
Maison >Problème commun >Connu comme le système de surveillance de nouvelle génération, voyons à quel point il est puissant !
Connu comme le système de surveillance de nouvelle génération, voyons à quel point il est puissant !
- Linux中文社区avant
- 2023-08-03 15:40:151777parcourir

Prometheus est un système de surveillance et d'alarme open source basé sur une base de données de séries chronologiques. En parlant de Prometheus, nous devons mentionner SoundCloud, qui est une plateforme de partage de musique en ligne, similaire à YouTube pour le partage de vidéos. À mesure qu'ils progressent sur la voie de l'architecture des microservices, avec l'apparition de centaines ou de milliers de services, l'utilisation des systèmes de surveillance traditionnels StatsD et Graphite présente de nombreuses limites.
Ils ont donc commencé à développer un nouveau système de surveillance en 2012. L'auteur original de Prometheus est Matt T. Proud, qui a également rejoint SoundCloud en 2012. En fait, avant de rejoindre SoundCloud, Matt travaillait chez Google. Il s'est inspiré du gestionnaire de cluster de Google, Borg, et de son système de surveillance Borgmon, pour développer l'open. système de surveillance des sources Prometheus Comme de nombreux projets Google, le langage de programmation utilisé est Go.
Évidemment, en tant que solution de système de surveillance de l'architecture des microservices, Prometheus est également indissociable des conteneurs. Dès le 9 août 2006, Eric Schmidt a proposé pour la première fois le concept de cloud computing (Cloud Computing) lors de la Search Engine Conference. Au cours des dix années suivantes, le développement du cloud computing a été rapide.
En 2013, Matt Stine de Pivotal a proposé le concept de Cloud Native. Cloud Native se compose d'une architecture de microservices, de DevOps et d'une infrastructure agile représentée par des conteneurs pour aider les entreprises à fournir des logiciels de manière rapide, continue et fiable.
Afin d'unifier les interfaces de cloud computing et les normes associées, en juillet 2015, la Cloud Native Computing Foundation (CNCF), affiliée à la Linux Foundation, a vu le jour. Le premier projet à rejoindre le CNCF était Kubernetes de Google, et Prometheus a été le deuxième à le rejoindre (en 2016).
1. Présentation de Prometheus
Nous pouvons trouver un article sur le blog officiel de SoundCloud expliquant pourquoi ils doivent développer un nouveau système de surveillance, Prometheus : Monitoring at SoundCloud. Dans cet article, ils ont présenté, Le système de surveillance qu'ils ont. Le besoin doit répondre aux quatre caractéristiques suivantes :
Un modèle de données multidimensionnel, afin que les données puissent être découpées en tranches et en dés à volonté, selon des dimensions telles que l'instance, le service, le point de terminaison et la méthode. Simplicité opérationnelle, pour que vous puissiez démarrer un serveur de surveillance où et quand vous le souhaitez, même sur votre poste de travail local, sans configurer un backend de stockage distribué ni reconfigurer le monde. Collecte de données évolutive et architecture décentralisée, afin que vous puissiez surveiller de manière fiable les nombreuses instances de vos services, et que des équipes indépendantes puissent configurer des serveurs de surveillance indépendants. Enfin, un langage de requête puissant qui exploite le modèle de données pour des alertes significatives (y compris une mise sous silence facile) et des graphiques (pour les tableaux de bord et pour l'exploration ad hoc).
Simplement parlant, il s'agit des quatre caractéristiques suivantes :
"Modèle de données multidimensionnel" Cette fonctionnalité correspond exactement à ce dont a besoin une base de données de séries chronologiques. Prometheus n'est donc pas seulement un système de surveillance, mais également une base de données de séries chronologiques. Alors pourquoi Prometheus n'utilise-t-il pas directement la base de données de séries chronologiques existante comme stockage principal ? En effet, SoundCloud souhaite non seulement que son système de surveillance ait les caractéristiques d'une base de données de séries chronologiques, mais doit également être très facile à déployer et à entretenir.- En regardant les bases de données de séries chronologiques les plus populaires (voir l'annexe ci-dessous), elles ont soit trop de composants, soit de lourdes dépendances externes. Par exemple : Druid a un tas de composants tels que Historical, MiddleManager, Broker, Coordination, Overlord et. Routeur, et cela dépend aussi de Pour ZooKeeper, du stockage profond (HDFS ou S3, etc.), du magasin de métadonnées (PostgreSQL ou MySQL), les coûts de déploiement et de maintenance sont très élevés. Prometheus utilise une architecture décentralisée qui peut être déployée indépendamment et ne repose pas sur un stockage distribué externe. Vous pouvez créer un système de surveillance en quelques minutes. De plus, la méthode de collecte de données Prometheus est également très flexible. Pour collecter les données de surveillance de la cible, vous devez d'abord installer le composant de collecte de données sur la cible. Il collectera les données de surveillance sur la cible et exposera une interface HTTP pour que Prometheus les collecte via Pull. . Data, c'est différent du mode Push traditionnel.
- Cependant, Prometheus fournit également un moyen de prendre en charge le mode Push. Vous pouvez transmettre vos données vers Push Gateway, et Prometheus obtient les données de Push Gateway via Pull. L'exportateur actuel peut déjà collecter la plupart des données tierces, telles que Docker, HAProxy, StatsD, JMX, etc. Le site officiel propose une liste d'exportateurs.
En plus de ces quatre fonctionnalités majeures, à mesure que Prometheus continue de se développer, il commence à prendre en charge des fonctionnalités de plus en plus avancées, telles que : la découverte de services, un affichage de graphiques plus riche, l'utilisation de stockage externe, des règles d'alarme puissantes et diverses méthodes de notification.
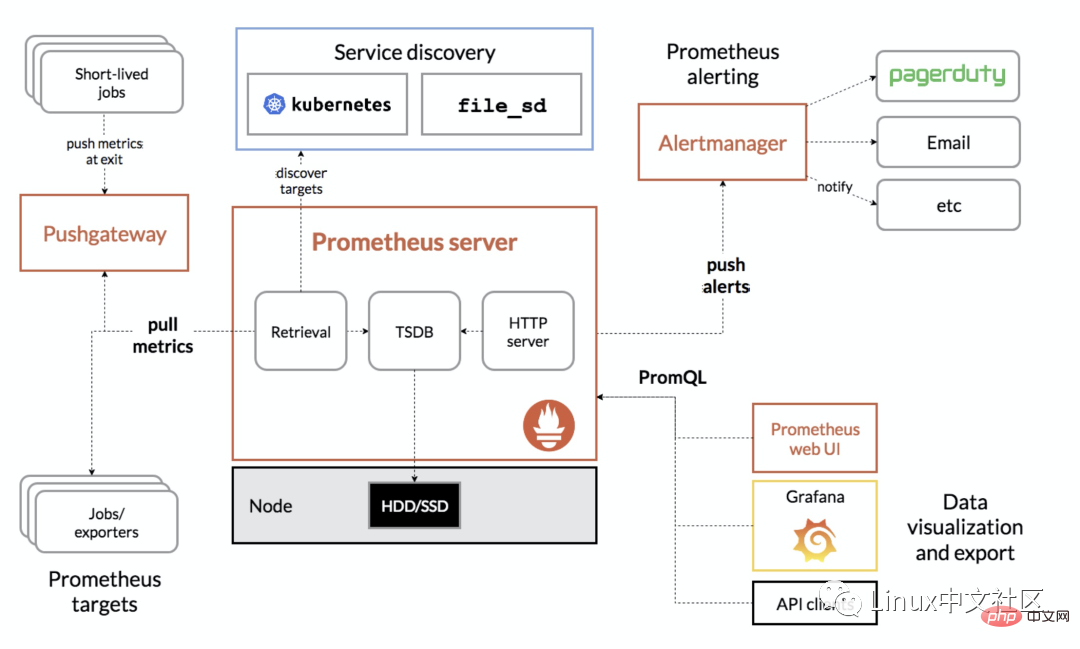
L'image suivante est le schéma global de l'architecture de Prometheus :

Comme le montre l'image ci-dessus, l'écosystème Prometheus comprend plusieurs composants clés : serveur Prometheus, Pushgateway, Alertmanager, Web UI, etc. , mais la plupart des composants de grande taille ne sont pas requis, et le composant principal est bien sûr le serveur Prometheus, qui est responsable de la collecte et du stockage des données d'indicateur, de la prise en charge des requêtes d'expression et de la génération d'alarmes. Ensuite, nous installerons le serveur Prometheus. 2. Installer le serveur Prometheus
Prometheus peut prendre en charge diverses méthodes d'installation, notamment Docker, Ansible, Chef, Puppet, Saltstack, etc. Les deux méthodes les plus simples sont présentées ci-dessous. L'une consiste à utiliser directement le fichier exécutable compilé, qui peut être utilisé immédiatement, et l'autre consiste à utiliser une image Docker.
2.1 fonctionne immédiatement
Obtenez d'abord la dernière version et l'adresse de téléchargement de Prometheus sur la page de téléchargement du site officiel. La dernière version est la 2.4.3 (octobre 2018). Exécutez la commande suivante pour télécharger et décompresser :
.$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
Puis changez Allez dans le répertoire décompressé et vérifiez la version de Prometheus :
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
Exécutez le serveur Prometheus :
$ ./prometheus --config.file=prometheus.yml
2.2 Utiliser l'image Docker
Il est plus facile d'installer Prometheus à l'aide de Docker, exécutez simplement la commande suivante :
$ sudo docker run -d -p 9090:9090 prom/prometheus
Généralement , nous spécifierons également l'emplacement du fichier de configuration :
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
Nous plaçons le fichier de configuration à l'emplacement local
~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过-v参数将本地的配置文件挂载到/etc/prometheus/, qui est l'emplacement par défaut du fichier de configuration chargé par prometheus dans le conteneur.如果我们不确定默认的配置文件在哪,可以先执行上面的不带
-v参数的命令,然后通过docker inspect命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
2.3 配置 Prometheus
正如上面两节看到的,Prometheus 有一个配置文件,通过参数
<span style="outline: 0px;color: rgb(0, 0, 0);">--config.file</span>来指定,配置文件格式为 YAML。我们可以打开默认的配置文件<span style="outline: 0px;color: rgb(0, 0, 0);">prometheus.yml</span>看下里面的内容:/etc/prometheus $ cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
Prometheus 默认的配置文件分为四大块:
bloc global : configuration globale de Prometheus, telle que scrape_intervalreprésente comment long Prometheus récupère les données une fois,evaluation_intervalindique la fréquence de détection de la règle d'alarme ;
scrape_interval表示 Prometheus 多久抓取一次数据,evaluation_interval表示多久检测一次告警规则; alerting 块:关于 Alertmanager 的配置,这个我们后面再看; rule_files 块:告警规则,这个我们后面再看; scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为
prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
三、学习 PromQL
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问 http://localhost:9090/
scrape_config block : Prometheus est défini ici. Pour la cible capturée, nous pouvons voir qu'elle a été configurée avec un nom nommé prometheus travail, en effet, Prometheus exposera également ses propres données d'indicateur via l'interface HTTP au démarrage, ce qui équivaut à la surveillance de Prometheus lui-même. Bien que cela soit de peu d'utilité lors de l'utilisation réelle de Prometheus, nous pouvons utilisez cet exemple pour apprendre à utiliser Prometheus ; visitez http://localhost:9090/metrics Découvrez quels indicateurs Prometheus expose ; 🎜
Après avoir installé Prometheus en suivant les étapes ci-dessus, nous pouvons maintenant commencer à découvrir Prometheus. Prometheus fournit une interface utilisateur Web visuelle pour faciliter notre fonctionnement. Accès direct http://localhost:9090 / , il passera à la page Graphique par défaut : 🎜
Vous pouvez vous sentir dépassé lorsque vous visitez cette page pour la première fois. Nous pouvons d'abord examiner le contenu sous d'autres menus. Par exemple : Les alertes affichent toutes les règles d'alarme définies. L'état peut afficher diverses informations sur l'état de Prometheus, y compris les informations sur l'exécution et la construction. , indicateurs de ligne de commande, configuration, règles, cibles, découverte de services, etc.
En fait, la page Graph est la fonction la plus puissante de Prometheus. Ici, nous pouvons utiliser une expression spéciale fournie par Prometheus pour interroger les données de surveillance. Cette expression est appelée PromQL (Prometheus Query Language). Grâce à PromQL, vous pouvez non seulement interroger des données sur la page Graphique, mais également via l'API HTTP fournie par Prometheus. Les données de surveillance interrogées peuvent être affichées sous deux formes : liste et graphique (correspondant aux deux étiquettes Console et Graph dans la figure ci-dessus).
Comme nous l'avons dit ci-dessus, Prometheus lui-même expose également de nombreux indicateurs de surveillance, qui peuvent également être interrogés sur la page Graphique. Développez la liste déroulante à côté du bouton Exécuter, et vous pouvez voir de nombreux noms d'indicateurs. un à volonté, par exemple : promhttp_metric_handler_requests_total, cet indicateur représente /metrics Le nombre de visites sur la page. Prometheus utilise cette page pour capturer ses propres données de surveillance . Les résultats de la requête dans la balise Console sont les suivants : promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:

上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics
paramètre scrape_interval est 15s , c'est-à-dire que Prometheus accède une fois toutes les 15 secondes /metrics page, nous avons donc passé Actualiser la page en 15 secondes et vous verrez que la valeur de l'indicateur augmentera automatiquement. Cela peut être vu plus clairement dans la balise Graph : 🎜🎜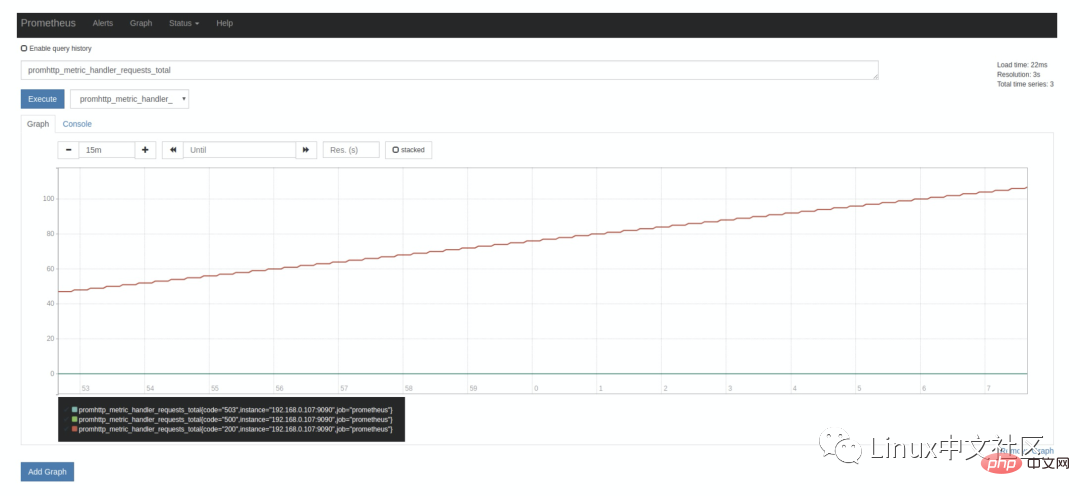
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
Ce modèle de données est similaire au modèle de données d'OpenTSDB Pour des informations détaillées, veuillez vous référer au document du site officiel Modèle de données. De plus, concernant la dénomination des indicateurs et des étiquettes, le site officiel propose quelques suggestions d'orientation, vous pouvez vous référer à la dénomination des métriques et des étiquettes. Bien que les données stockées dans Prométhée soient une valeur float64, si nous la divisons par type, les données de Prométhée peuvent être divisées en quatre catégories principales:
- Counter
- gauge
- histogram
- Le compteur est utilisé pour compter, par exemple : le nombre de demandes, le nombre de tâches terminées et le nombre d'erreurs. Cette valeur augmentera toujours et ne diminuera pas. La jauge est une valeur générale, qui peut être grande ou petite, comme les changements de température et les changements d'utilisation de la mémoire. L'histogramme est un histogramme, ou graphique à barres, souvent utilisé pour suivre l'échelle des événements, tels que le temps de demande et la taille de la réponse.
Ce qui est spécial, c'est qu'il peut regrouper le contenu enregistré et fournir des fonctions de comptage et de somme. Le résumé est très similaire à l'histogramme et est également utilisé pour suivre l'échelle des occurrences d'événements. La différence est qu'il fournit une fonction quantile qui peut diviser les résultats du suivi en pourcentages. Par exemple : une valeur quantile de 0,95 signifie prendre 95 % des données dans la valeur échantillonnée. Pour plus d'informations, veuillez vous référer au document du site officiel Types de métriques. Les concepts de résumé et d'histogramme sont relativement faciles à confondre et sont des types d'indicateurs d'ordre relativement élevé. Vous pouvez vous référer à la description ici des histogrammes et des résumés.
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
3.2 PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
up{instance="192.168.0.107:9090",job="prometheus"} 1 up{instance="192.168.0.108:9090",job="prometheus"} 1 up{instance="192.168.0.107:9100",job="server"} 1 up{instance="192.168.0.108:9104",job="mysql"} 0也可以指定某个 label 来查询:
up{job="prometheus"}这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
up{job!="prometheus"} up{job=~"server|mysql"} up{job=~"192\.168\.0\.107.+"}=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
搜索公众号Java后端栈回复“面试”,送你一份惊喜礼包。
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
3.3 HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
GET /api/v1/query GET /api/v1/query_range GET /api/v1/series GET /api/v1/label/f63ca0dce42272c7c1497a632ea47c1d/values GET /api/v1/targets GET /api/v1/rules GET /api/v1/alerts GET /api/v1/targets/metadata -
GET /api/v1/alertmanagers GET /api/v1/status/config GET /api/v1/status/flags
À partir de Prometheus v2.1, plusieurs nouveaux ont été ajoutés Interface de gestion de TSDB :
POST /api/v1/admin/tsdb/snapshot POST /api/v1/admin/tsdb/delete_series POST /api/v1//tsdb/clean_tombstones
4. Installez Grafana
Bien que l'interface utilisateur Web fournie par Prometheus puisse également fournir une bonne vue des différents indicateurs, cette fonction est très simple et ne convient qu'au débogage. Pour mettre en œuvre un système de suivi puissant, vous avez également besoin d'un panneau personnalisable pour afficher différents indicateurs et prendre en charge différents types de méthodes de présentation (graphiques courbes, camemberts, cartes thermiques, TopN, etc.).
Prometheus a donc développé un système de tableau de bord PromDash, mais ce système a été rapidement abandonné. Les responsables ont commencé à recommander l'utilisation de Grafana pour visualiser les données des indicateurs de Prometheus. Ce n'est pas seulement parce que Grafana est très puissant, mais aussi parce qu'il peut être parfaitement et de manière transparente. intégré à Prometheus.
Grafana est un système open source pour visualiser des données de mesure à grande échelle. Il possède des fonctions très puissantes et une très belle interface. Vous pouvez l'utiliser pour créer un panneau de contrôle personnalisé. Vous pouvez configurer les données à afficher et la méthode d'affichage. dans le panneau. Il prend en charge de nombreuses sources de données différentes, telles que Graphite, InfluxDB, OpenTSDB, Elasticsearch, Prometheus, etc., et il prend également en charge de nombreux plug-ins.
Essayons d'utiliser Grafana pour afficher les données de l'indicateur Prometheus. Nous installons d'abord Grafana, nous utilisons la méthode d'installation Docker la plus simple :
$ docker run -d -p 3000:3000 grafana/grafana
运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
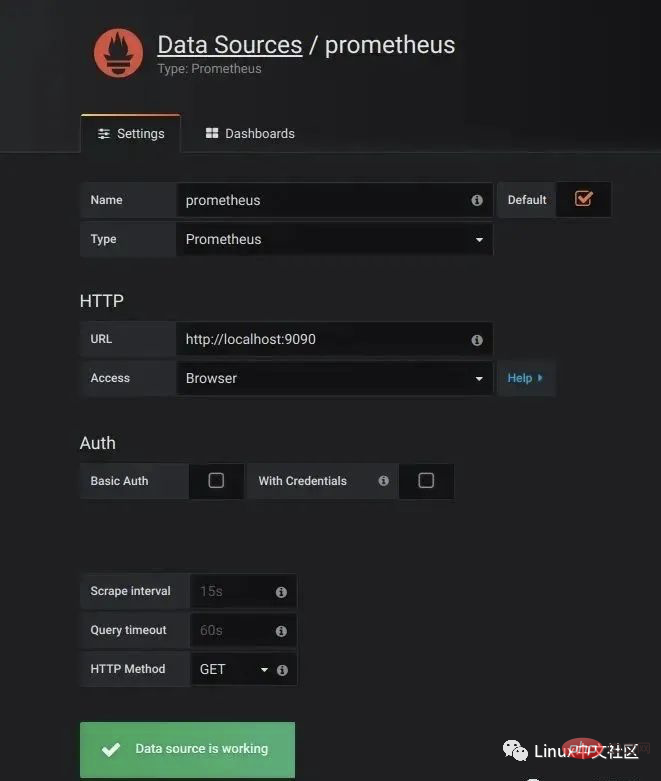
要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
 图片
图片
我们在这里依次填上:
Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
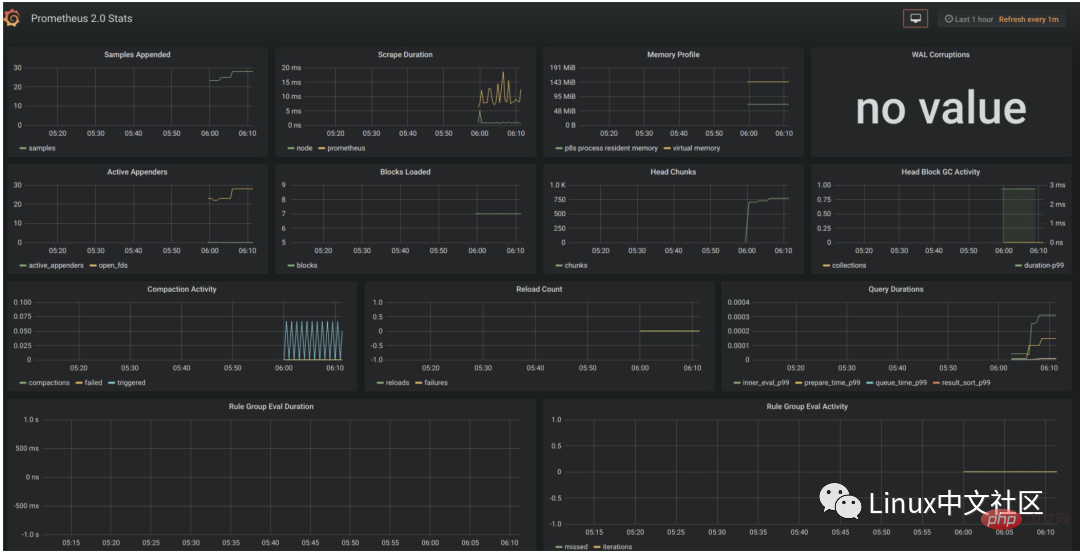
Après avoir configuré la source de données, Grafana vous fournira plusieurs panneaux configurés que vous pourrez utiliser par défaut. Comme le montre la figure ci-dessous, trois panneaux sont fournis par défaut : Prometheus Stats, Prometheus 2.0 Stats et Grafana metrics. Cliquez sur Importer pour importer et utiliser ce panneau.
5. Utilisez Exporter pour collecter des indicateurs
Jusqu'à présent, ce que nous avons vu ne sont que quelques indicateurs qui n'ont aucune utilité pratique. Si nous voulons vraiment utiliser Prometheus dans notre environnement de production, nous en avons souvent besoin. prêter attention à divers indicateurs, tels que la charge du processeur du serveur, l'utilisation de la mémoire, la surcharge d'E/S, le trafic réseau entrant et sortant, etc.
Comme mentionné ci-dessus, Prometheus utilise la méthode Pull pour obtenir les données de l'indicateur. Pour que Prometheus obtienne les données de la cible, vous devez d'abord installer le programme de collecte d'indicateurs sur la cible et exposer l'interface HTTP pour que Prometheus puisse interroger cet indicateur. Le programme de collecte s'appelle un exportateur. Différents indicateurs nécessitent la collecte de différents exportateurs. Actuellement, il existe un grand nombre d'exportateurs disponibles, couvrant presque tous les systèmes et logiciels que nous utilisons couramment.
Le site officiel répertorie une liste des exportateurs couramment utilisés. Chaque exportateur suit une convention de port pour éviter les conflits de ports, c'est-à-dire en commençant par 9 100 et en augmentant dans l'ordre. Il convient également de noter que certains logiciels et systèmes n'ont pas besoin d'installer Exporter car ils assurent eux-mêmes la fonction d'exposer les données des indicateurs au format Prometheus, tels que Kubernetes, Grafana, Etcd, Ceph, etc.
这一节就让我们来收集一些有用的数据。
5.1 收集服务器指标
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
node_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
$ curl http://localhost:9100/metrics
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']
修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
$ killall -HUP prometheus
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:
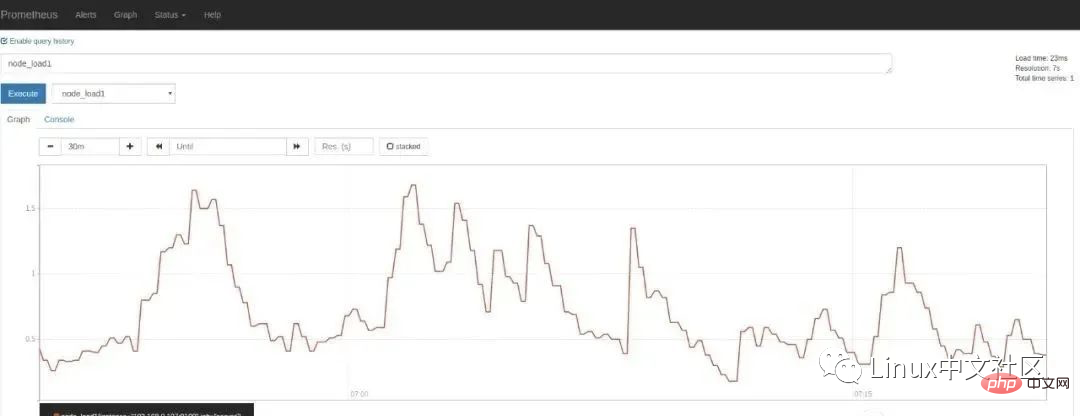
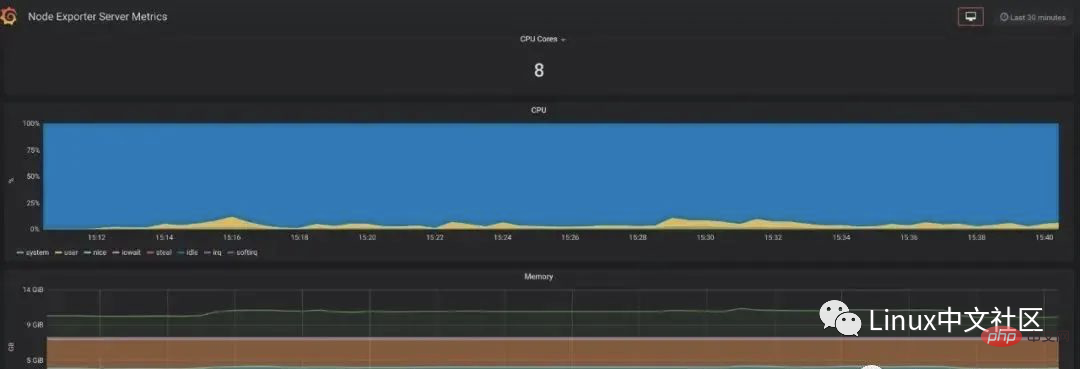
如果想在 Grafana 中查看服务器的指标,可以在 Grafana 的 Dashboards 页面 搜索 node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。
注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
5.2 收集 MySQL 指标
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
mysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量 DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
另一种方式是通过配置文件,默认的配置文件是 ~/.my.cnf,或者通过 --config.my-cnf 参数指定:
$ ./mysqld_exporter --config.my-cnf=".my.cnf"
配置文件的格式如下:
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
注意事项
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
5.3 收集 Nginx 指标
官方提供了两种收集 Nginx 指标的方式。另外,Nginx 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。
第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取 /status/format/json 接口来将 vts 的数据格式转换为 Prometheus 的格式。
Cependant, une nouvelle interface a été ajoutée à la dernière version de nginx-module-vts : /statut/format/prometheus, cette interface peut renvoyer directement le format de Prometheus. De ce point, on peut également voir l'influence de Prometheus. On estime que l'exportateur Nginx VTS sera bientôt retiré (TODO : to. être vérifié). /status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。
除此之外,还有很多其他的方式来收集 Nginx 的指标,比如:nginx_exporter 通过抓取 Nginx 自带的统计页面 /nginx_status 可以获取一些比较简单的指标(需要开启 ngx_http_stub_status_module 模块);nginx_request_exporter 通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter 和 nginx_request_exporter 类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有 vovolie/lua-nginx-prometheus
nginx_exporter En récupérant la page de statistiques fournie avec Nginx <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: " operator mono consolas monaco menlo monospace break-all rgb>/nginx_status Vous pouvez obtenez des indicateurs relativement simples (besoin d'activer ngx_http_stub_status_module module);nginx_request_exporter Collecte et analyse le journal d'accès Nginx via le protocole syslog pour collecter des statistiques liées aux requêtes HTTP. Certains indicateurs;nginx-prometheus-shiny-exporter et nginx_request_exporter Similaire, il utilise également le protocole syslog pour collecter les journaux d'accès, mais il est écrit en langage Crystal . Et vovolie/lua-nginx-prometheus Basé sur Openresty, Prometheus, Consul, Grafana implémente des statistiques de trafic au niveau du nom de domaine et du point de terminaison. Les étudiants qui en ont besoin ou qui sont intéressés peuvent l'installer et l'expérimenter eux-mêmes en se référant à la documentation, mais je ne l'essaierai pas un par un ici. 🎜5.4 收集 JMX 指标
最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
JMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过 -javaagent 参数来加载:
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
其中,9404 是 JMX Exporter 暴露指标的端口,config.yml 是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。
然后检查下指标数据是否正确获取:
$ curl http://localhost:9404/metrics
六、告警和通知
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
6.1 配置告警规则
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:global、alerting、rule_files、scrape_config,其中 rule_files 块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在 rule_files 块中添加一个告警规则文件:
rule_files: - "alert.rules"
然后参考 官方文档,创建一个告警规则文件 alert.rules:
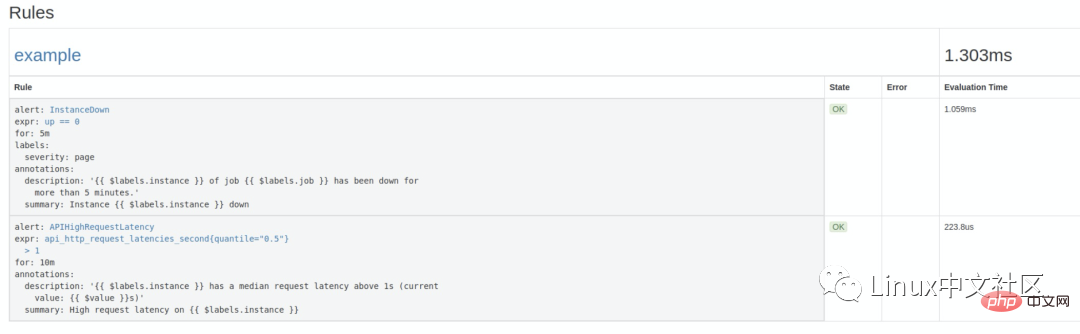
groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {{ $labels.instance }}" description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"这个规则文件里,包含了两条告警规则:InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。
搜索公众号GitHub猿回复“理财”,送你一份惊喜礼包。
配置好后,需要重启下 Prometheus server,然后访问 http://localhost:9090/rules 可以看到刚刚配置的规则:
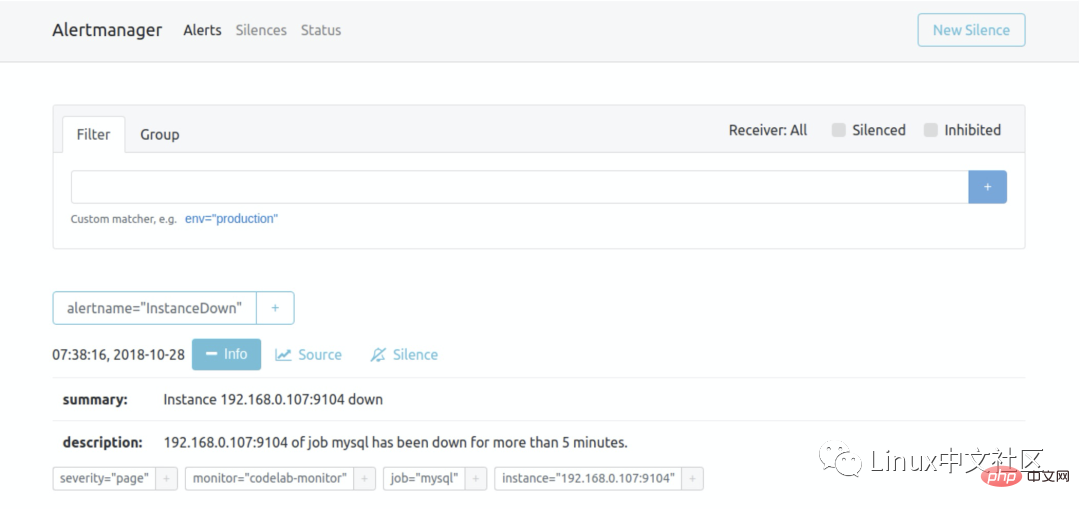
访问 http://localhost:9090/alerts 可以看到根据配置的规则生成的告警:
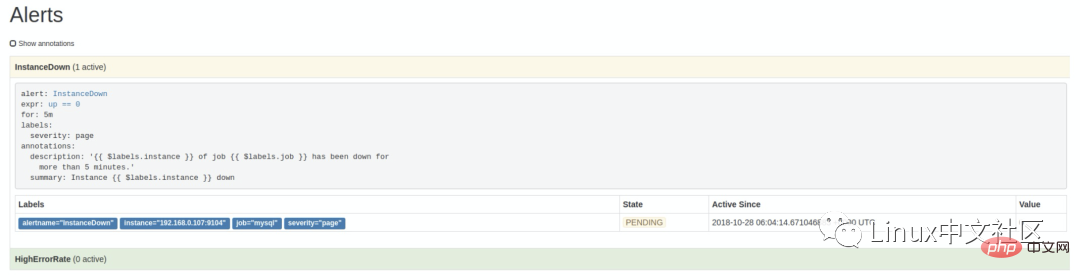
这里我们将一个实例停掉,可以看到有一条 alert 的状态是 PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。
6.2 使用 Alertmanager 发送告警通知
虽然 Prometheus 的 <span style="outline: 0px;color: rgb(0, 0, 0);">/alerts</span> 页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
Alertmanager 启动后默认可以通过 http://localhost:9093/ 来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件 prometheus.yml,添加下面几行:
alerting: alertmanagers: - scheme: http static_configs: - targets: - "192.168.0.107:9093"
这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为 http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件 alertmanager.ym:
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
参考 官方的配置手册 了解各个配置项的功能,其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend
紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
email_config hipchat_config pagerduty_config pushover_config slack_config opsgen ie_config victorops_config wechat_configs webhook_config
pendant réception Il existe de nombreuses façons de les recevoir, mais la plupart d'entre elles sont rarement utilisées en Chine. Le plus couramment utilisé est celui email_config 和 webhook_config,另外 wechat_configs qui peut prendre en charge l'utilisation de WeChat pour alerter, ce qui est également tout à fait conforme aux conditions nationales.
En fait, il est difficile de fournir une méthode globale de notification d'alarme, car il existe différents logiciels de messagerie et chaque pays peut être différent, il est donc impossible de la couvrir entièrement. Par conséquent, Alertmanager a décidé de ne pas en ajouter de nouveaux. récepteurs, mais il est recommandé d'utiliser des webhooks pour intégrer des méthodes de réception personnalisées. Vous pouvez vous référer à ces exemples d'intégration, tels que la connexion de DingTalk à Prometheus AlertManager WebHook.
7. En savoir plus
Jusqu'à présent, nous avons appris la plupart des fonctions de Prometheus. La combinaison de Prometheus + Grafana + Alertmanager peut créer un système de surveillance très complet. Cependant, lors de son utilisation réelle, nous rencontrerons davantage de problèmes.
7.1 Découverte du service
Étant donné que Prometheus obtient activement des données de surveillance via Pull, il est nécessaire de spécifier manuellement la liste des nœuds de surveillance. Lorsque le nombre de nœuds surveillés augmente, le fichier de configuration doit être modifié à chaque fois qu'un nœud est ajouté. ce qui est très gênant. Cela doit être résolu via le mécanisme de découverte de services (SD).
Prometheus prend en charge plusieurs mécanismes de découverte de services et peut obtenir automatiquement les cibles à collecter. Vous pouvez vous référer ici aux mécanismes de découverte de services inclus : azure, consul, dns, ec2, openstack, file, gce, kubernetes, marathon, triton. , zookeeper (nerf, serveret), pour les méthodes de configuration, veuillez vous référer à la page Configuration du manuel. On peut dire que le mécanisme SD est très riche, mais actuellement, en raison de ressources de développement limitées, de nouveaux mécanismes SD ne sont plus développés et seuls les mécanismes SD basés sur des fichiers sont conservés.
Il existe de nombreux didacticiels sur la découverte de services sur Internet. Par exemple, cet article du blog officiel de Prometheus, Advanced Service Discovery in Prometheus 0.14.0, contient une introduction relativement systématique à ce sujet et explique en détail la configuration du réétiquetage et comment. pour utiliser DNS-SRV et Consul et les fichiers pour effectuer la découverte de services.
De plus, le site officiel fournit également un exemple d'introduction à la découverte de services basée sur des fichiers. Le didacticiel d'introduction à l'atelier Prometheus écrit par Julius Volz utilise également DNS-SRV pour la découverte de services. De plus, les questions et réponses des entretiens de la série microservice ont été triées. Recherchez des architectes Internet sur WeChat et envoyez : 2T en arrière-plan, qui peut être lu en ligne.
7.2 Gestion de la configuration des alertes
Peu importe la configuration de Prometheus ou celle d'Alertmanager, il n'y a pas d'API que nous puissions modifier dynamiquement. Un scénario très courant est que nous devons créer un système d'alarme avec des règles personnalisables basées sur Prometheus. Les utilisateurs peuvent créer, modifier ou supprimer des règles d'alarme sur la page en fonction de leurs propres besoins, ou modifier la méthode de notification d'alarme et la personne de contact, comme dans. Question de cet utilisateur dans Prometheus Google Groups : Comment ajouter dynamiquement des règles d'alerte dans le fichier Rules.conf et Prometheus YML via l'API ou quelque chose du genre ?
Malheureusement, Simon Pasquier a déclaré ci-dessous qu'il n'existe actuellement aucune API de ce type et qu'il n'est pas prévu de développer une telle API à l'avenir, car ces fonctions devraient être confiées à des outils tels que Puppet, Chef, Ansible et Salt. . Un tel système de gestion de configuration.
7.3 Utilisation de Pushgateway
Résumé
Ce blog fait référence à un grand nombre de documents chinois sur Prometheus sur Internet, y compris des documents et des blogs, tels que le manuel chinois non officiel de Prometheus du 1046102779, le livre électronique de Song Jiayang "Prometheus in Action" , ici Félicitations à ces auteurs originaux. La page Médias de la documentation officielle de Prometheus fournit également de nombreuses ressources d'apprentissage.
Concernant Prometheus, il y a encore une partie très importante que ce blog n'a pas abordée. Comme mentionné au début du blog, Prometheus est le deuxième projet à rejoindre la CNCF après Kubernetes. L'intégration de Prometheus avec Docker et Kubernetes est très proche. L'utilisation de Prometheus devient de plus en plus courante en tant que système de surveillance pour Docker et Kubernetes.
Pour la surveillance Docker, vous pouvez vous référer à un guide sur le site officiel : Surveillance des métriques des conteneurs Docker à l'aide de cAdvisor, qui explique comment utiliser cAdvisor pour surveiller les conteneurs. Cependant, Docker a désormais également commencé à prendre en charge nativement la surveillance Prometheus ; Site officiel de Docker Document Collectez les métriques Docker avec Prometheus ; Concernant la surveillance de Kubernetes, il existe de nombreuses ressources sur Promehtheus dans la communauté chinoise de Kubernetes. De plus, le livre électronique « Comment surveiller Kubernetes avec une posture élégante » contient également une introduction relativement complète à Kubernetes. surveillance. .
Au cours des deux dernières années, Prometheus s'est développé très rapidement, la communauté est également très active et de plus en plus de personnes en Chine étudient Prometheus. Avec la popularisation de concepts tels que les microservices, DevOps, le cloud computing et le cloud natif, de plus en plus d'entreprises commencent à utiliser Docker et Kubernetes pour créer leurs propres systèmes et applications. Les anciens systèmes de surveillance comme Nagios et Cacti deviendront de plus en plus populaires. Moins il est applicable, je pense que Prometheus finira par devenir un système de surveillance le plus adapté aux environnements cloud.
Annexe : Qu'est-ce qu'une base de données de séries temporelles ?
Comme mentionné ci-dessus, Prometheus est un système de surveillance basé sur une base de données de séries chronologiques. La base de données de séries chronologiques est souvent abrégée en TSDB (Time Series Database). De nombreux systèmes de surveillance populaires utilisent des bases de données de séries chronologiques pour sauvegarder les données, car les caractéristiques des bases de données de séries chronologiques coïncident avec celles des systèmes de surveillance.
Ajouté : des opérations d'écriture fréquentes sont requises, et elles sont écrites par ordre chronologique Supprimé : aucune suppression aléatoire n'est requise dans des circonstances normales, toutes les données d'un bloc horaire seront supprimées directement Modifié : Il n'est pas nécessaire de mettre à jour les données écrites Vérification : Il est nécessaire de prendre en charge les opérations de lecture à haute concurrence. Les opérations de lecture sont par ordre croissant ou décroissant dans le temps. La quantité de données est très importante et le cache ne le fait pas. work
DB-Engines Il existe un classement des bases de données de séries chronologiques, et voici les meilleures (octobre 2018) :
InfluxDB : https://influxdata.com/ Kdb+ : http : //kx.com/ Graphite : http://graphiteapp.org/ RRDtool : http://oss.oetiker.ch/rrdtool/ OpenTSDB : http://opentsdb. net/ Prometheus : https://prometheus.io/ Druid : http://druid.io/
De plus, Liubin a écrit une série d'articles sur les bases de données de séries chronologiques sur son blog : Conférence sur les arts martiaux de la base de données Time Series, recommandée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!