Maison >développement back-end >Tutoriel Python >Comparaison de quatre méthodes couramment utilisées pour localiser des éléments dans les robots Python, laquelle préférez-vous ?
Comparaison de quatre méthodes couramment utilisées pour localiser des éléments dans les robots Python, laquelle préférez-vous ?
Lors de l'utilisation de ce robot d'exploration Python pour collecter des données, une opération très importante consiste à savoir comment extraire les données de la page Web demandée, et localiser correctement les données souhaitées est la première étape.
Cet article comparera les méthodes couramment utilisées pour localiser les éléments de pages Web dans plusieurs robots d'exploration Python pour que tout le monde puisse les apprendre
basée sur Le sélecteur CSS de BeautifulSoup (avec PyQuery similaire)
<pre class="brush:php;toolbar:false;">http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1</pre><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-1.jpg" class="lazy" alt="Comparaison de quatre méthodes couramment utilisées pour localiser des éléments dans les robots Python, laquelle préférez-vous ?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%"> Prenons comme exemple le titre des 20 premiers livres. Assurez-vous d'abord que le site Web n'a pas mis en place de mesures anti-crawling et s'il peut renvoyer directement le contenu à analyser : </p><pre class="brush:php;toolbar:false;">import requests
url = &#39;http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1&#39;
response = requests.get(url).text
print(response)</pre><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-2.png" class="lazy" alt="Comparaison de quatre méthodes couramment utilisées pour localiser des éléments dans les robots Python, laquelle préférez-vous ?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%">Après une inspection minutieuse, il s'avère que toutes les données requises se trouvent dans le fichier renvoyé. contenu, indiquant qu'il n'est pas nécessaire d'envisager des mesures anti-crawling </p>
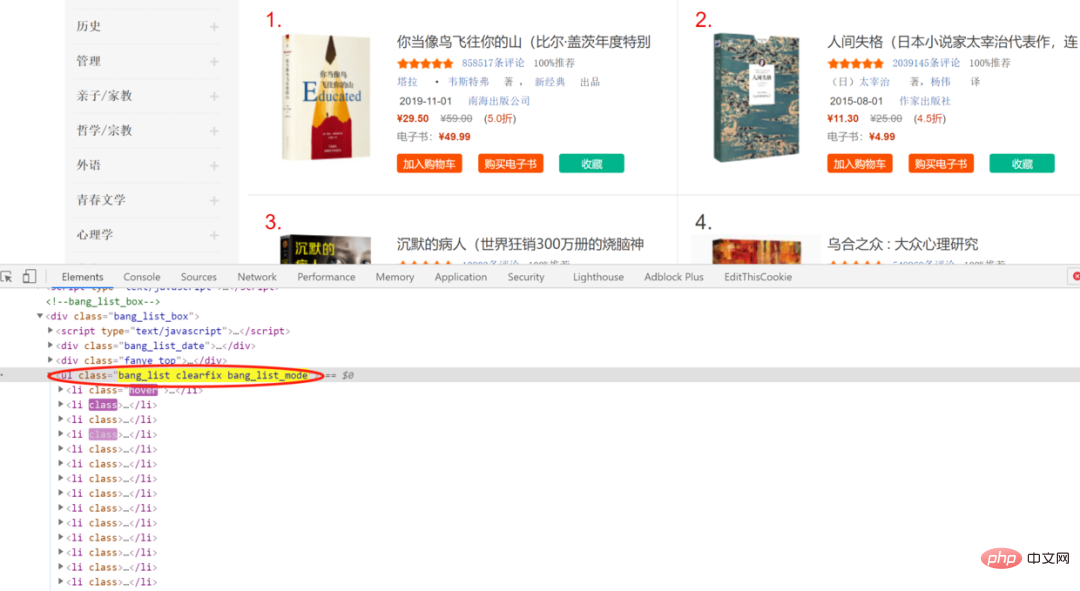
<p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;font-size: 16px;">Revoir les éléments de la page Web On pourra constater plus tard que les informations bibliographiques sont incluses dans <code style="padding: 2px 4px;border-radius: 4px;margin -droite : 2 px ; marge gauche : 2 px ; couleur d'arrière-plan : rgba (27, 31, 35, 0,05 ); famille de polices : " operator mono consolas monaco menlo monospace coupure de mots break-all rgb>li in, subordonné à class est bang_list clearfix bang_list_mode'sul dans li 中,从属于 class 为 bang_list clearfix bang_list_mode 的 ul 中
Un examen plus approfondi peut également révéler la position correspondante du titre du livre, qui constitue une base importante pour diverses méthodes d'analyse
1. Opération BeautifulSoup traditionnelle
La méthode classique BeautifulSoup utilise from bs4 import BeautifulSoup, puis transmettez soup = BeautifulSoup(html, "lxml") Convertit le texte en une structure standard spécifique, en utilisant find série de méthodes Pour l'analyse, le code est le suivant :
import requests
from bs4 import BeautifulSoup
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def bs_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个li
for li in li_list:
title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名
print(title)
if __name__ == '__main__':
bs_for_parse(response)
🎜🎜 Vous avez obtenu avec succès 20 titres de livres. Certains d'entre eux sont longs et peuvent être traités via des expressions régulières ou d'autres méthodes de chaîne. Cet article ne les présentera pas en détail🎜.
import requests
from bs4 import BeautifulSoup
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
if __name__ == '__main__':
css_for_parse(response)
3. XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装 XPath Helper 插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
if __name__ == '__main__':
xpath_for_parse(response)
4. 正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是 re






 观察几个数目相信就有答案了:
观察几个数目相信就有答案了: