Comme vous pouvez le constater, la méthode d'optimisation se concentre sur la planification des ressources informatiques et des ressources de stockage. Il existe de nombreuses façons d’échanger de l’espace contre du temps dans les méthodes d’optimisation, mais il n’est pas conseillé de prendre en compte uniquement la vitesse de calcul sans considérer les problèmes de complexité et d’espace. Ce que nous devons faire, c'est parvenir à une utilisation optimale des ressources tout en veillant aux performances.
Ensuite, je présenterai brièvement ces 7 directions d'optimisation. Si vous vous sentez ennuyeux, ce n'est pas grave. Le but de cet article est de vous donner une idée du score total et une compréhension globale des bases théoriques.
Optimisation de la réutilisation
Lors de l'écriture du code, vous constaterez qu'il existe de nombreux codes répétés qui peuvent être extraits et transformés en méthodes publiques. De cette façon, vous n’aurez pas à le réécrire la prochaine fois que vous l’utiliserez.
Cette idée est la réutilisation. La description ci-dessus est une optimisation de la logique de codage pour l'accès aux données, on retrouve la même situation de réutilisation. Que ce soit dans la vie ou dans le codage, des choses répétées se produisent tout le temps. Sans réutilisation, le travail et la vie seront plus fatiguants.
Dans les systèmes logiciels, lorsqu'il s'agit de réutilisation des données, la première chose à laquelle nous pensons est la mise en mémoire tampon et la mise en cache. Faites attention à la différence entre ces deux mots. Leurs significations sont complètement différentes. De nombreux étudiants se confondent facilement. Voici une brève introduction.
Buffer est couramment utilisé pour stocker temporairement des données, puis les transférer ou les écrire par lots. La méthode séquentielle est principalement utilisée pour atténuer les écritures aléatoires fréquentes et lentes entre différents appareils. La mise en mémoire tampon est principalement destinée aux opérations d'écriture.
Cache (Cache) est souvent utilisé pour réutiliser les données de lecture. En les mettant en cache dans une zone relativement rapide, la mise en cache est principalement ciblée sur les opérations de lecture.
De même, c'est l'opération de pooling d'objets, tels que le pool de connexions à la base de données, le pool de threads, etc., qui sont très fréquemment utilisées en Java. Étant donné que les coûts de création et de destruction de ces objets sont relativement élevés, nous stockerons également temporairement ces objets après utilisation, la prochaine fois que nous les utiliserons, nous n'aurons pas à refaire la fastidieuse opération d'initialisation.
Optimisation informatique
Exécution parallèle
De nos jours, les processeurs se développent très rapidement et la plupart du matériel est multicœur. Si vous souhaitez accélérer l’exécution d’une certaine tâche, la solution la plus rapide et la meilleure est de la laisser s’exécuter en parallèle. Il existe trois modes d'exécution parallèle :
Le premier mode est multi-machine, qui utilise l'équilibrage de charge pour diviser le trafic ou les calculs volumineux en plusieurs parties et les traiter simultanément. Par exemple, Hadoop utilise MapReduce pour diviser les tâches et permettre à plusieurs machines d'effectuer des calculs en même temps.
Le deuxième mode consiste à utiliser le multi-processus. Par exemple, Nginx utilise le modèle de programmation NIO. Le maître gère le processus Worker de manière unifiée, puis le processus Worker effectue le proxy de requête réel. Cela peut également faire bon usage de plusieurs processeurs du matériel.
Le troisième mode consiste à utiliser le multi-threading, ce à quoi les programmeurs Java sont le plus exposés. Netty, par exemple, utilise le modèle de programmation Reactor et utilise également NIO, mais il est basé sur des threads. Le thread Boss est utilisé pour recevoir des demandes, puis les planifier sur les threads Worker correspondants pour des calculs commerciaux réels.
Les langages comme Golang ont une coroutine plus légère. La coroutine est une existence plus légère que les threads, mais elle n'est pas encore mature en Java, donc je ne la présenterai pas trop, mais essentiellement, c'est aussi pour le multi. -applications principales, permettant d'exécuter des tâches en parallèle.
Passer de synchrone à asynchrone
Une autre optimisation pour l'informatique consiste à passer de synchrone à asynchrone, ce qui implique généralement des changements dans le modèle de programmation. En mode synchrone, la demande sera bloquée jusqu'à ce qu'un résultat de réussite ou d'échec soit renvoyé. Bien que son modèle de programmation soit simple, il est particulièrement problématique lorsqu’il s’agit d’un trafic soudain et irrégulier sur des périodes horaires, et les requêtes peuvent facilement échouer.
Les opérations asynchrones peuvent facilement prendre en charge l'expansion horizontale, soulager la pression instantanée et fluidifier les demandes. Les requêtes synchrones sont comme des poings frappant des plaques d'acier ; les requêtes asynchrones sont comme des poings frappant des éponges. Vous pouvez imaginer ce processus, ce dernier est définitivement flexible et l’expérience est plus conviviale.
Chargement paresseux
La dernière consiste à utiliser certains modèles de conception courants pour optimiser l'entreprise et améliorer l'expérience, tels que le mode singleton, le mode proxy, etc. Par exemple, lorsque vous dessinez une fenêtre Swing, si vous souhaitez afficher plus d'images, vous pouvez d'abord charger un espace réservé, puis charger lentement les ressources requises via un thread d'arrière-plan, ce qui peut éviter que la fenêtre ne se fige.
Optimisation de l'ensemble de résultats
Ensuite, introduisons l'optimisation de l'ensemble de résultats. Pour donner un exemple plus intuitif, nous savons tous que la forme de représentation de XML est très bonne, alors pourquoi y a-t-il encore JSON ? En plus d'être plus simple à écrire, une raison importante est que sa taille est devenue plus petite et que son efficacité de transmission et son efficacité d'analyse sont devenues plus élevées. Comme le Protobuf de Google, sa taille est encore plus petite. Bien que la lisibilité soit réduite, l'efficacité peut être considérablement améliorée dans certains scénarios à forte concurrence (tels que RPC), ce qui constitue une optimisation typique des ensembles de résultats.
C'est parce que nos services Web actuels sont tous en mode C/S. Lorsque les données sont transmises du serveur au client, plusieurs copies doivent être distribuées. La quantité de données augmente rapidement. Chaque fois qu'une petite quantité de stockage est réduite, les performances et les coûts de transmission augmentent considérablement.
Comme Nginx, la compression GZIP est généralement activée pour garder le contenu transmis compact. Le client n'a besoin que d'une petite quantité de puissance de calcul pour faciliter la décompression. Cette opération étant décentralisée, la pénalité de performance est fixe.
Comprenant ce principe, nous pouvons voir l'idée générale d'optimiser les ensembles de résultats. Vous devriez essayer de garder les données renvoyées aussi simples que possible. Si certains champs ne sont pas nécessaires au client, supprimez-les dans le code ou directement dans la requête SQL.
Pour certaines entreprises qui n'ont pas d'exigences élevées en matière de rapidité mais des exigences élevées en matière de capacités de traitement. Nous devons tirer les leçons de l'expérience des tampons, minimiser les interactions de connexion réseau et utiliser le traitement par lots pour augmenter la vitesse de traitement.
L'ensemble de résultats est susceptible d'être utilisé deux fois, et vous pouvez l'ajouter au cache, mais il manque toujours de vitesse. A ce stade, il est nécessaire d'optimiser le traitement de la collecte de données, en utilisant des index ou des bitmaps Bitmap pour accélérer l'accès aux données.
Optimisation des conflits de ressources
Dans notre développement normal, nous impliquerons beaucoup de ressources partagées. Certaines de ces ressources partagées sont autonomes, comme un HashMap ; certaines sont un stockage externe, comme une ligne de base de données ; certaines sont des ressources uniques, comme Setnx d'une certaine clé Redis ; certaines sont la coordination de plusieurs ressources, telles que des transactions ; , transactions distribuées, etc.
En réalité, il existe de nombreux problèmes de performances liés aux verrous. La plupart d'entre nous pensent aux verrous de lignes de bases de données, aux verrous de tables, à divers verrous en Java, etc. Au niveau inférieur, comme les verrous au niveau des commandes du CPU, les verrous au niveau des instructions JVM, les verrous internes du système d'exploitation, etc., on peut dire qu'ils sont partout.
Seule la simultanéité peut provoquer des conflits de ressources. Autrement dit, en même temps, une seule demande de traitement peut obtenir les ressources partagées. La façon de résoudre les conflits de ressources est de verrouiller. Un autre exemple est une transaction, qui est essentiellement une sorte de verrou.
Selon le niveau de verrouillage, les verrous peuvent être divisés en verrous optimistes et verrous pessimistes. Les verrous optimistes sont nettement plus efficaces selon les types de verrous, les verrous sont divisés en verrous équitables et en verrous injustes. des différences subtiles.
Le contenu des ressources entraînera de sérieux problèmes de performances, des recherches seront donc menées sur les files d'attente sans verrouillage, et l'amélioration des performances sera énorme.
Optimisation des algorithmes
Les algorithmes peuvent améliorer considérablement les performances d'entreprises complexes, mais dans les entreprises réelles, il s'agit souvent de variations. À mesure que le stockage devient de moins en moins cher, dans certaines entreprises où le processeur est très restreint, l'espace est souvent échangé contre du temps pour accélérer le traitement.
L'algorithme appartient au réglage du code. Le réglage du code implique de nombreuses compétences en codage et nécessite que les utilisateurs soient très familiers avec l'API du langage utilisé. Parfois, l’utilisation flexible d’algorithmes et de structures de données constitue également un élément important de l’optimisation du code. Par exemple, les moyens couramment utilisés pour réduire la complexité temporelle incluent la récursivité, la bissection, le tri, la programmation dynamique, etc.
Une excellente implémentation a un plus grand impact sur le système qu’une mauvaise implémentation. Par exemple, en tant qu'implémentations de List, LinkedList et ArrayList diffèrent de plusieurs ordres de grandeur en termes de performances d'accès aléatoire ; pour un autre exemple, CopyOnWriteList utilise une méthode de copie sur écriture, qui peut réduire considérablement les conflits de verrouillage dans les scénarios où il y a plus de lecture et moins de lecture. en écrivant. Quand utiliser la synchronisation et quand être thread-safe, cela impose également des exigences plus élevées en matière de capacités de codage.
Cette partie des connaissances nous oblige à prêter attention à l'accumulation dans notre travail quotidien. Dans les cours suivants, nous sélectionnerons également des points de connaissances plus importants pour intercaler les explications.
Mise en œuvre efficace
Dans la programmation quotidienne, essayez d'utiliser certains composants avec de bons concepts de conception et des performances supérieures. Par exemple, avec Netty, vous n’êtes plus obligé de choisir les anciens composants Mina. Lors de la conception d'un système, en tenant compte des facteurs de performances, ne choisissez pas un protocole chronophage comme SOAP. Pour un autre exemple, un bon analyseur de syntaxe (comme l'utilisation de JavaCC) sera beaucoup plus efficace que les expressions régulières.
En bref, si le goulot d'étranglement du système est détecté grâce à des analyses de tests, les composants clés doivent être remplacés par des composants plus efficaces. Dans ce cas, le modèle d’adaptateur est très important. C'est pourquoi de nombreuses entreprises aiment ajouter une couche d'abstraction aux composants existants ; et lorsque les composants sous-jacents sont commutés, les applications de la couche supérieure ne s'en rendent pas compte.
Optimisation JVM
Étant donné que Java s'exécute sur la machine virtuelle JVM, bon nombre de ses fonctionnalités sont restreintes par la JVM. L'optimisation de la machine virtuelle JVM peut également améliorer dans une certaine mesure les performances des programmes JAVA. Si les paramètres sont mal configurés, cela peut même entraîner de graves conséquences telles qu'un MOO.
Le garbage collector actuellement largement utilisé est le G1. Avec très peu de configurations de paramètres, la mémoire peut être recyclée efficacement. Le garbage collector CMS a été supprimé dans Java 14. Comme son temps GC est incontrôlable, son utilisation doit être évitée si possible.
Le réglage des performances JVM implique des compromis dans tous les aspects, qui affectent souvent l'ensemble du corps, et l'impact de tous les aspects doit être pris en compte de manière globale. Par conséquent, il est particulièrement important de comprendre certains des principes de fonctionnement internes de la JVM. Cela nous aidera à approfondir notre compréhension du code et à écrire un code plus efficace.
Résumé
Ci-dessus sont les 7 directions générales de l'optimisation du code À travers une brève introduction, nous donnerons à chacun une compréhension générale du contenu de l'optimisation des performances. Ces sept directions principales sont les directions les plus importantes de l'optimisation du code. Bien entendu, l'optimisation des performances comprend également l'optimisation des bases de données, l'optimisation du système d'exploitation, l'optimisation de l'architecture et d'autres contenus. Dans les articles suivants, nous ne donnerons qu'un bref aperçu. résumé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Questions et réponses d'entretien Java (4)
- Comment résoudre les caractères chinois tronqués en Java ?
- Questions d'entretien Java résumées à partir de nombreuses années d'expérience en développement - (1)
- Questions d'entretien Java 2019 (Tencent)
- Question d'entretien Java : savez-vous ce qu'est la dépendance circulaire ? Comment Spring résout-il les dépendances circulaires ?