
Maison >interface Web >js tutoriel >Vous apprendre étape par étape comment procéder à la rétro-ingénierie de JS pour inverser l'exploration des polices et obtenir des informations à partir d'un site Web de recrutement.
Vous apprendre étape par étape comment procéder à la rétro-ingénierie de JS pour inverser l'exploration des polices et obtenir des informations à partir d'un site Web de recrutement.

- Python当打之年avant
- 2023-08-09 17:56:531101parcourir
Le site d'aujourd'hui
L'éditeur a crypté : aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8= Pour des raisons de sécurité, nous avons codé l'URL via base64 et vous pouvez obtenir l'URL via le décodage base64.
Font anti-crawling
Font anti-crawling : Technologie anti-crawling courante, il s'agit d'une stratégie anti-crawling complétée par la combinaison de pages Web et de fichiers de polices frontaux. Les premiers à utiliser l'anti-crawling de polices. -la technologie d'exploration est 58.com et Autohome. Attendez, de nombreux sites Web ou applications grand public utilisent désormais également la technologie anti-exploration des polices pour ajouter une mesure anti-exploration à leurs sites Web ou applications.
Principe d'anti-exploration des polices : Remplacez certaines données de la page par des polices personnalisées. Lorsque nous n'utilisons pas la bonne méthode de décodage, nous ne pouvons pas obtenir le contenu correct des données.
Utilisez des polices personnalisées en HTML via @font-face, comme indiqué ci-dessous :

Le format de syntaxe est :
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}Les fichiers de police sont généralement de type ttf, de type eot et les fichiers de type woff sont largement utilisés, donc tout le monde rencontre généralement des fichiers de type woff.
Prenons l'exemple du fichier de type woff, quel est son contenu et quelle méthode d'encodage est utilisée pour faire correspondre les données et le code un à un ?
Prenons comme exemple le fichier de police d'un site Web de recrutement. Entrez dans le compilateur de polices Baidu et ouvrez le fichier de police, comme indiqué dans la figure ci-dessous :

Ouvrez une police au hasard, comme indiqué dans la figure ci-dessous :
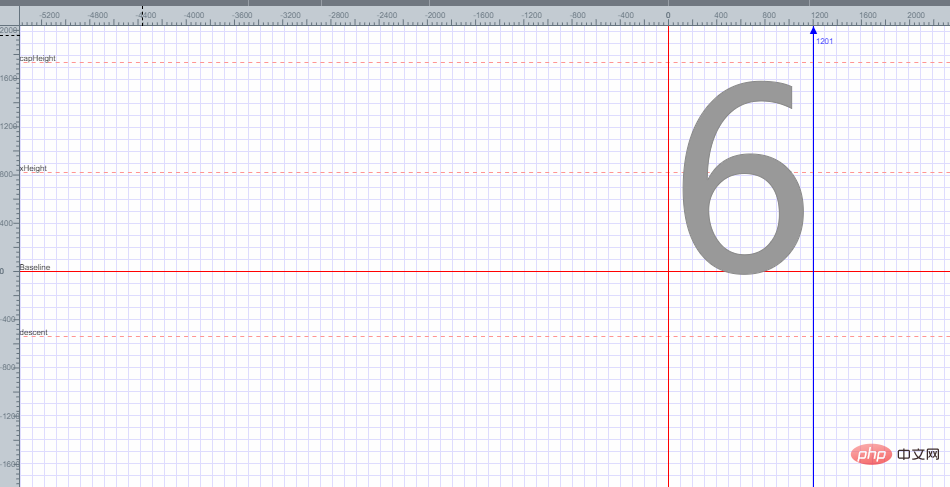
Vous pouvez trouver que la police 6 est placée dans une coordonnée plane, et l'encodage de la police 6 est obtenu en fonction de chaque point des coordonnées du plan. Je n'expliquerai pas comment obtenir l'encodage de la police 6 ici.
Comment résoudre le problème de l'anti-escalade des polices ?
Tout d'abord, la relation cartographique peut être considérée comme un dictionnaire. Il existe grosso modo deux méthodes couramment utilisées :
La première : extraire manuellement la relation correspondante entre un ensemble de codes et de caractères et l'afficher sous la forme d'un fichier. dictionnaire Le code est le suivant :
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])Définissez d'abord un dictionnaire qui correspond à la police et à son code correspondant, puis remplacez les données une par une via une boucle for.
Remarque : Cette méthode convient principalement aux données avec peu de mappages de polices.
Deuxième méthode : téléchargez d'abord le fichier de police du site Web, puis convertissez le fichier de police en fichier XML, recherchez le code de la relation de mappage de police à l'intérieur, décodez-le via la fonction de décodage, puis combinez le code décodé dans un dictionnaire. , puis selon le contenu du dictionnaire, remplacez les données une par une. Étant donné que le code est relativement long, je n'écrirai pas l'exemple de code ici. Le code de cette méthode sera montré plus tard dans l'exercice de combat proprement dit.
D'accord, parlons brièvement de l'anti-crawling des polices. Ensuite, nous explorerons officiellement un site Web de recrutement.
Exercice pratique
Recherche de fichiers de polices personnalisées
Entrez d'abord sur un site Web de recrutement et ouvrez le mode développeur, comme indiqué dans l'image ci-dessous :
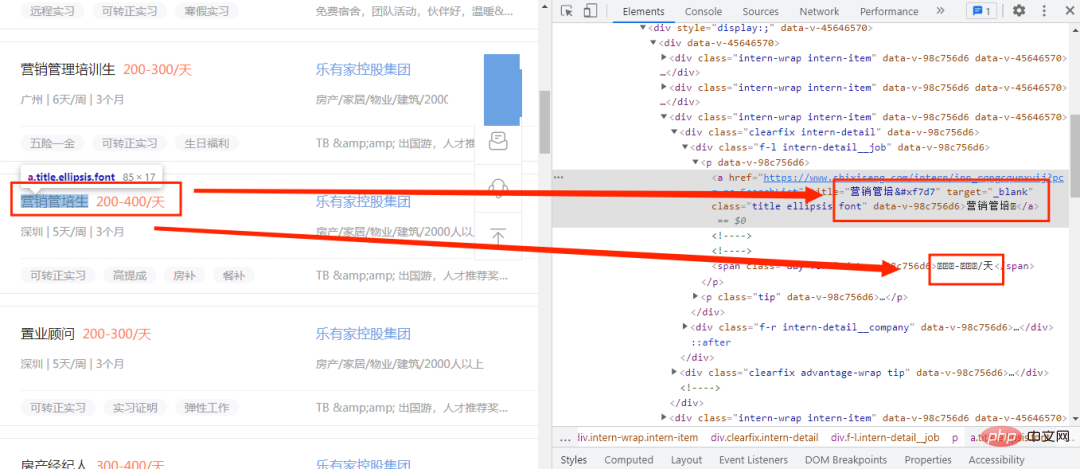
Ici, nous voyons que seuls les nouveaux mots dans le code ne peuvent pas fonctionner normalement, mais sont remplacés par des codes. Il est initialement déterminé qu'un fichier de police personnalisé est utilisé. À ce stade, nous devons donc trouver le fichier de police. où trouver le fichier de police ? Eh bien, ouvrez d'abord le mode développeur et cliquez sur l'option Réseau, comme indiqué dans l'image ci-dessous :
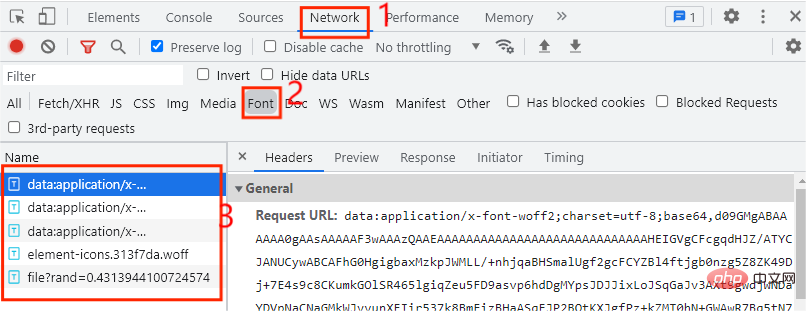
Généralement, le fichier de police est placé dans l'onglet Police. Il y a un total de 5 entrées ici, alors laquelle est personnalisée ? Quant aux entrées du fichier de police, le fichier de police personnalisé sera exécuté une fois à chaque fois que nous cliquons sur la page suivante. À ce stade, il nous suffit de cliquer sur la page suivante. page dans la page Web, comme le montre la figure ci-dessous :
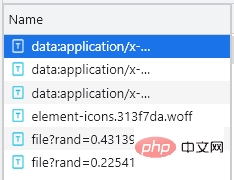
Vous pouvez voir qu'il y a une entrée supplémentaire commençant par file. À ce stade, vous pouvez initialement déterminer que le fichier est un fichier de police personnalisé. téléchargez-le. La méthode de téléchargement est très simple. Il vous suffit de copier l'URL de l'entrée commençant par le fichier et de la placer. Après l'avoir téléchargé, ouvrez-la dans le compilateur de polices Baidu, comme indiqué dans la page Web. image ci-dessous :
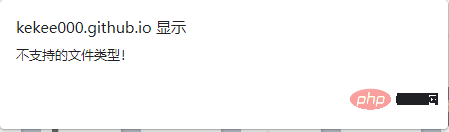
À ce moment-là, j'ai constaté qu'il ne pouvait pas être ouvert. Ai-je trouvé le mauvais fichier de police ? Le site Web a indiqué que ce type de fichier n'est pas pris en charge. Ensuite, nous modifions le suffixe du fichier téléchargé en. .woff et essayez de l'ouvrir, comme indiqué dans l'image ci-dessous :

Il est ouvert avec succès à ce moment-là.
Relation de mappage de polices
Le fichier de police personnalisé est trouvé, alors comment l'utiliser ? À ce stade, nous personnalisons d'abord la méthode get_fontfile() pour traiter le fichier de police personnalisé, puis affichons la relation de mappage dans le fichier de police via un dictionnaire en deux étapes.
Téléchargement et conversion de fichiers de polices ; Décodage des relations de mappage de polices.
Téléchargement et conversion du fichier de police
Tout d'abord, la fréquence de mise à jour du fichier de police personnalisée est très élevée. À ce stade, nous pouvons obtenir le fichier de police personnalisé de la page Web en temps réel pour éviter le problème. le fichier de police personnalisé précédent n'est plus utilisé, ce qui entraîne une acquisition de données inexacte. Observez d'abord le lien URL du fichier de police personnalisée :
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
字体解码及展现
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
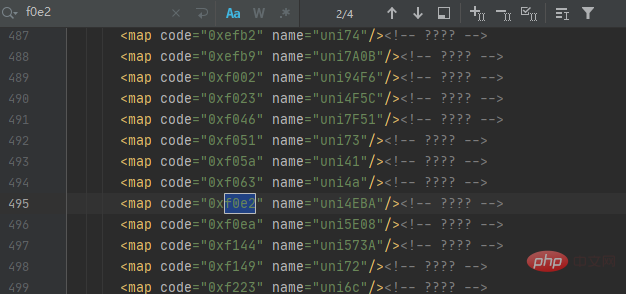
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

获取招聘数据
在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
保存数据
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()启动程序
好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)结果展示
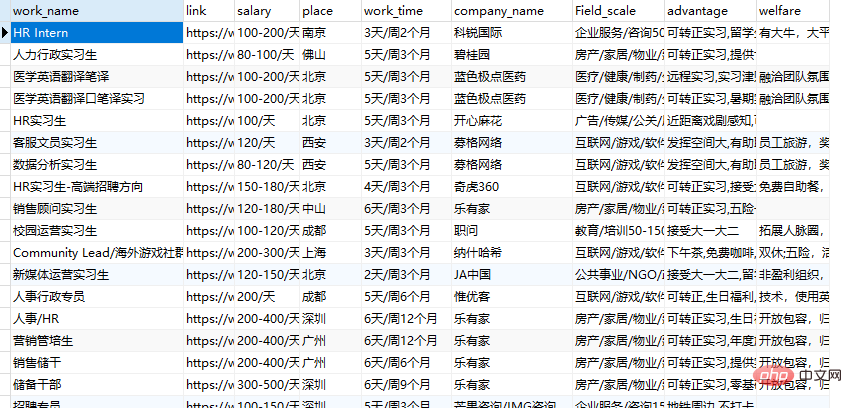
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer des éléments à des positions spécifiées dans le tableau js ? 2 façons de supprimer des éléments à des positions spécifiées
- Qu'est-ce qu'un fichier js ? Comment ouvrir le fichier js ?
- Quelles sont les façons d'introduire des fichiers js dans vue
- Comment effectuer le remplacement de chaîne en js
- Comment déterminer si une chaîne est vide en js