
Maison >Opération et maintenance >exploitation et maintenance Linux >Collection ultra-complète - Collection récapitulative des outils d'analyse des performances Linux
Collection ultra-complète - Collection récapitulative des outils d'analyse des performances Linux
- Linux中文社区avant
- 2023-08-03 16:20:121257parcourir
Par intérêt pour le système d'exploitation Linux et par fort désir de connaissances sous-jacentes, j'ai compilé cet article. Cet article peut également être utilisé comme indicateur pour tester les connaissances de base. De plus, l'article couvre tous les aspects d'un système. Sans une connaissance complète du système informatique, des réseaux et du système d'exploitation, il est impossible de maîtriser pleinement les outils du document. De plus, l'analyse et l'optimisation des performances du système sont une série à long terme.
Ce document est principalement un article complet basé sur le billet de blog de l'architecte principal des performances de Netflix, Brendan Gregg, mettant à jour les outils de réglage des performances Linux et rassemblant des articles liés à l'optimisation des performances du système Linux. Combiné avec le billet de blog, les principes et. les outils de test de performances impliqués seront expliqués.
Connaissances de base : avoir des connaissances de base est ce que vous devez savoir lors de l'analyse des problèmes de performances. Par exemple, le cache matériel ; un autre exemple est le noyau du système d’exploitation. Les détails comportementaux de l'application sont souvent liés à ces éléments. Ces éléments de bas niveau peuvent affecter les performances de l'application de manière inattendue. Par exemple, certains programmes ne peuvent pas utiliser pleinement le cache, ce qui entraîne une dégradation des performances. Par exemple, trop d'appels système sont appelés inutilement, provoquant des changements fréquents noyau/utilisateur, etc. C'est juste pour ouvrir la voie au contenu de suivi de cet article. Il y a encore beaucoup de choses sur le réglage, je n'en sais pas beaucoup plus que j'espère que tout le monde pourra apprendre et progresser ensemble.
【Outil d'analyse des performances】
Tout d'abord, regardons une image :
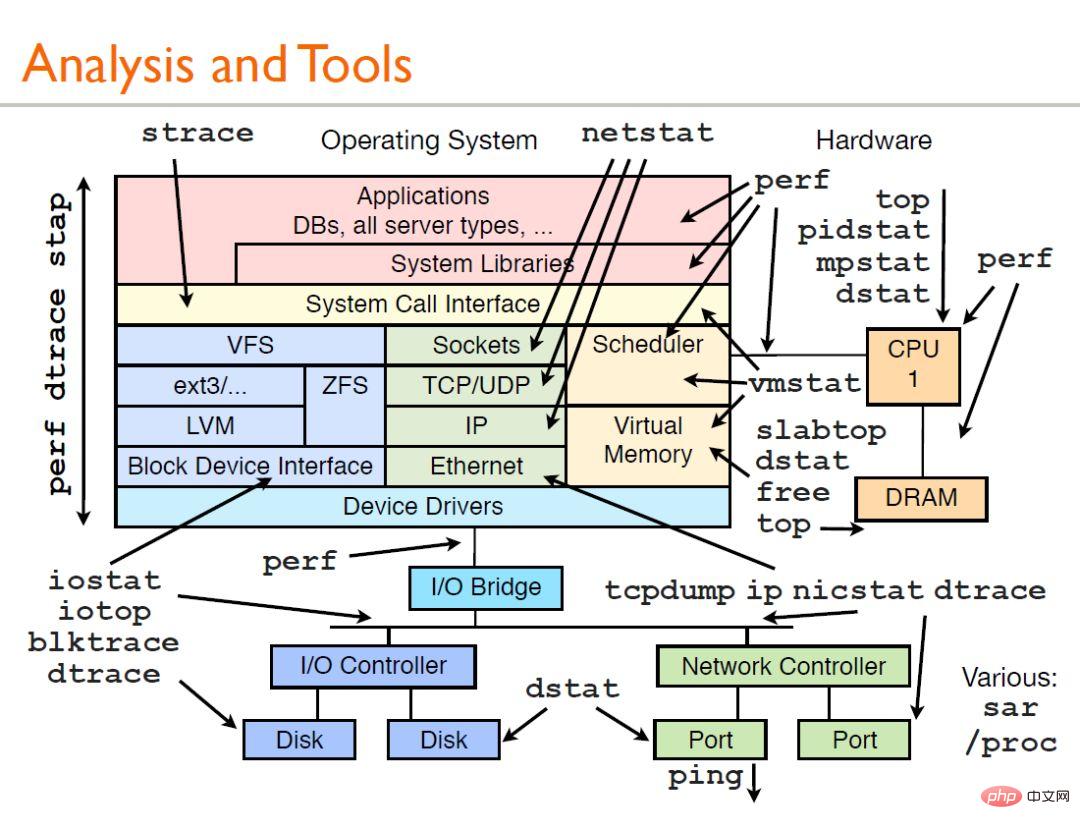
L'image ci-dessus est une analyse des performances partagée par Brendan Gregg Tous les outils ici peuvent obtenir leurs documents d'aide via l'homme. Donnons une brève introduction Utilisation conventionnelle : .
▲ vmstat - statistiques de mémoire virtuelle
vmstat (VirtualMeomoryStatistics, statistiques de mémoire virtuelle) est un outil courant pour surveiller la mémoire sous Linux. Il peut surveiller la mémoire virtuelle, les processus et le processeur du système d'exploitation. Surveiller la situation globale.
Utilisation générale de vmstat : les temps d'intervalle vmstat signifient un échantillonnage une fois toutes les secondes d'intervalle, le nombre total de temps d'échantillonnage. Si les temps sont omis, les données seront collectées jusqu'à ce que l'utilisateur l'arrête manuellement.
Un exemple simple :

Vous pouvez utiliser ctrl+c pour arrêter la collecte de données par vmstat.
La première ligne montre la moyenne depuis le démarrage du système, la deuxième ligne commence à montrer ce qui se passe maintenant, les lignes suivantes montreront ce qui se passe toutes les 5 secondes, la signification de chaque colonne est dans l'en-tête, comme suit Affichage :
without Les procs : la colonne r indique combien de processus attendent le processeur, et la colonne b indique combien de processus sont en veille ininterrompue (en attente d'IO).
memory : la colonne swapd indique combien de blocs ont été échangés hors du disque (échange de pages), les colonnes restantes indiquent combien de blocs sont libres (non utilisés) et combien de blocs sont utilisés comme tampons. , et quelle quantité est utilisée comme cache du système d'exploitation.
swap : affiche l'activité d'échange : combien de blocs sont échangés (à partir du disque) et échangés (vers le disque) par seconde.
produced io : affiche le nombre de blocs lus (bi) et écrits (bo) à partir du périphérique bloc, reflétant généralement les E/S du disque dur.
without système : affiche le nombre d'interruptions (in) et de changements de contexte (cs) par seconde.
❤️ CPU : affiche le pourcentage de tout le temps CPU consacré à diverses opérations, y compris l'exécution du code utilisateur (hors noyau), l'exécution du code système (noyau), l'inactivité et l'attente des E/S.
Symptômes de mémoire insuffisante : la mémoire libre diminue fortement, le recyclage des tampons et des caches n'aide pas, utilisation intensive des partitions de swap (swpd), échanges fréquents de pages (swap), augmentation du nombre de disques de lecture et d'écriture (io) , et les défauts de page (in) augmentent, le nombre de changements de contexte (cs) augmente, le nombre de processus en attente d'IO (b) augmente et beaucoup de temps CPU est passé à attendre IO (wa)
▲iostat - pour rapporter les statistiques de l'unité centrale de traitement
iostat pour rapporter les statistiques de l'unité centrale de traitement (CPU) et les statistiques d'entrée/sortie pour l'ensemble du système, les adaptateurs, les périphériques tty, les disques et les CD-ROM, qui affiche les mêmes informations sur l'utilisation du processeur comme vmstat par défaut, utilisez la commande suivante pour afficher les statistiques étendues de l'appareil :

La première ligne affiche la moyenne depuis le démarrage du système, puis la moyenne incrémentielle, une ligne par appareil.
Habitudes courantes d'abréviation de l'indicateur IO de disque Linux : rq est une demande, r est une lecture, w est une écriture, qu est une file d'attente, sz est une taille, a est une moyenne, tm est une heure et svc est un service.
❤️rrqm/s et wrqm/s : requêtes de lecture et d'écriture combinées par seconde, "coalescées" signifie que le système d'exploitation retire plusieurs requêtes logiques de la file d'attente et les fusionne en une seule requête sur le disque réel.
❤️r/s et w/s : Nombre de requêtes de lecture et d'écriture envoyées à l'appareil par seconde.
withoutrsec/s et wsec/s : Nombre de secteurs lus et écrits par seconde.
withoutavgrq –sz : Nombre de secteurs demandé.
withoutavgqu –sz : Nombre de requêtes en attente dans la file d'attente de l'appareil.
❤️await : Le temps passé sur chaque demande d'IO.
❤️svctm : heure réelle de la demande (service).
without%util : Le pourcentage de temps pendant lequel il y a eu au moins une demande active.
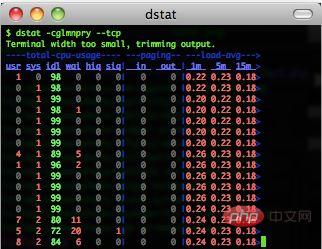
▲dstat - outil de surveillance du système
dstat affiche l'utilisation du processeur, l'état des entrées/sorties du disque, l'état d'envoi des paquets réseau et l'état de changement de page. La sortie est colorée et très lisible par rapport à l'entrée de. vmstat et iostat sont plus détaillés et intuitifs. Lorsque vous l'utilisez, entrez simplement la commande directement, et bien sûr vous pouvez également utiliser des paramètres spécifiques.
est la suivante : dstat –cdlmnpsy
▲outil de surveillance en temps réel des processus LINUX
La commande iotop est une commande spécifiquement destinée à afficher les E/S du disque dur. Le style est similaire à la commande top et peut être affiché Quel processus génère spécifiquement la charge IO. Il s'agit d'un outil de pointe utilisé pour surveiller l'utilisation des E/S du disque. Il possède une interface utilisateur similaire à celle de top, comprenant le PID, l'utilisateur, les E/S, le processus et d'autres informations connexes.
kann auf nicht interaktive Weise verwendet werden: iotop –bod-Intervall. Um die E/A jedes Prozesses anzuzeigen, können Sie pidstat, pidstat –d instat verwenden.
Durchsuchen Sie das offizielle Backend der chinesischen Linux-Community und antworten Sie auf „Private Küche“, um ein Überraschungsgeschenkpaket zu erhalten. PIDSTAT – Systemressourcen überwachen .
Verwendung: pidstat –d Intervall; pidstat kann auch zum Zählen von CPU-Nutzungsinformationen verwendet werden: pidstat –u Intervall, um Speicherinformationen zu zählen: Pidstat –r Intervall.
▲
top
Der Zusammenfassungsbereich des Befehls top zeigt fünf Aspekte der Systemleistungsinformationen an:
1. Charge : temps, nombre d'utilisateurs connectés, charge moyenne du système ;
2. Processus : exécution, veille, arrêt, zombie
3.cpu : mode utilisateur, mode principal, NICE ; , inactif, en attente d'IO, d'interruptions, etc.
4. Mémoire : totale, utilisée, libre (perspective du système), tampon, cache
5.
La zone des tâches affiche par défaut : l'ID du processus, l'utilisateur effectif, la priorité du processus, la valeur NICE, la mémoire virtuelle, la mémoire physique et la mémoire partagée utilisées par le processus, l'état du processus, l'utilisation du processeur, l'utilisation de la mémoire, le temps CPU accumulé et la commande de processus. informations sur la ligne.
▲htop
htop est un visualiseur de processus interactif dans les systèmes Linux, une application en mode texte (dans la console ou le terminal X), nécessite ncurses.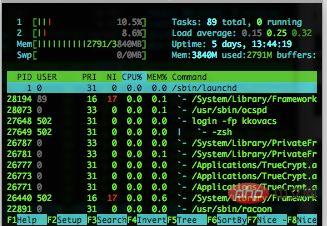
Par rapport à top, htop présente les avantages suivants : without Vous pouvez faire défiler la liste des processus horizontalement ou verticalement pour voir tous les processus et la ligne de commande complète. ▪ Plus rapide que top au démarrage. ▪ Il n'est pas nécessaire de saisir l'ID du processus lors de la suppression d'un processus. without htop prend en charge les opérations de la souris. ▲mpstat ▲netstat Netstat est utilisé pour afficher des statistiques liées aux protocoles IP, TCP, UDP et ICMP, et est généralement utilisé pour vérifier la connexion réseau de chaque port de la machine. ▲Utilisation courante : netstat –npl peut vérifier si le port que vous souhaitez ouvrir est déjà ouvert. netstat –rn Imprimer les informations de la table de routage. netstat –in Fournit des informations sur l'interface du système, imprime le MTU de chaque interface, le nombre de paquets d'entrée, les erreurs d'entrée, le nombre de paquets de sortie, les erreurs de sortie, les conflits et la longueur actuelle de la file d'attente de sortie. ▲ps --afficher l'état du processus en cours ps a trop de paramètres Pour une utilisation spécifique, veuillez vous référer à man ps. #hsserver; ps – ef |grep #hundsun ❤️ Méthode pour tuer un certain programme : ps aux | grep mysqld | le processus zombie : ps –eal awk '{if ($2 == "Z"){print $4}}' | Suivez les appels système et les signaux reçus pendant l'exécution du programme pour aider à analyser les situations anormales rencontrées lors de l'exécution du programme ou de la commande. Exemple : Pour vérifier quel fichier de configuration mysqld charge sous Linux, vous pouvez exécuter la commande suivante : strace –e stat64 mysqld –print –defaults > ▲ lsof Afficher le système de fichiers bloquant lsof /boot Afficher quels fichiers sont ouverts par l'utilisateur lsof –u nom d'utilisateur Afficher quels fichiers sont ouverts par le processus lsof –p 4838 Afficher les liens réseau ouverts à distance lsof –i @192.168.34.128 ▲perf perf est l'outil d'optimisation des performances du système fourni avec le noyau Linux. L'avantage réside dans son intégration étroite avec le noyau Linux. Il peut être le premier à être appliqué aux nouvelles fonctionnalités ajoutées au noyau, qui peuvent être utilisées pour afficher les fonctions chaudes et les taux d'échec en espèces, aidant ainsi les développeurs à optimiser les performances du programme. Le principe de base des outils de réglage des performances tels que perf, Oprofile, etc. est d'échantillonner l'objet surveillé. Le cas le plus simple est d'échantillonner en fonction de l'interruption de tick, c'est-à-dire que le point d'échantillonnage est déclenché à l'intérieur. l'interruption de tick. Cliquez ici pour déterminer le contexte actuel du programme. Si un programme passe 90 % de son temps dans la fonction foo(), alors 90 % des points d'échantillonnage devraient tomber dans le contexte de la fonction foo(). La chance est insaisissable, mais je pense que tant que la fréquence d'échantillonnage est suffisamment élevée et que le temps d'échantillonnage est suffisamment long, l'inférence ci-dessus sera plus fiable. Par conséquent, en déclenchant l'échantillonnage par tick, nous pouvons comprendre quelles parties du programme consomment le plus de temps et nous concentrer sur l'analyse. Si vous souhaitez en savoir plus sur cet outil, vous pouvez vous référer à : Résumé : en combinant les commandes de test de performances couramment utilisées ci-dessus et en contactant le diagramme des outils d'analyse des performances au début de l'article, vous pouvez dans un premier temps comprendre quel aspect de la performance utilise quel outil (commande) pendant le processus d'analyse des performances. 【Outils de test de performances couramment utilisés】 Maîtrisant et maîtrisant les outils de commande d'analyse des performances dans la deuxième partie, introduisons plusieurs outils de test de performances Avant de présenter, comprenons brièvement quelques outils de test de performances : without perf_events : Un outil de diagnostic des performances publié et maintenu avec le code du noyau Linux, maintenu et développé par la communauté du noyau. Perf peut être utilisé non seulement pour l'analyse statistique des performances des applications, mais également pour les statistiques de performances et l'analyse du code du noyau. Plus de références : http://blog.sina.com.cn/s/blog_98822316010122ex.html. Outils eBPF : outil de suivi des performances utilisant Cci, la carte eBPF peut être largement utilisée dans le réglage du noyau à l'aide de programmes eBPF personnalisés et peut également lire du code asynchrone au niveau de l'utilisateur. L'important est que ces données externes puissent être gérées dans l'espace utilisateur. Ce corps de données cartographiques au format k-v est géré en appelant l'appel système bpf dans l'espace utilisateur pour créer, ajouter, supprimer et d'autres opérations. plus : http://blog.csdn.net/ljy1988123/article/details/50444693. lessness perf-tools : Un ensemble d'outils d'analyse et de réglage des performances Linux basé sur perf_events (perf) et ftrace. Perf-Tools a peu de dépendances de bibliothèque et est facile à utiliser. Prend en charge les versions de noyau Linux 3.2 et supérieures. plus : https://github.com/brendangregg/perf-tools. without bcc (BPF Compiler Collection) : Un outil d'analyse des performances des performances utilisant eBPF. Une boîte à outils pour créer des programmes efficaces de traçage et de manipulation du noyau, comprenant plusieurs outils et exemples utiles. Profitez de Extended BPF (Berkeley Packet Filter), officiellement appelé eBPF, une nouvelle fonctionnalité qui a été ajoutée pour la première fois à Linux 3.15. La polyvalence nécessite Linux 4.1 ou supérieur BCC. Plus de références : https://github.com/iovisor/bcc#tools. producedktap : Un nouveau type d'outil de suivi dynamique des performances pour les scripts Linux. Permet aux utilisateurs de suivre la dynamique du noyau Linux. ktap est conçu pour être interopérable, permettant aux utilisateurs d'ajuster les informations opérationnelles, de dépanner et d'étendre les noyaux et les applications. Il est similaire à Linux et Solaris DTrace SystemTap. Plus de référence : https://github.com/ktap/ktap. without Flame Graphs : C'est un logiciel graphique qui utilise perf, system tap, ktap visualisation, permettant d'identifier rapidement et précisément les chemins de code les plus fréquents, vous pouvez utiliser github.com/brendangregg/ flamegraph Génération procédurale du code source de développement. Plus de références : http://www.brendangregg.com/flamegraphs.html. without Les outils de base à apprendre en premier sont les suivants : ❤️ Les commandes avancées sont les suivantes : Plus de référence : http://www.open-open.com/lib/view/open1434589043973.html Pour une utilisation détaillée des commandes, veuillez vous référer à man est un outil d'évaluation des performances. Vous pouvez utiliser les outils correspondants pour tester les performances des différents modules. Si vous souhaitez en savoir plus, vous pouvez vous référer au document ci-dessous. 3. Outils de réglage Linux | Outil de réglage des performances Linux 4. Linux observabilité sar | Outil d'observation des performances Linux sar (rapport d'activité du système System Activity Reporter) est actuellement l'un des outils d'analyse des performances système les plus complets sur LINUX, qui peut être utilisé dans de nombreux aspects Signalent les activités du système, notamment : la lecture et l'écriture de fichiers, l'utilisation des appels système, les E/S de disque, l'efficacité du processeur, l'utilisation de la mémoire, les activités de processus et les activités liées à l'IPC. sar est couramment utilisé : sar [options] [-A] [-o fichier] t [n]
mpstat est l'abréviation de Multiprocessor Statistics et est un outil de surveillance du système en temps réel. Il rapporte des informations statistiques sur le processeur, qui sont stockées dans le fichier /proc/stat. Dans un système multi-CPU, il peut non seulement afficher les informations d'état moyen de tous les processeurs, mais également afficher les informations d'un processeur spécifique. Usage courant : mpstat –P TOUS les temps d'intervalle.
http://blog.csdn.net/trochiluses/article/details/10261339
1. Outils d'observabilité Linux | Outils d'observation des performances Linux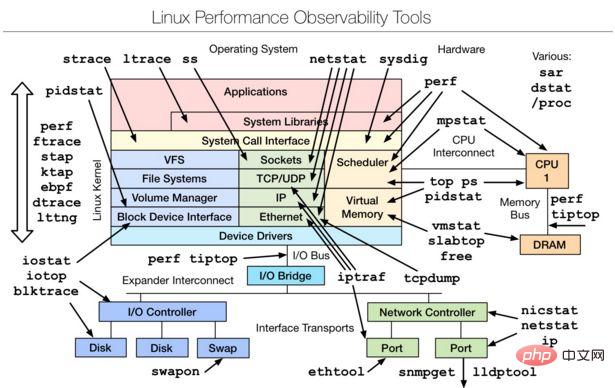
uptime, top(htop), mpstat, isstat, vmstat, free, ping, nicstat, dstat.
sar, netstat, pidstat, strace, tcpdump, blktrace, iotop, slabtop, sysctl, /proc.
2. Outils d'analyse comparative Linux | L'outil d'évaluation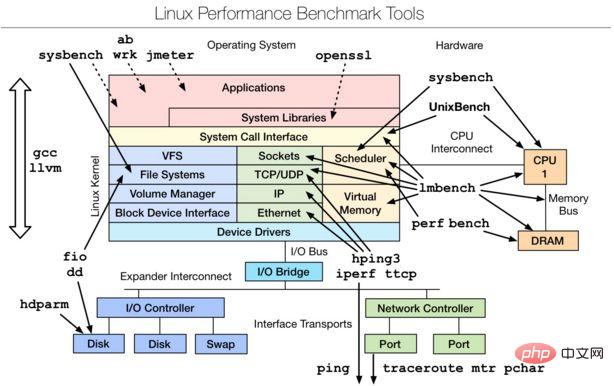
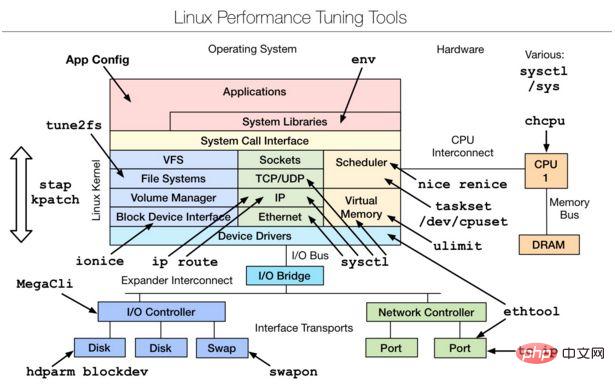
est un outil de réglage des performances qui effectue principalement le réglage à partir de la couche de code source du noyau Linux. peut se référer au document ci-joint. 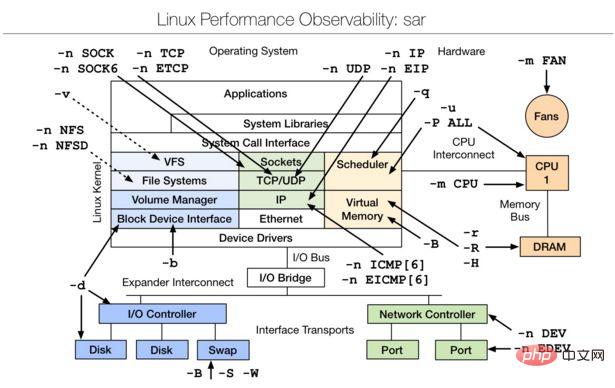
où :
t est l'intervalle d'échantillonnage, n est le nombre d'échantillonnages , La valeur par défaut est 1 ;
-o fichier signifie stocker les résultats de la commande au format binaire dans un fichier, où fichier est le nom du fichier.
les options sont des options de ligne de commande
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!