
Maison >développement back-end >Tutoriel Python >Crawler | Téléchargement par lots de fonds d'écran HD (code source + outils inclus)
Crawler | Téléchargement par lots de fonds d'écran HD (code source + outils inclus)

- Python当打之年avant
- 2023-08-10 15:46:011588parcourir
Unsplash est un site Web de photos gratuit de haute qualité , la résolution photo est également très grande, pour les amis designers C'est un très bon matériel pour tout le monde, et il est également très pratique pour certains amis rédacteurs d'illustrations. Il fonctionne également bien comme fond d'écran. Le code de fonction correspondant a été intégré dans un outil exe. J'espère qu'il vous sera utile La méthode d'acquisition code + outil est jointe à la fin de l'article.
Télécharger gratuitement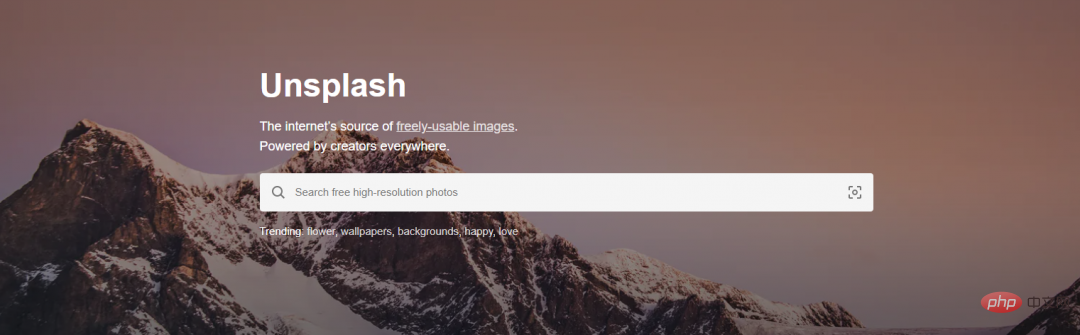 et sélectionnez le chemin de téléchargement. La taille de l'image est de 1,43 Mo.
et sélectionnez le chemin de téléchargement. La taille de l'image est de 1,43 Mo.
Ensuite,
analysez la page Web spécifique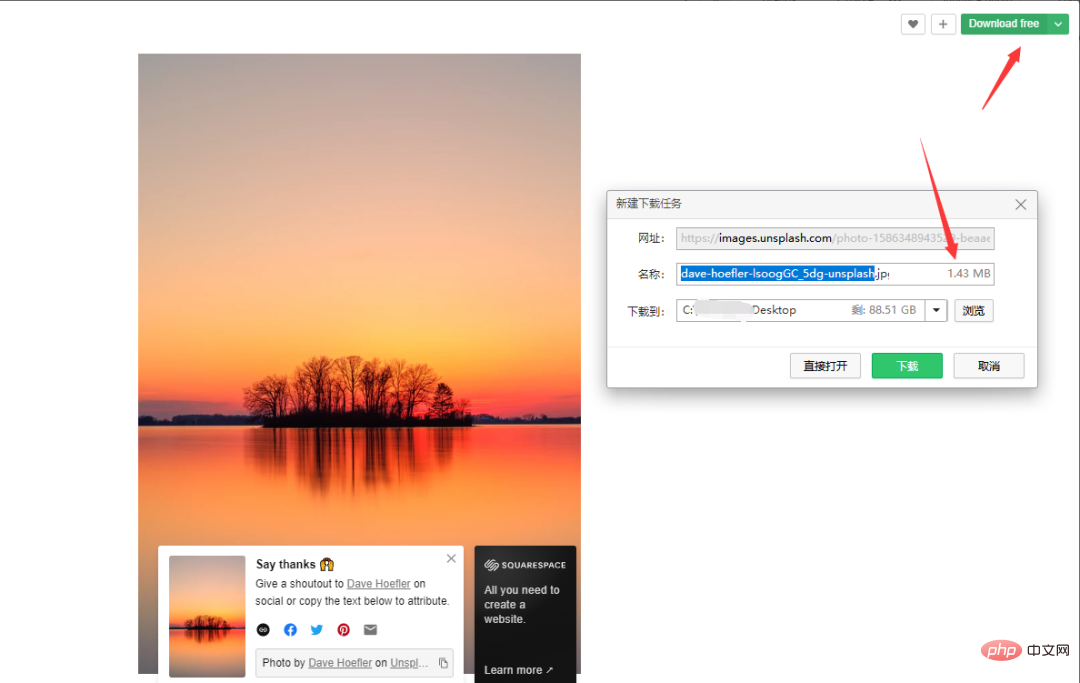
Supprimons quelques URL et jetons un œil :

Les liens ci-dessus n'ont que des paramètres de page différents, et ils augmentent dans l'ordre, ce qui est relativement convivial . Lors de la demande, ils sont en ordre. Il suffit de le parcourir.
Le problème du numéro de page a été résolu. Ensuite, analysez le lien de chaque image :
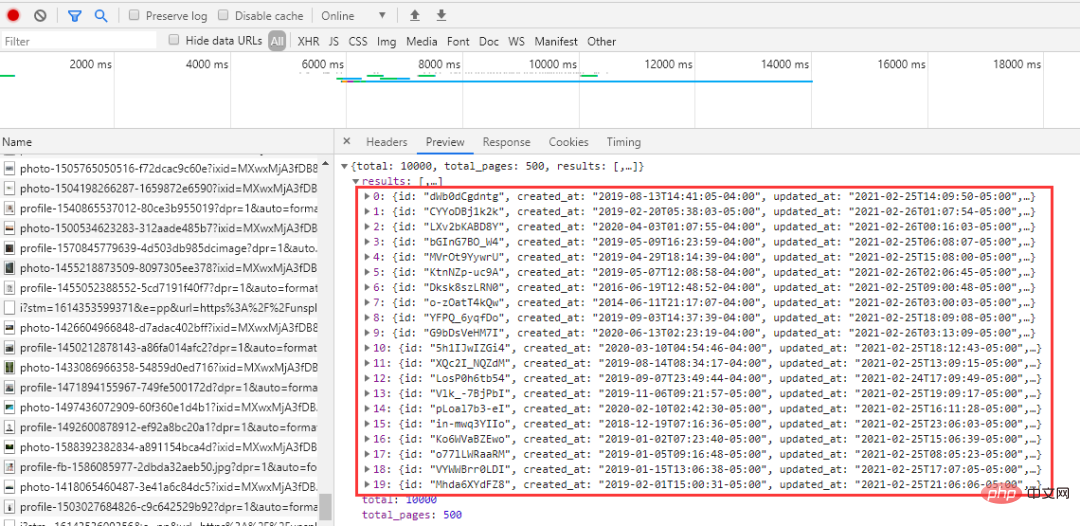
import time import random import json import requests from fake_useragent import UserAgent
- random : générer des nombres aléatoires
- json : traiter les données au format json
- requests : requêtes de pages Web
fake_useragent:代理
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)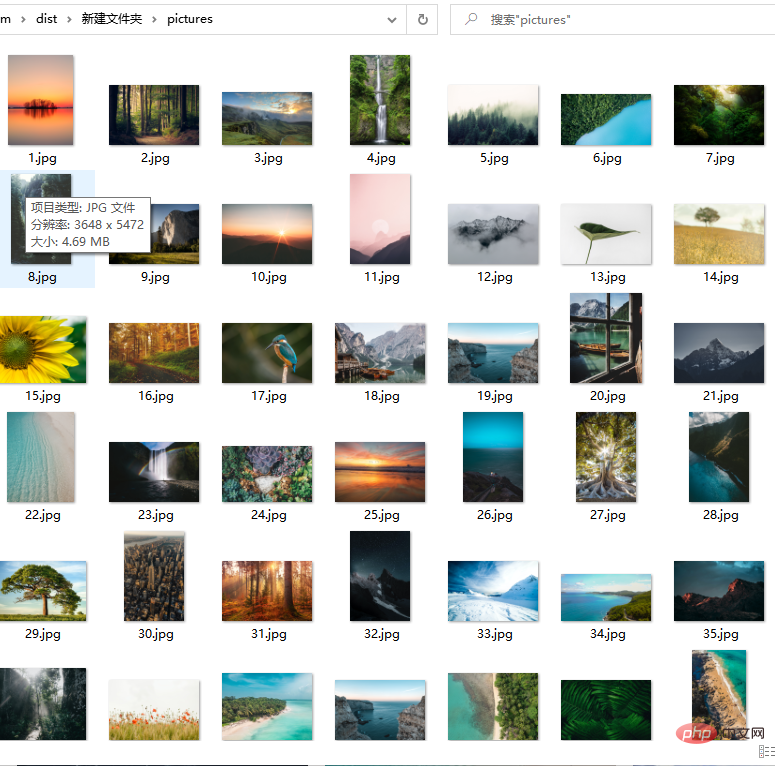
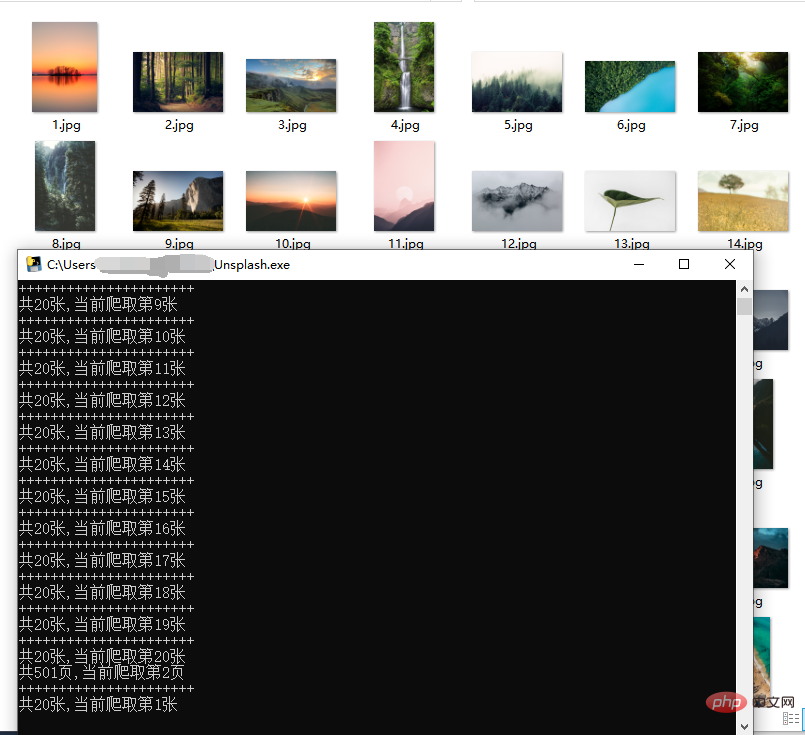
Essayez de ne pas explorer fréquemment pour éviter d'affecter l'ordre du réseau !
Les images sont des images haute définition provenant d'Internet. La vitesse d'exploration est liée au réseau et n'est généralement pas trop rapide.
Vous pouvez créer un pool de proxy pour explorer plus rapidement.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!