
Maison >Opération et maintenance >exploitation et maintenance Linux >Résumé des points de connaissances sur l'optimisation des performances Linux · Practice + Collection Edition
Résumé des points de connaissances sur l'optimisation des performances Linux · Practice + Collection Edition
- Linux中文社区avant
- 2023-08-03 15:01:50852parcourir

Partie 1Optimisation des performances Linux
1Optimisation des performances
Indicateurs de performance
Concurrence élevée et réponse rapide correspondent aux deux indicateurs clés de l'optimisation des performances : Débit et Latence

Charge de l'applicationAngle : affecte directement l'expérience utilisateur du terminal du produit Ressources systèmeAngle : utilisation des ressources, saturation, etc.
L'essence du problème de performances est que les ressources système ont atteint le goulot d'étranglement, mais le traitement des demandes n'est pas assez rapide pour prendre en charge davantage de demandes. L'analyse des performances consiste en fait à détecter les goulots d'étranglement de l'application ou du système et à essayer de les éviter ou de les atténuer.
Choisissez des métriques pour évaluer les performances des applications et des systèmes Définissez des objectifs de performances pour les applications et les systèmes Effectuez une analyse comparative des performances Analyse des performances pour localiser les goulots d'étranglement -
Surveillance des performances et alertes
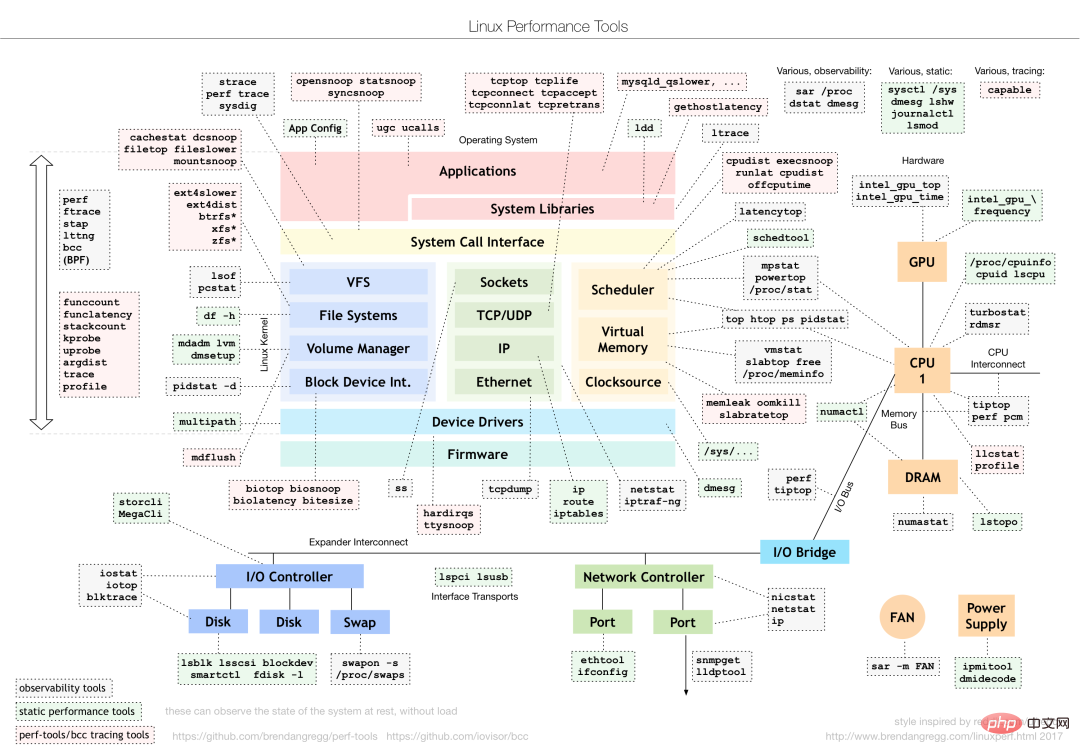
Choisissez différents outils d'analyse des performances pour différents problèmes de performances. Les éléments suivants sont les outils de performances Linux couramment utilisés et les types correspondants de problèmes de performances analysés.
Comment devrions-nous comprendre la "charge moyenne"
Charge moyenne : Le nombre moyen de processus dans les états exécutables et ininterruptibles du système par unité de temps, qui est le nombre moyen de processus actifs. Cela n’est pas directement lié à l’utilisation du processeur telle que nous l’entendons traditionnellement.
Le processus ininterruptible est un processus qui se trouve dans un processus critique dans l'état du noyau (comme une réponse d'E/S commune en attente d'un périphérique). L'état ininterruptible est en fait un mécanisme de protection du système pour les processus et les périphériques matériels.
Quelle est la charge moyenne raisonnable ? Dans l'environnement de production réel, surveillez la charge moyenne du système et jugez la tendance des changements de charge en fonction des données historiques. Lorsqu’il y a une tendance évidente à la hausse de la charge, effectuez une analyse et une enquête en temps opportun. Bien sûr, vous pouvez également définir un seuil (comme lorsque la charge moyenne est supérieure à 70% du nombre de CPU)
Dans le travail réel, on confond souvent les notions de charge moyenne et d'utilisation du CPU. En fait, les deux. ne sont pas complètement équivalents :Processus gourmands en CPU. Une grande utilisation du CPU entraînera une augmentation de la charge moyenne. À l'heure actuelle, les deux sont cohérents.
- Processus gourmands en E/S. Les E/S entraîneront également une augmentation de la charge moyenne. À ce stade, l'utilisation du processeur n'est pas nécessairement élevée. Un grand nombre de processus en attente de planification du processeur entraîneront une augmentation de la charge moyenne. temps, l'utilisation du processeur sera également relativement élevée
- Lorsque la charge moyenne est élevée, cela peut être dû à des processus gourmands en ressources processeur, ou cela peut être dû au fait que /O est occupé. Lors d'une analyse spécifique, vous pouvez combiner l'outil mpstat/pidstat pour vous aider à analyser la source de charge
2 Le contexte de la nouvelle tâche est transféré vers ces registres et le compteur de programme, et enfin il saute à l'emplacement pointé par le compteur de programme pour exécuter la nouvelle tâche. Parmi eux, le contexte enregistré sera stocké dans le noyau du système et chargé à nouveau lorsque la tâche est reprogrammée pour exécution afin de garantir que l'état d'origine de la tâche n'est pas affecté. Suivez la communauté chinoise LinuxSelon le type de tâche, la commutation de contexte CPU est divisée en :
Changement de contexte de processus Changement de contexte de thread Changement de contexte d'interruption
Changement de contexte de processus
Le processus Linux divise l'espace d'exécution du processus en espace noyau et espace utilisateur en fonction du niveau d'autorisations. La transition du mode utilisateur au mode noyau doit être effectuée via des appels système.
Un processus d'appel système effectue en fait deux changements de contexte CPU :
La position de l'instruction du mode utilisateur dans le registre CPU est enregistrée en premier, le registre CPU est mis à jour à la position de l'instruction du mode noyau et passe en mode noyau pour exécuter la tâche du noyau Après l'appel système ; est terminé, le registre du processeur restaure les données d'état utilisateur enregistrées d'origine, puis passe à l'espace utilisateur pour continuer à fonctionner.
Le processus d'appel système n'implique pas de ressources en mode utilisateur de processus telles que la mémoire virtuelle, et ne change pas non plus de processus. Cela diffère du changement de contexte de processus au sens traditionnel du terme. C'est pourquoi l'appel système est souvent appelé commutateur de mode privilégié .
Les processus sont gérés et planifiés par le noyau, et le changement de contexte de processus ne peut se produire qu'en mode noyau. Par conséquent, par rapport aux appels système, avant de sauvegarder l'état du noyau et les registres du processeur du processus en cours, la mémoire virtuelle et la pile du processus doivent d'abord être enregistrées. Après avoir chargé l'état du noyau du nouveau processus, la mémoire virtuelle et la pile utilisateur du processus doivent être actualisées.
Le processus n'a besoin de changer de contexte que lorsqu'il est programmé pour s'exécuter sur le processeur. Il existe les scénarios suivants : les tranches de temps du processeur sont allouées à tour de rôle, des ressources système insuffisantes entraînent le blocage du processus, le processus se bloque activement via la fonction de veille. , et les processus hautement prioritaires préemptent le temps Lorsqu'une interruption matérielle se produit, le processus sur le CPU est suspendu et exécute à la place le service d'interruption dans le noyau.
Changement de contexte de thread
Le changement de contexte de thread est divisé en deux types :
Les threads avant et arrière appartiennent au même processus, et les ressources de mémoire virtuelle restent inchangées pendant le changement. Il vous suffit de changer les données privées, les registres, etc. du thread Les threads avant et arrière appartiennent. à différents processus, ce qui revient à changer de contexte de processus.
Le changement de thread dans le même processus consomme moins de ressources, ce qui est également l'avantage du multi-threading.
Changement de contexte d'interruption
Le changement de contexte d'interruption n'implique pas le mode utilisateur du processus, donc le contexte d'interruption inclut uniquement l'état nécessaire à l'exécution du programme de service d'interruption en mode noyau (registres CPU, pile du noyau, interruption matérielle paramètres, etc).
La priorité du traitement des interruptions est supérieure à celle du processus, donc le changement de contexte d'interruption et le changement de contexte de processus ne se produiront pas en même temps
Changement de contexte CPU (Partie 2)
Vous pouvez vérifier la situation globale de changement de contexte du système via vmstat
vmstat 5 #每隔5s输出一组数据 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0 0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0 0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0 1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0 4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0 0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
cs (changement de contexte) Nombre de changements de contexte par seconde in (interruption ) Nombre d'interruptions par seconde r (en cours d'exécution ou exécutable) La longueur de la file d'attente prête, le nombre de processus en cours d'exécution et en attente du CPU -
b (Bloqué) Le nombre de processus en état de veille ininterrompue
Pour visualiser les détails de chaque processus. Dans ce cas, vous devez utiliser pidstat pour visualiser le changement de contexte de chaque processus
pidstat -w 5 14时51分16秒 UID PID cswch/s nvcswch/s Command 14时51分21秒 0 1 0.80 0.00 systemd 14时51分21秒 0 6 1.40 0.00 ksoftirqd/0 14时51分21秒 0 9 32.67 0.00 rcu_sched 14时51分21秒 0 11 0.40 0.00 watchdog/0 14时51分21秒 0 32 0.20 0.00 khugepaged 14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8 14时51分21秒 0 1332 0.20 0.00 argusagent 14时51分21秒 0 5265 10.02 0.00 AliSecGuard 14时51分21秒 0 7439 7.82 0.00 kworker/0:2 14时51分21秒 0 7906 0.20 0.00 pidstat 14时51分21秒 0 8346 0.20 0.00 sshd 14时51分21秒 0 20654 9.82 0.00 AliYunDun 14时51分21秒 0 25766 0.20 0.00 kworker/u2:1 14时51分21秒 0 28603 1.00 0.00 python3
cswch 每秒自愿上下文切换次数 (进程无法获取所需资源导致的上下文切换) nvcswch 每秒非自愿上下文切换次数 (时间片轮流等系统强制调度)
vmstat 1 1 #首先获取空闲系统的上下文切换次数 sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题 vmstat 1 1 #新终端观察上下文切换情况 此时发现cs数据明显升高,同时观察其他指标: r列: 远超系统CPU个数,说明存在大量CPU竞争 us和sy列:sy列占比80%,说明CPU主要被内核占用 in列: 中断次数明显上升,说明中断处理也是潜在问题
说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高
pidstat -w -u 1 #查看到底哪个进程导致的问题
从结果中看出是sysbench导致CPU使用率过高,但是pidstat输出的上下文次数加起来也并不多。分析sysbench模拟的是线程的切换,因此需要在pidstat后加-t参数查看线程指标。
另外对于中断次数过多,我们可以通过/proc/interrupts文件读取
watch -d cat /proc/interrupts
发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。
L'utilisation du CPU d'une application atteint 100%, que dois-je faire ?
Linux, en tant que système d'exploitation multitâche, divise le temps CPU en courtes tranches de temps et les alloue tour à tour à chaque tâche via le planificateur. Afin de maintenir le temps CPU, Linux déclenche des interruptions temporelles via des fréquences de battement prédéfinies et utilise des jiffies globaux pour enregistrer le nombre de battements depuis le démarrage. L'interruption temporelle se produit une fois cette valeur + 1.
Utilisation du CPU , le pourcentage du temps total du CPU autre que le temps d'inactivité. L'utilisation du processeur peut être calculée à partir des données dans /proc/stat. Parce que la valeur cumulée du nombre de battements depuis le démarrage dans /proc/stat est calculée comme l'utilisation moyenne du processeur depuis le démarrage, ce qui a généralement peu d'importance. Vous pouvez calculer l'utilisation moyenne du processeur pendant cette période en prenant la différence entre deux valeurs prises à intervalles d'une période de temps. L'outil d'analyse des performances donne l'utilisation moyenne du processeur sur une période de temps. Faites attention au réglage de l'intervalle.
L'utilisation du processeur peut être consultée via top ou ps. Vous pouvez analyser les problèmes de processeur du processus via perf, qui est basé sur l'échantillonnage d'événements de performances. Il peut non seulement analyser divers événements de performances du système et du noyau, mais peut également être utilisé pour analyser les problèmes de performances d'applications spécifiées.
perf top / perf record / perf report (-g active l'échantillonnage des relations d'appel)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。
接着用perf来分析具体是php-fpm中哪个函数导致该问题。
perf top -g -p XXXX #对某一个php-fpm进程进行分析
发现其中sqrt和add_function占用CPU过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升
系统的CPU使用率很高,为什么找不到高CPU的应用?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。
此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。
出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。
下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致:
进程不停的崩溃重启(如段错误/配置错误等),此时进程退出后可能又被监控系统重启; 短时进程导致,即其他应用内部通过exec调用的外面命令,这些命令一般只运行很短时间就结束,很难用top这种间隔较长的工具来发现
可以通过pstree来查找 stress的父进程,找出调用关系。
pstree | grep stress
发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。
Ce n'est encore qu'une supposition. La prochaine étape consiste à continuer de l'analyser via l'outil de performance. Le rapport de performances montre que le stress consomme en fait beaucoup de CPU, ce qui peut être résolu en résolvant le problème d'autorisation.
Que dois-je faire s'il y a un grand nombre de processus ininterruptibles et de processus zombies dans le système ?
État du processus
R En cours d'exécution/Runnable, indiquant que le processus est dans la file d'attente prête du processeur, en cours d'exécution ou en attente d'exécution ; D Veille du disque, état de veille ininterrompue, indiquant généralement que le processus est en cours d'exécution. communique avec le matériel Interact et ne peut pas être interrompu par d'autres processus pendant l'interaction Z Zombie, un processus zombie, ce qui signifie que le processus est effectivement terminé, mais que le processus parent n'a pas récupéré ses ressources ; ; S Sleep Interruptible, qui peut être interrompu L'état de veille signifie que le processus est suspendu par le système car il attend un événement. Lorsque l'événement en attente se produit, il sera réveillé et entrera dans l'état R ; I Idle, état inactif, est utilisé sur les threads du noyau qui ne peuvent pas interrompre le sommeil. Cet état n'entraînera pas une augmentation de la charge moyenne ; - T Stop/Traced, indiquant que le processus est suspendu ou tracé (SIGSTOP/SIGCONT, débogage GDB
- X Dead, le processus est mort et va) ; pas être au top /ps vu.
对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。
僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。
磁盘O_DIRECT问题
sudo docker run --privileged --name=app -itd feisky/app:iowait ps aux | grep '/app'
可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。
其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。
用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。
分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。
用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。
dstat 1 10 #间隔1秒输出10组数据
可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。
之前top查看的处于D状态的进程号,用pidstat -d -p XXX 展示进程的I/O统计数据。发现处于D状态的进程都没有任何读写操作。在用pidstat -d 查看所有进程的I/O统计数据,看到app进程在进行磁盘读操作,每秒读取32MB的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。
sudo strace -p XXX #对app进程调用进行跟踪
报错没有权限,因为已经时root权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps命令查找该进程已经处于Z状态,即僵尸进程。
这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用perf record -d和perf report进行分析,查看app进程调用栈。
看到app确实在通过系统调用sys_read()读取数据,并且从new_sync_read和blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。
Après une analyse couche par couche, la cause première est l’E/S directe du disque à l’intérieur de l’application. Localisez ensuite l’emplacement du code spécifique pour l’optimisation.
Processus zombies
Après l'optimisation ci-dessus, iowait a considérablement diminué, mais le nombre de processus zombies continue d'augmenter. Tout d'abord, localisez le processus parent du processus zombie. Utilisez pstree -aps XXX pour imprimer l'arborescence des appels du processus zombie et constatez que le processus parent est le processus d'application.
Vérifiez le code de l'application pour voir si la fin du processus enfant est gérée correctement (si wait()/waitpid() est appelé, si une fonction de traitement du signal SIGCHILD est enregistrée, etc.).
Lorsque vous rencontrez une augmentation de l'iowait, utilisez d'abord des outils tels que dstat et pidstat pour confirmer s'il y a un problème d'E/S de disque, puis découvrez quels processus sont à l'origine de l'E/S si vous ne pouvez pas utiliser strace directement. analyser les appels de processus, vous pouvez utiliser l'outil de performance pour l'analyser.
Pour le problème zombie, utilisez pstree pour trouver le processus parent, puis regardez le code source pour vérifier la logique de traitement pour la fin du processus enfant.
Indicateur de performances du processeur
Utilisation du processeur
Utilisation du processeur par l'utilisateur, y compris le mode utilisateur (utilisateur) et le mode utilisateur faible priorité (nice). Si cet indicateur est trop élevé, il l'indique. que l'application est relativement occupée. Utilisation du processeur système, le pourcentage de temps pendant lequel le processeur fonctionne en mode noyau (hors interruptions). Un indicateur élevé indique que le noyau est relativement occupé. Utilisation du processeur en attente de moi. /O, iowait, l'indicateur A élevé indique que le temps d'interaction d'E/S entre le système et le périphérique matériel est relativement long Utilisation du processeur par interruption logicielle/dure, un indicateur élevé indique qu'un grand nombre d'interruptions se produisent. dans le système. voler le CPU / CPU invité, indiquant le pourcentage de machine virtuelle de CPU occupé. Charge moyenne
Idéalement, la charge moyenne est égale au nombre de CPU logiques, ce qui signifie que chacun Le processeur est pleinement utilisé. S'il est plus important, cela signifie que la charge du système est plus lourde.
Changement de contexte de processus
.Y compris la commutation volontaire lorsque les ressources ne peuvent pas être obtenues et la commutation involontaire lorsque le système force la planification. La commutation de contexte elle-même est une fonction essentielle pour garantir le fonctionnement normal de Linux. Une commutation excessive consommera le temps CPU du processus en cours d'exécution d'origine dans le registre et le noyau. En termes de sauvegarde et de restauration de données telles que la mémoire virtuelle,
Taux de réussite du cache CPU
Réutilisation du cache CPU, plus le taux de réussite est élevé, meilleures sont les performances. Parmi eux, L1/L2 est couramment utilisé en simple. core, et L3 est utilisé en multi-core
"Outils de performance" chacun CPU et utilisation du CPU de chaque processus. Découvrez le processus provoquant une charge moyenne plus élevée. De plus, recherchez le compte public Linux et répondez « git books » en arrière-plan pour obtenir un package cadeau surprise.
Utilisez d'abord vmstat pour vérifier le changement de contexte du système et les temps d'interruption Ensuite, utilisez pidstat pour observer le changement de contexte volontaire et involontaire du processus Enfin, utilisez pidstat pour observer le fil Situation de changement de contexte
Utilisez d'abord top pour vérifier l'utilisation du processeur du système et du processus, localisez le processus Ensuite, utilisez perf top pour observer la chaîne d'appel du processus et localisez le processus spécifique Fonction
Utilisez d'abord top pour vérifier l'utilisation du processeur du système et du processus. Ni top/pidstat ne peut trouver le processus avec. utilisation élevée du processeur -
Réexaminez la sortie supérieure Commencez avec des processus qui ont une faible utilisation du processeur mais qui sont à l'état d'exécution -
enregistrement/rapport de performances trouvé des causes de processus à court terme (outil execsnoop)
Utilisez d'abord top pour observer l'augmentation de iowait et constatez qu'un grand nombre de processus ininterruptibles et zombies strace ne peut pas suivre les appels système de processus perf a analysé la chaîne d'appels et a découvert que la cause première provenait des E/S directes du disque
top a observé que l'utilisation du processeur par interruption logicielle du système était élevée View / proc/softirqs et a constaté que le taux de changement était rapide Plusieurs interruptions logicielles La commande sar s'est avérée être un problème de paquet réseau tcpdump pour connaître le type et la source des trames réseau et déterminer la cause de SYN Attaque FLOOD
Trouvez l'outil approprié en fonction de différents indicateurs de performance :
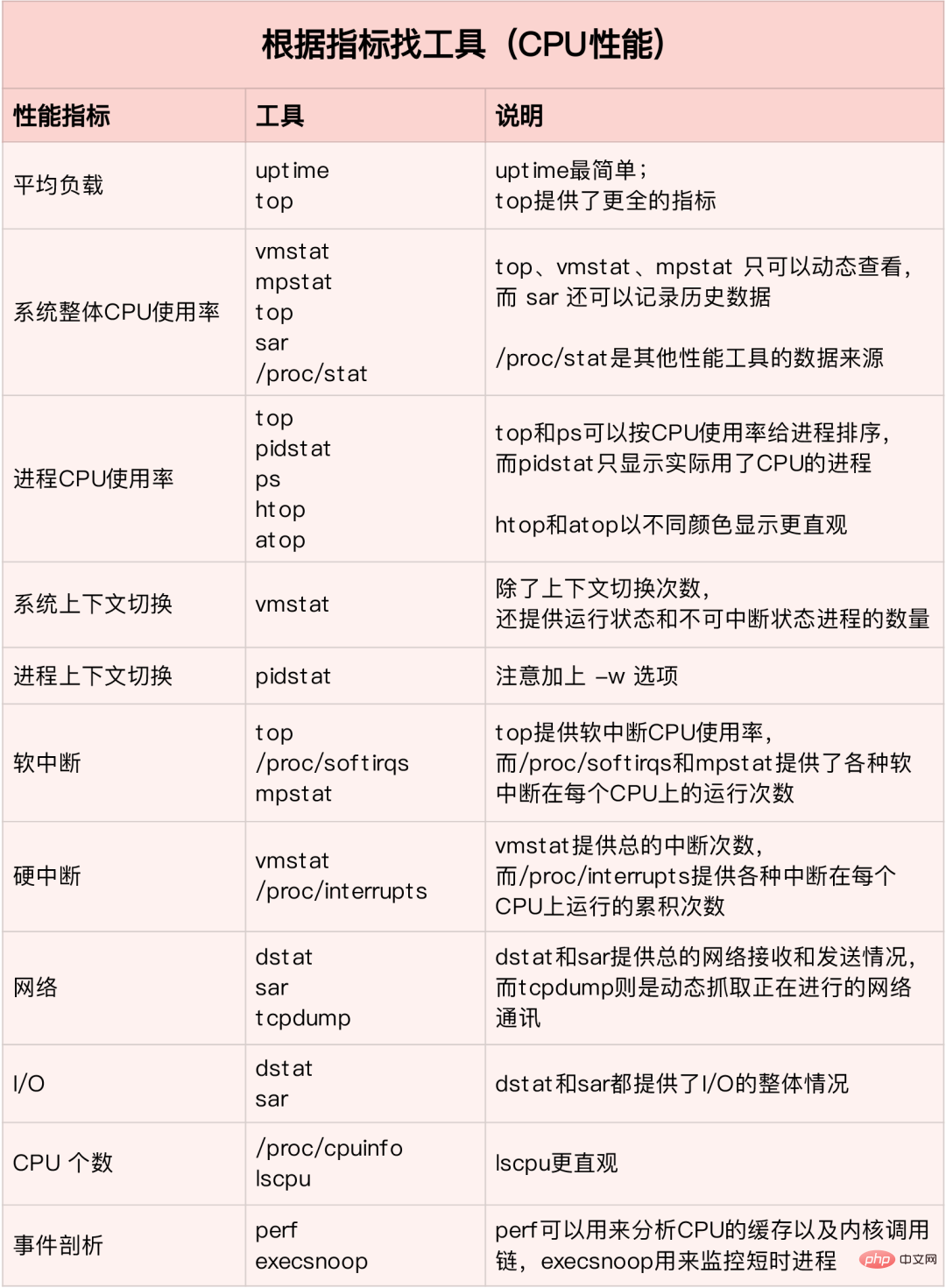
Dans un environnement de production, les développeurs n'ont souvent pas l'autorisation d'installer de nouveaux packages d'outils et peuvent maximiser uniquement l'utilisation des outils déjà installés dans le système. Par conséquent, il est nécessaire de comprendre certains courants. Quelle analyse d'indicateur l'outil peut-il fournir ?
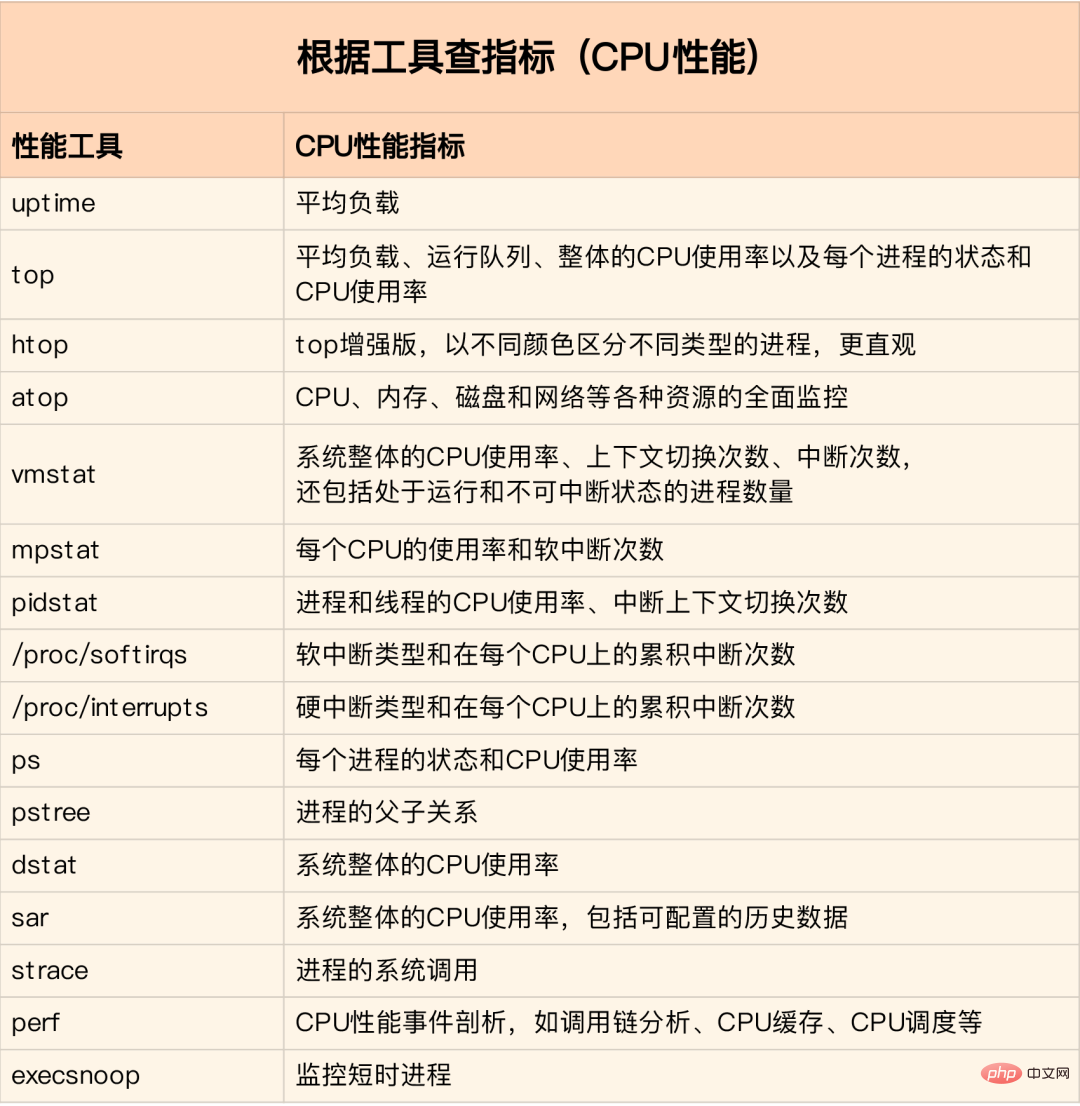
Exécutez d'abord quelques outils qui prennent en charge plus d'indicateurs, tels que top/vmstat/pidstat En fonction de leur sortie, vous pouvez déterminer de quel type de problème de performances il s'agit. process Utilisez ensuite strace/perf pour analyser la situation d'appel pour une analyse plus approfondie. Si elle est causée par une interruption logicielle, utilisez /proc/softirqs
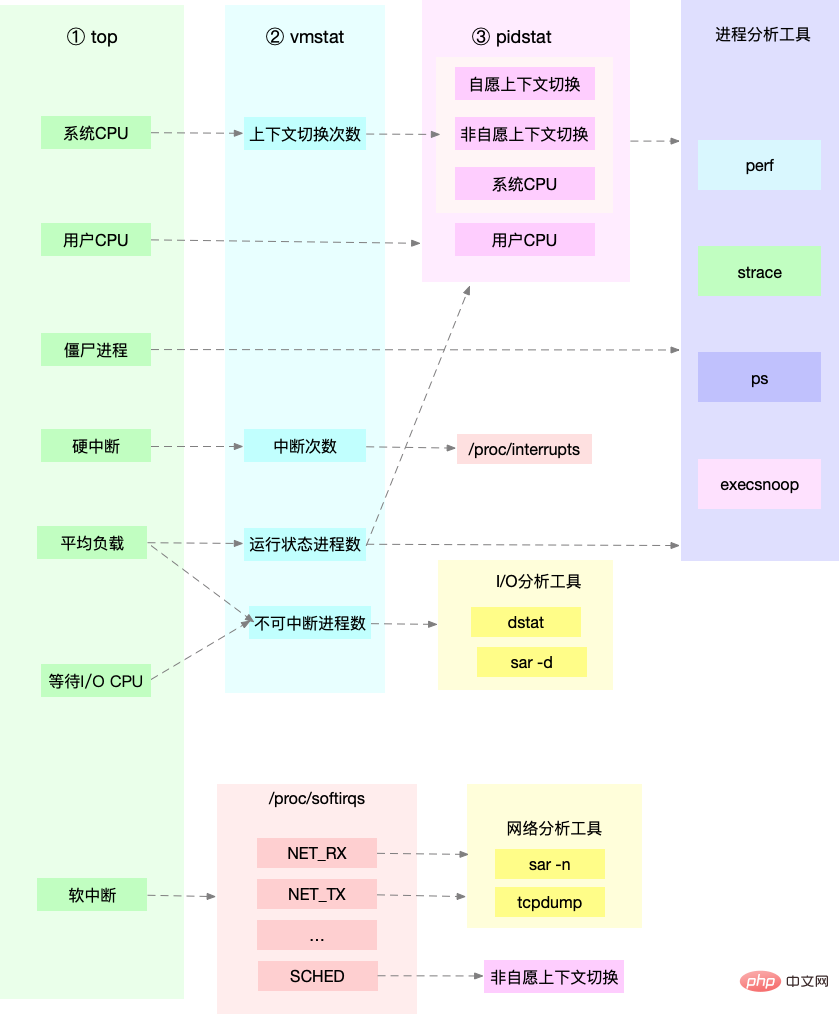
Optimisation du processeur
.application Optimiser
Optimisation du compilateur : activez les options d'optimisation pendant la phase de compilation, telles que gcc -O2 Optimisation de l'algorithme Traitement asynchrone : évitez que le programme ne soit bloqué en attendant une ressource, améliorant ainsi le traitement simultané du programme (Remplacez l'interrogation par une notification d'événement) Multi-threading au lieu de multi-processus : réduisez les coûts de changement de contexte Faites bon usage du cache : accélérez le traitement du programme Optimisation du système.
Liaison CPU : liez le processus à 1/plusieurs processeurs pour améliorer le taux de réussite du cache du processeur et réduire le changement de contexte causé par la planification du processeur Exclusivité CPU : mécanisme d'affinité CPU pour allouer les processus . Ajustement du niveau de priorité : utilisez nice pour réduire de manière appropriée la priorité des applications non essentielles Définir l'affichage des ressources pour les processus : les groupes de contrôle définissent des limites d'utilisation pour éviter que les ressources système ne soient épuisées par les propres problèmes d'une certaine application Optimisation NUMA : Accès au processeur autant que possible Mémoire locale Équilibrage de charge d'interruption : irpbalance, équilibre automatiquement la charge du processus de traitement d'interruption sur chaque processeur La différence et la compréhension du TPS, du QPS et du débit du système
QPS (TPS)
Nombre de concurrences
Temps de réponse
QPS(TPS)=Nombre de concurrences/Temps de réponse moyen
Serveur de requêtes utilisateur
Traitement interne du serveur
-
Le serveur renvoie au client
Le QPS est similaire au TPS, mais une visite sur une page forme un TPS, mais une demande de page peut inclure plusieurs requêtes au serveur, qui peuvent être comptées comme plusieurs QPS
QPS (Queries Per Second) Taux de requêtes par seconde, le nombre de requêtes auxquelles un serveur peut répondre par seconde
TPS (Transactions Per Second) Nombre de transactions par seconde, le résultat des tests logiciels.
- Débit du système, comprenant plusieurs paramètres importants :
3Mémoire
Comment fonctionne la mémoire Linux
Mappage de la mémoire
La mémoire principale utilisée par la plupart des ordinateurs est dynamique mémoire vive (DRAM), uniquement le noyau peut accéder directement à la mémoire physique. Le noyau Linux fournit un espace d'adressage virtuel indépendant pour chaque processus, et cet espace d'adressage est continu. De cette manière, le processus peut facilement accéder à la mémoire (mémoire virtuelle).
L'intérieur de l'espace d'adressage virtuel est divisé en deux parties : l'espace noyau et l'espace utilisateur. La plage de l'espace d'adressage des processeurs avec différentes longueurs de mots est différente. L'espace du noyau système 32 bits occupe 1G et l'espace utilisateur occupe 3G. L'espace noyau et l'espace utilisateur des systèmes 64 bits sont tous deux de 128T, occupant respectivement les parties les plus hautes et les plus basses de l'espace mémoire, et la partie médiane n'est pas définie.
Toute la mémoire virtuelle ne se verra pas attribuer de mémoire physique, seule celle réellement utilisée. La mémoire physique allouée est gérée via le mappage de mémoire. Afin de compléter le mappage de la mémoire, le noyau maintient une table de pages pour chaque processus afin d'enregistrer la relation de mappage entre les adresses virtuelles et les adresses physiques. La table des pages est en fait stockée dans l'unité de gestion de mémoire du processeur MMU, et le processeur peut directement connaître la mémoire accessible via le matériel.
Lorsque l'adresse virtuelle à laquelle le processus accède est introuvable dans la table des pages, le système génère une exception de défaut de page, entre dans l'espace du noyau pour allouer de la mémoire physique, met à jour la table des pages du processus, puis retourne dans l'espace utilisateur pour reprendre. le fonctionnement du procédé.
MMU gère la mémoire en unités de pages, avec une taille de page de 4 Ko. Afin de résoudre le problème du trop grand nombre d'entrées dans la table de pages, Linux fournit les mécanismes de Table de pages multi-niveaux et HugePage.
Répartition de l'espace mémoire virtuelle
La mémoire de l'espace utilisateur est divisée en cinq segments de mémoire différents de bas en haut :
Segment en lecture seule Code et constantes, etc. Segment de données Variables globales, etc. Mappage de fichiers - Les mises à jour des bibliothèques, de la mémoire partagée, etc., commencent à partir d'adresses élevées et augmentent vers le bas
- Y compris les variables locales et le contexte d'appel de fonction, etc. La taille de la pile est fixe. Généralement, 8 Mo
allocation
brk() Pour les petits blocs de mémoire ( **mmap()** Pour les gros blocs de mémoire (>128 Ko), allouez directement à l'aide du mappage de mémoire, c'est-à-dire trouvez une allocation de mémoire libre dans le segment de mappage de fichiers.
Le cache du premier peut réduire l’apparition d’exceptions de pages manquantes et améliorer l’efficacité de l’accès à la mémoire. Cependant, étant donné que la mémoire n'est pas restituée au système, des allocations/libérations de mémoire fréquentes entraîneront une fragmentation de la mémoire lorsque la mémoire est occupée.
Ce dernier est directement renvoyé au système une fois publié, donc une exception de défaut de page se produira à chaque fois que mmap se produira. Lorsque le travail de mémoire est occupé, des allocations de mémoire fréquentes entraîneront un grand nombre d'exceptions de faute de page, augmentant ainsi la charge de gestion du noyau.
Les deux appels ci-dessus n'allouent pas réellement de mémoire. Cette mémoire n'entre dans le noyau que via une exception de défaut de page lors du premier accès, et est allouée par le noyau
Recyclage
Lorsque la mémoire est limitée. , le système le récupère des manières suivantes Mémoire :
回收缓存:LRU算法回收最近最少使用的内存页面;
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
如何查看内存使用情况
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
VIRT La taille de la mémoire virtuelle du processus RES La taille de la mémoire résidente, c'est-à-dire la taille de la mémoire physique réellement utilisée par le processus, hors swap et mémoire partagée SHR La taille de la mémoire partagée, la mémoire partagée avec d'autres processus, les bibliothèques de liens dynamiques chargées et les segments de code de programme %MEM Le pourcentage de mémoire physique utilisée par le processus par rapport à la mémoire totale du système
Comment comprendre le Buffer et le Cache en mémoire ?
buffer est un cache de données de disque, le cache est un cache de données de fichiers, ils seront utilisés à la fois dans les requêtes de lecture et dans les requêtes d'écriture
Comment utiliser le cache système pour optimiser l'efficacité opérationnelle du programme
Taux de réussite du cache
Le taux de réussite du cache fait référence au nombre de requêtes pour obtenir des données directement via le cache, en tenant compte du pourcentage de toutes les demandes. Plus le taux de réussite est élevé, plus les avantages apportés par le cache sont importants et meilleures sont les performances de l'application.
Après avoir installé le package bcc, vous pouvez surveiller les accès en lecture et en écriture du cache via cachestat et cachetop.
Après avoir installé pcstat, vous pouvez vérifier la taille du cache et le taux de cache des fichiers en mémoire
#首先安装Go export GOPATH=~/go export PATH=~/go/bin:$PATH go get golang.org/x/sys/unix go ge github.com/tobert/pcstat/pcstat
dd缓存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件 echo 3 > /proc/sys/vm/drop_caches #清理缓存 pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0 cachetop 5 dd if=file of=/dev/null bs=1M #测试文件读取速度 #此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。 dd if=file of=/dev/null bs=1M #重复上述读文件测试 #此时文件读取性能为4+GB/s,读缓存命中率为100% pcstat file #查看文件file的缓存情况,100%全部缓存
O_DIRECT选项绕过系统缓存
cachetop 5 sudo docker run --privileged --name=app -itd feisky/app:io-direct sudo docker logs app #确认案例启动成功 #实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app) #strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
内存泄漏,如何定位和处理?
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
La mémoire allouée n'a pas été correctement récupérée, ce qui a entraîné des fuites Adresses accessibles en dehors des limites de la mémoire allouée, provoquant la sortie anormale du programme
Allocation et recyclage de la mémoire
Distribution de la mémoire virtuelle depuis low De haut en bas, il y a cinq parties : segment en lecture seule, segment de données, tas, segment de mappage mémoire et pile. Parmi eux, ceux qui peuvent provoquer des fuites de mémoire sont :
- Heap : alloués et gérés par l'application elle-même, ces tas de mémoire ne seront pas automatiquement libérés par le système à moins que le programme ne se termine.
- Segment de mappage de mémoire : y compris les bibliothèques de liens dynamiques et la mémoire partagée, où la mémoire partagée est automatiquement allouée et gérée par le programme
Les fuites de mémoire s'accumulent et peuvent même épuiser la mémoire du système. 预先安装systat,docker,bcc 可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求 从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可. 系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括: Pour la mémoire tas automatiquement allouée par le programme, qui est notre page anonyme dans la gestion de la mémoire, bien que cette mémoire ne puisse pas être libérée directement, Linux fournit le mécanisme d'échange pour La mémoire qui n'est pas fréquemment consultée est écrite sur le disque pour libérer la mémoire, et la mémoire peut être lue à partir du disque lors d'un nouvel accès . L'essence du Swap est d'utiliser un morceau d'espace disque ou un fichier local comme mémoire, y compris deux processus d'échange et d'échange : Comment Linux mesure-t-il les ressources mémoire limitées ? Récupération directe de la mémoire Nouvelle allocation de mémoire de gros blocs demandée, mais mémoire restante insuffisante. À ce moment-là, le système récupérera une partie de la mémoire kswapd0 Le thread du noyau récupère régulièrement de la mémoire ; Afin de mesurer l'utilisation de la mémoire, trois seuils de pages_min, pages_low et pages_high sont définis et des opérations de recyclage de mémoire sont effectuées en fonction de ceux-ci. Mémoire restante 3173b2e529e12f7ef4c451a5a47ae995 pages_high,说明剩余内存较多,无内存压力 pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2 很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。 在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析 内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。 当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。 在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。 注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。 说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型. Tampon : stockage temporaire des blocs de disque d'origine, cache les données à écrire sur le disque Exception de page manquante Trouvez le bon outil en fonction de différents indicateurs de performances : Indicateurs de performances inclus dans l'outil d'analyse de la mémoire : Habituellement Exécutez d'abord plusieurs outils de performances avec une couverture relativement large, tels que free, top, vmstat, pidstat, etc. Idées d'optimisation courantes : vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。 pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。 Utilisation : 1.如何检测内存泄漏
sudo docker run --name=app -itd feisky/app:mem-leak
sudo docker logs app
vmstat 3
/usr/share/bcc/tools/memleak -a -p $(pidof app)
为什么系统的Swap变高
Principe du Swap
NUMA 与 SWAP
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
swappiness
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap
#先创建并开启swap
fallocate -l 8G /mnt/swapfile
chmod 600 /mnt/swapfile
mkswap /mnt/swapfile
swapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取
sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap
#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区
#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令
cachetop5 #观察缓存
#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高
watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化
#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
Mémoire disponible : y compris la mémoire restante et la mémoire récupérable
Cache : cache des pages des fichiers lus sur le disque, partie récupérable dans l'allocateur de dalle
Outil de performances de la mémoire
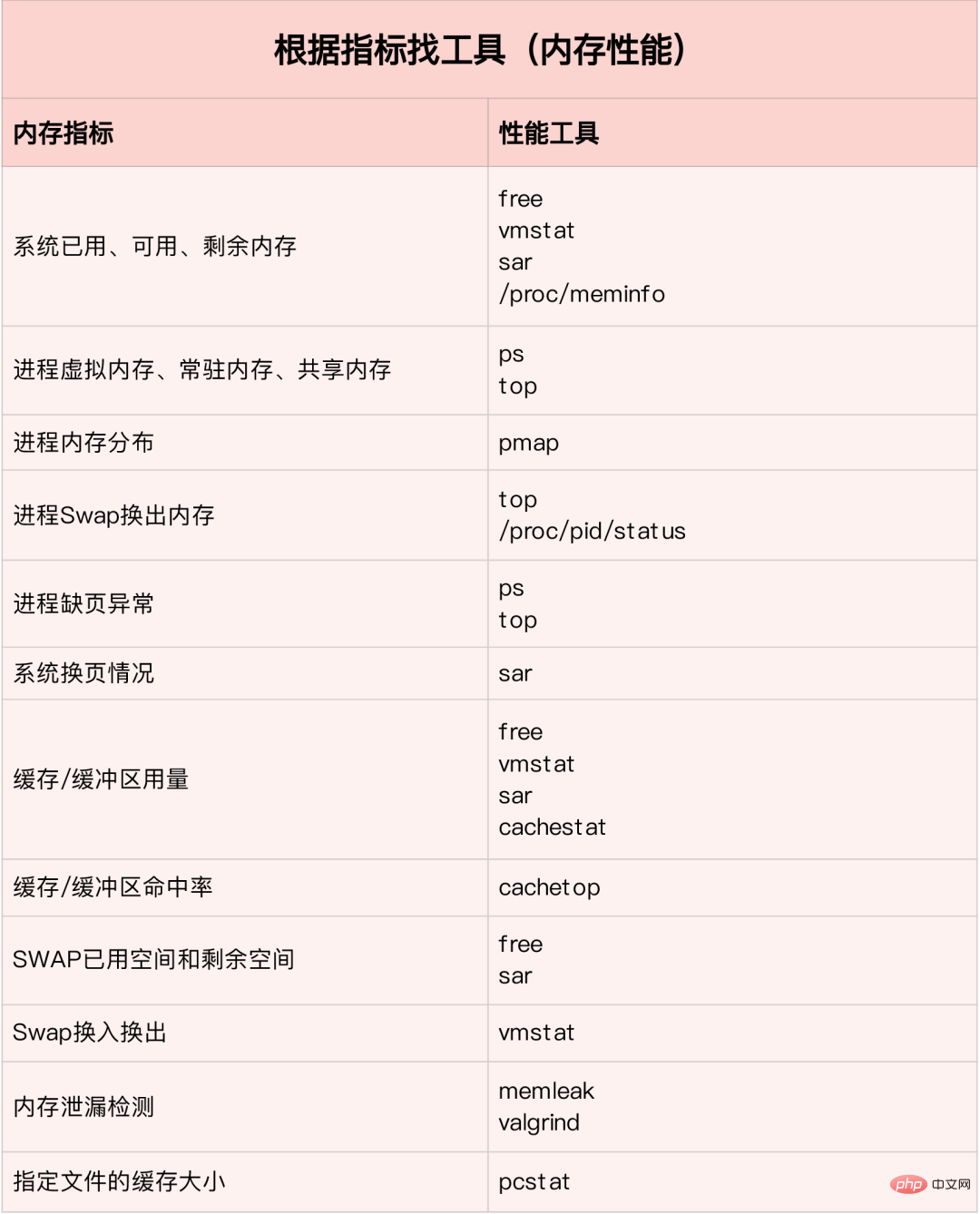
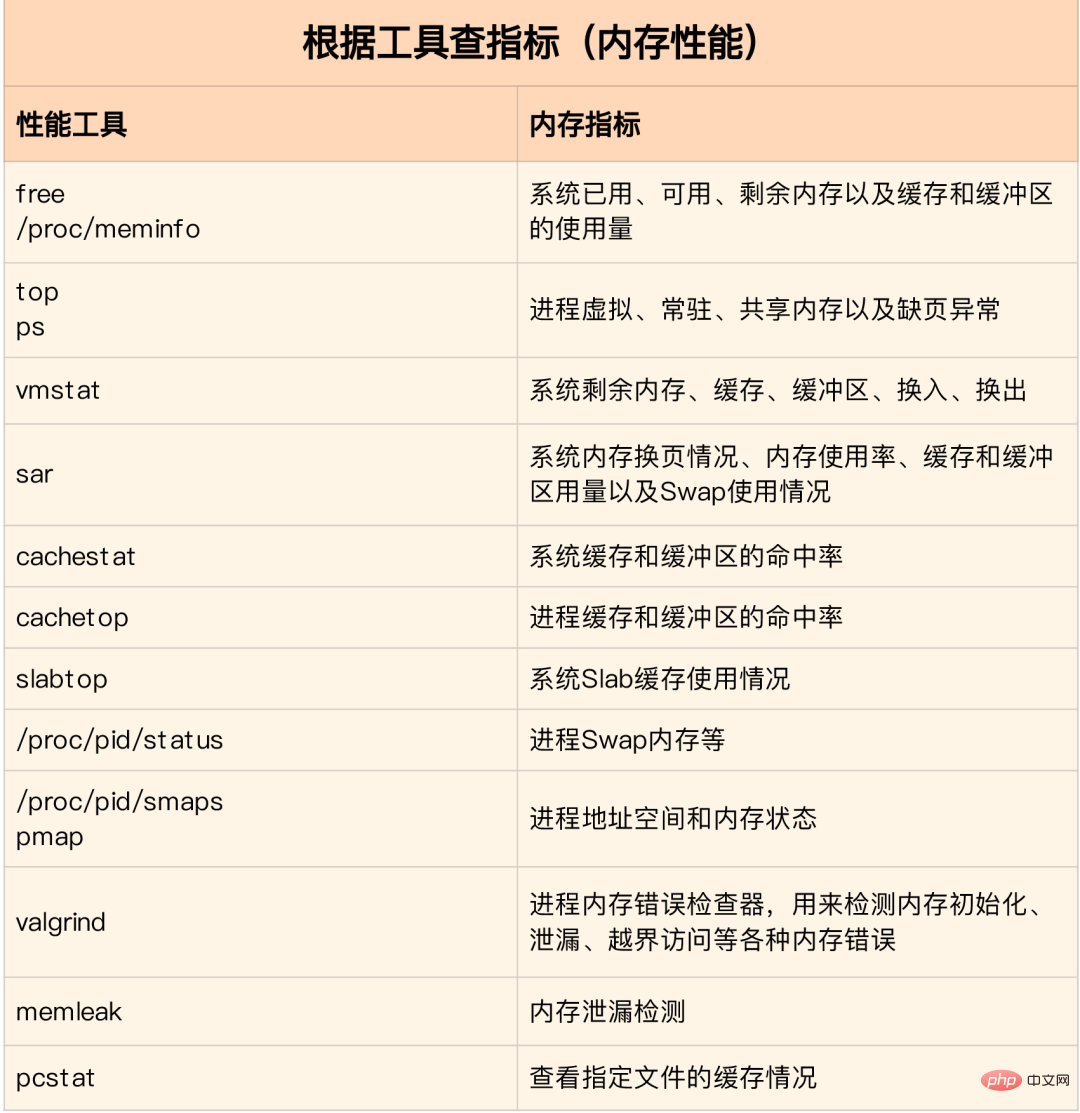
Comment analyser rapidement les goulots d'étranglement des performances de la mémoire
vmstat使用详解
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0
0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0
0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0
0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0
0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0
0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0
1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0
1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0
1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0
1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0
0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0
0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0
1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0
0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0
0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0
1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间
pidstat 使用详解
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8
03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun
03:02:03 PM 997 7326 0.00 1904.95 918.81 java
03:02:03 PM 997 8539 0.00 3.96 0.00 java
03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8
03:02:04 PM 997 7326 0.00 11156.00 1888.00 java
03:02:04 PM 997 8539 0.00 4.00 0.00 java
UID PID kB_rd/s: 每秒进程从磁盘读取的数据量 KB 单位 read from disk each second KB kB_wr/s: 每秒进程向磁盘写的数据量 KB 单位 write to disk each second KB kB_ccwr/s: 每秒进程向磁盘写入,但是被取消的数据量,This may occur when the task truncates some dirty pagecache. iodelay: Block I/O delay, measured in clock ticks Command: 进程名 task name
2、统计CPU使用情况
# 统计CPU pidstat -u 1 10 03:03:33 PM UID PID %usr %system %guest %CPU CPU Command 03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible 03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat 03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
UID PID %usr: 进程在用户空间占用 cpu 的百分比 %system: 进程在内核空间占用 CPU 百分比 %guest: 进程在虚拟机占用 CPU 百分比 %wait: 进程等待运行的百分比 %CPU: 进程占用 CPU 百分比 CPU: 处理进程的 CPU 编号 Command: 进程名
3、统计内存使用情况
# 统计内存 pidstat -r 1 10 Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command Average: 0 1 0.20 0.00 191256 3064 0.01 systemd Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun Average: 0 6642 0.10 0.00 6301904 107680 0.33 java Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java Average: 0 23936 0.10 0.00 5302416 110804 0.34 java Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
UID PID Minflt/s : 每秒次缺页错误次数 (minor page faults),虚拟内存地址映射成物理内存地址产生的 page fault 次数 Majflt/s : 每秒主缺页错误次数 (major page faults), 虚拟内存地址映射成物理内存地址时,相应 page 在 swap 中 VSZ virtual memory usage : 该进程使用的虚拟内存 KB 单位 RSS : 该进程使用的物理内存 KB 单位 %MEM : 内存使用率 Command : 该进程的命令 task name
4、查看具体进程使用情况
pidstat -T ALL -r -p 20955 1 10 03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command 03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java 03:12:16 PM UID PID minflt-nr majflt-nr Command 03:12:17 PM 995 20955 0 0 java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!