
Maison >Problème commun >Après avoir rejoint l'entreprise, j'ai compris ce qu'est Cache
Après avoir rejoint l'entreprise, j'ai compris ce qu'est Cache
- 嵌入式Linux充电站avant
- 2023-07-31 16:03:382129parcourir
Avant-propos
À ce moment-là, le leader m'a confié une tâche de surveillance des performances du matériel perf. Dans le processus d'utilisation de perf, j'ai entré la liste des commandes perf et. J'ai vu les informations suivantes :
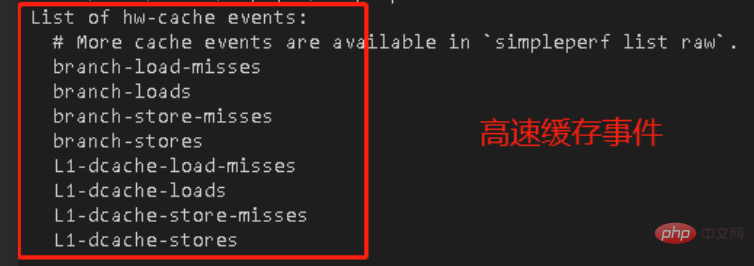
Ma tâche est de faire en sorte que ces événements de cache comptent normalement, mais la clé est que je ne sais pas du tout ce que ces misses、loads signifient.
Je sais seulement que ce sont deux caches, mais ces noms sont très similaires, quelle est la différence ?
Pour cette raison, j'ai senti qu'il était nécessaire pour moi d'en apprendre davantage sur le cache, et ma compréhension du cache, des performances, etc. est partie de là.
Voici quelques connaissances conceptuelles de base que j'ai résumées lorsque j'étudiais le cache. Je pense que cela sera utile aux personnes qui ne comprennent pas la couche ou le cache sous-jacent.
En gros, je guiderai tout le monde sous forme de questions et réponses, car je l'ai déjà parcouru avec beaucoup de questions.
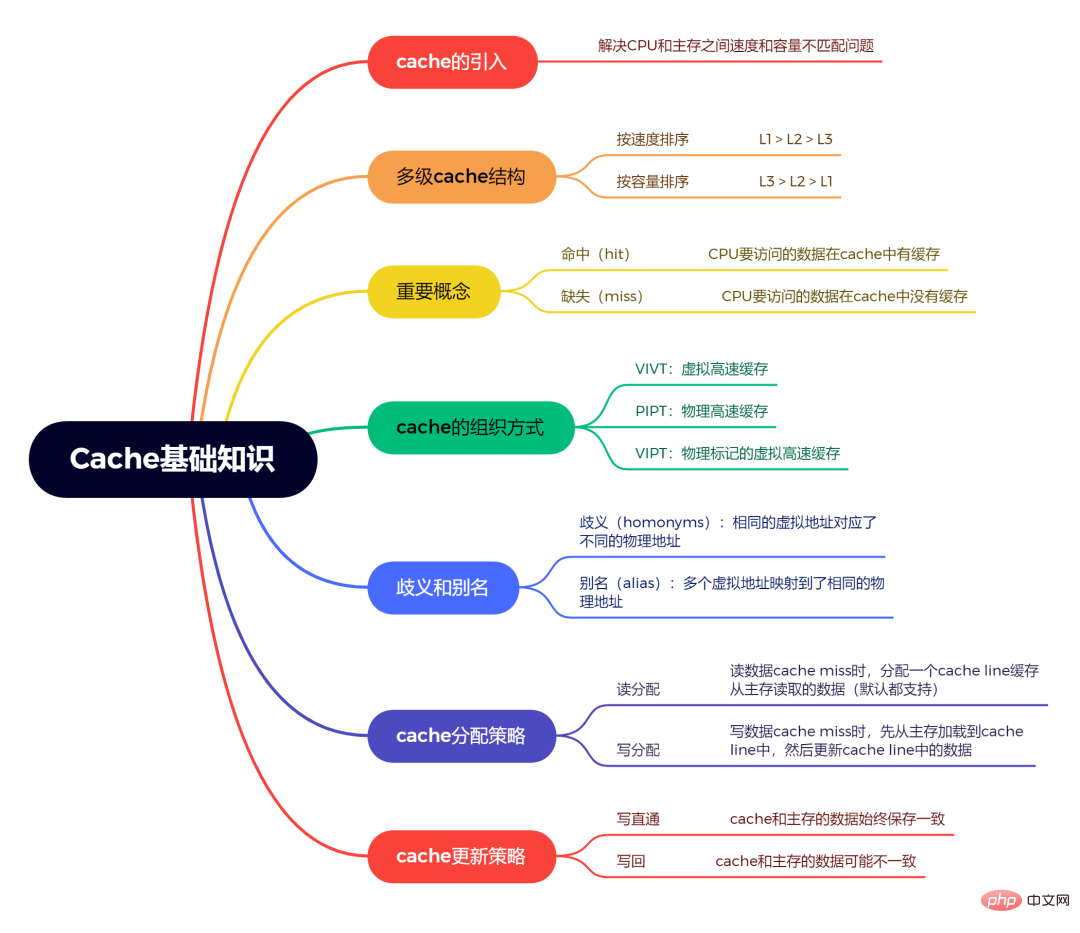
1. Qu'est-ce que le Cache ?
Tout d'abord, il faut savoir que le CPU n'accède pas directement à la mémoire, mais doit d'abord passer par le Cache. Pourquoi ?
Cause : Les données du processeur sont stockées dans des registres. La vitesse d'accès aux registres est très rapide, mais la capacité des registres est petite. La capacité mémoire est grande, mais la vitesse est lente. Afin de résoudre le problème de vitesse et de capacité entre le CPU et la mémoire, le cache est introduit.
Le cache est situé entre le processeur et la mémoire principale. Lorsque le processeur accède à la mémoire principale, il accède d'abord au cache pour voir s'il y a de telles données dans le cache. Si tel est le cas, il récupère les données du cache et. le renvoie au CPU s'il n'y a pas de données dans le Cache, puis accède à la mémoire principale.
2. Structure de stockage du Cache multi-niveaux
De manière générale, il n'y a pas qu'un seul Cache, mais plusieurs, c'est-à-dire un Cache multi-niveaux Pourquoi ?
Raison : Le cache d’accès au CPU est également très rapide. Mais nous ne pouvons pas atteindre une compatibilité complète entre vitesse et capacité. Si la vitesse du CPU accédant au cache est similaire à la vitesse du CPU accédant au registre, cela signifie que le cache est très rapide, mais la capacité est très petite. une petite capacité de cache n'est pas suffisante pour satisfaire nos besoins, c'est pourquoi un cache multi-niveaux a été introduit.
Le cache multi-niveaux divise le cache en plusieurs niveaux L1, L2, L3, etc.
Par ordre de vitesse, l'ordre est L1>L2>L3.
Selon la capacité de stockage, la commande est L3>L2>L1.
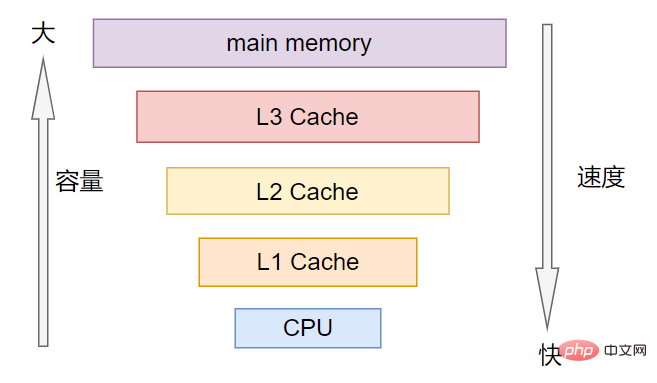
L1 est le plus proche du CPU et L3 est le plus proche de la mémoire principale.
Habituellement, L1 est divisé en cache d'instructions (ICache) et cache de données (<code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);famille de polices : " operator mono consolas monaco menlo monospace de mot break-all rgb>DCache ), et le cache L1 est privé pour le processeur, et chaque processeur dispose d'un cache L1. ICache)和data cache(DCache),并且L1 cache是cpu私有的,每个cpu都有一个L1 cache。
3、“命中”和“缺失”是什么意思?
命中:CPU要访问的数据在cache中有缓存,称为“命中”,即cache hit
缺失:CPU要访问的数据在cache中没有缓存,称为“缺失”,即cache miss
cache hit🎜🎜🎜missing🎜 : les données auxquelles le processeur doit accéder ne sont pas mises en cache dans le cache, ce qui est appelé "manquant", c'est-à-dire manque de cache🎜4. Qu'est-ce que la ligne de cache ?
ligne de cache : élevée speed Cache line, divise le cache en plusieurs blocs égaux, et la taille de chaque bloc est appelée ligne de cache. cache line:高速缓存行,将cache平均分成相等的很多块,每一个块大小称之为cache line。
cache line也是cache和主存之间数据传输的最小单位.
当CPU试图load一个字节数据的时候,如果cache缺失,那么cache控制器会从主存中一次性的load cache line大小的数据到cache中。例如,cache line大小是8字节。CPU即使读取一个byte,在cache缺失后,cache会从主存中load 8字节填充整个cache line。
CPU访问cache时的地址编码,通常由tag、index和offset三部分组成:
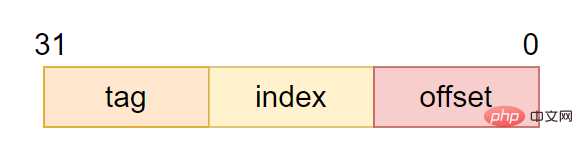
tag(标记域):用于判断cache line缓存的数据的地址是否和处理器寻址地址一致。
- index(索引域):用于索引和查找地址在高速缓存中的哪一行
-
offsetla ligne de cache est également la plus petite unité de transfert de données entre le cache et la mémoire principaleLorsque le processeur tente de charger un octet de données, si le cache est manquant, le contrôleur de cache chargera simultanément les données de la taille d'une ligne de cache depuis la mémoire principale dans le cache. Par exemple, la taille de la ligne de cache est de 8 octets. Même si le processeur lit un octet, une fois le cache manquant, le cache chargera 8 octets de la mémoire principale pour remplir toute la ligne de cache.
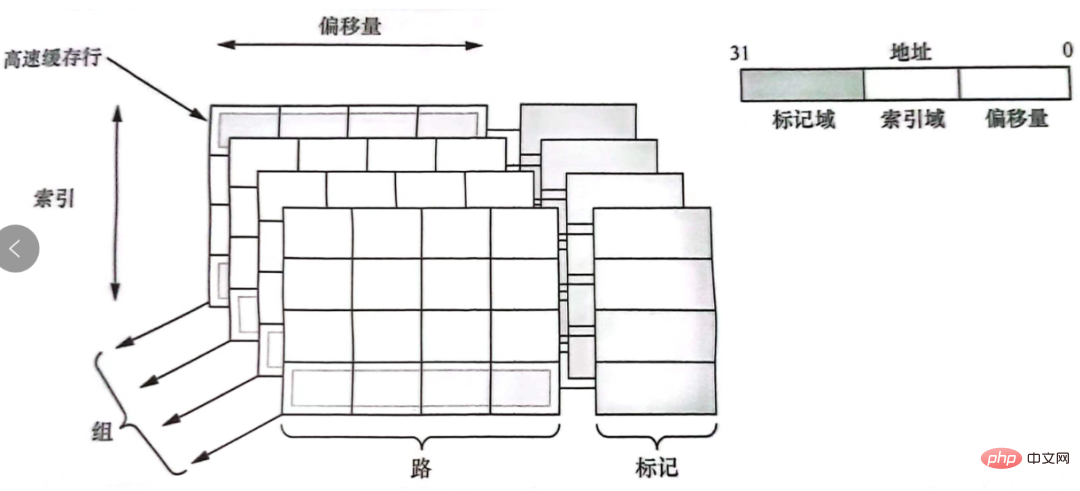
tag(tag field)🎜 : utilisé pour déterminer la ligne de cache cache Si l'adresse des données est cohérente avec l'adresse d'adressage du processeur. 🎜🎜🎜🎜-index(Champ d'index) 🎜 : Utilisé pour indexer et trouver dans quelle ligne du cache se trouve l'adresse 🎜offset🎜 (offset) 🎜 : Décalage dans la ligne de cache. Le contenu de la ligne de cache peut être adressé par mot ou par octet 🎜🎜🎜🎜La relation entre la ligne de cache et la balise, l'index, le décalage, etc. est comme indiqué sur la figure : 🎜
5. Le cache accède-t-il à une adresse virtuelle ou à une adresse physique ?
Nous savons que le CPU n'accède pas directement à la mémoire, mais le CPU émet une adresse virtuelle, qui est ensuite convertie en adresse physique par la MMU, puis les données sont récupérées de la mémoire en fonction de l'adresse physique . Alors le cache accède-t-il à une adresse virtuelle ou à une adresse physique ?
A : Pas nécessairement. Il peut s'agir d'une adresse virtuelle, d'une adresse physique ou d'une combinaison d'adresses virtuelles et physiques.
Parce que le cache a plusieurs méthodes d'organisation dans la conception matérielle :
VIVTCache virtuelVIVT虚拟高速缓存:虚拟地址的index,虚拟地址的tag。PIPT物理高速缓存:物理地址的index,物理地址的tag。VIPT物理标记的虚拟高速缓存:虚拟地址的index,物理地址的tag。
6、什么是歧义和别名问题?
歧义(
homonyms: l'index de l'adresse virtuelle, le tag de l'adresse virtuelle.
PIPT code><strong style="color: black;">Cache physique 🎜 : l'index de l'adresse physique, le tag de l'adresse physique. </strong>🎜🎜
VIPT code><strong style="color: black;">Cache virtuel de tag physique 🎜 : index d'adresse virtuelle, tag d'adresse physique. </strong>
homonymes )🎜 : À une même adresse virtuelle correspond des adresses physiques différentes🎜Alias (alias)alias):多个虚拟地址映射到了相同的物理地址(多个虚拟地址被称为别名)。
例如上述VIVT方式就会存在别名问题,那VIVT、PIPT和VIPT那个方式更好呢?
PIPT其实是比较理想的,因为index和tag都使用了物理地址,软件层面不需要任何维护就能避免歧义和别名问题。
VIPT的tag使用了物理地址,所以不存在歧义问题,但index是虚拟地址,所以可能也存在别名问题。
而VIVT : de nombreuses adresses virtuelles sont mappées sur la même adresse physique (plusieurs adresses virtuelles sont appelées alias). Par exemple, la méthode VIVT mentionnée ci-dessus aura un problème d'alias. Quelle méthode est la meilleure, VIVT, PIPT ou VIPT ?
PIPT est en fait plus idéal. Parce que l'index et la balise utilisent des adresses physiques. Aucune maintenance n'est requise au niveau logiciel pour éviter les ambiguïtés et les problèmes d'alias.
EtLa balise VIPTutilise la physique adresse, donc il n'y a pas de problème d'ambiguïté, mais l'index est une adresse virtuelle, donc il peut aussi y avoir un problème d'alias.
VIVT way, ambiguïté et des problèmes d'alias existent. En fait, ce qui est essentiellement utilisé dans le matériel maintenant est PIPT ou VIPT. VIVT a trop de problèmes, c'est devenu de l'histoire ancienne et personne ne l'utilisera. De plus, la méthode PIVT n’existe pas, car elle ne présente que des inconvénients et aucun avantage. Non seulement elle est lente, mais des problèmes d’ambiguïté et d’alias existent également.
L'organisation du cache, ainsi que les problèmes d'ambiguïté et d'alias, sont des éléments de contenu relativement volumineux. Ici, il vous suffit de savoir que l'adresse accessible par le cache peut être soit une adresse virtuelle, soit une adresse physique, soit une combinaison d'une adresse virtuelle et d'une adresse physique. Et différentes méthodes d’organisation poseront des problèmes d’ambiguïté et d’alias.
🎜🎜🎜7. Stratégie d'allocation de cache ? 🎜🎜 🎜🎜🎜🎜 fait référence à la façon dont le cache est alloué lorsqu'un échec de cache se produit. 🎜🎜Allocation de lecture : lorsque CPUlire données, se produitcache est manquant, ce In dans tous les cas, un ligne de cacheCache à partir des données lire à partir de la mémoire principale. CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配:当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache linePar défaut, cache tous prennent en charge la lecture et la distribution .
Allocation d'écriture : se produit lorsque le processeur écrit des données : rgba(27, 31, 35, 0.05);famille de polices : "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break : break-all ;color: rgb(239, 112, 96);"> La stratégie d'allocation d'écriture ne sera prise en compte que lorsque le cache est manquant. Lorsque nous ne prenons pas en charge l'allocation d'écriture, l'instruction d'écriture mettra uniquement à jour les données de la mémoire principale, puis se terminera. Lorsque l'allocation d'écriture est prise en charge, nous chargeons d'abord les données de la mémoire principale dans ligne de cache (équivalent à effectuer d'abord une allocation de lecture), puis mettre à jour données dans la ligne de cache.
8. Stratégie de mise à jour du cache ?
fait référence à la manière dont l'opération d'écriture doit mettre à jour les données lorsque le cache est atteint.
🎜Write passthrough🎜 : lorsque le processeur exécute l'instruction de stockage et que le cache arrive, nous mettons à jour les données dans le cache et mettons à jour les données dans la mémoire principale. 🎜Les données dans le cache et la mémoire principale sont toujours cohérentes🎜. 🎜Réécrire : mis à jour lorsque CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean fonctionne. Par conséquent, les données dans la mémoire principale peuvent être des données non modifiées, tandis que les données modifiées se trouvent dans le cache . Les données dans le cache et dans la mémoire principale peuvent être incohérentes.
Enfin
À propos du cache, ainsi que du TLB, MESI, du modèle de cohérence de la mémoire, etc., c'est quelque chose qui nécessite de la précipitation et du résumé pour vraiment le maîtriser.
Mais beaucoup de gens ne l'utilisent peut-être pas. Ce n'est que lorsqu'il s'agit de problèmes de performances et lorsque vous avez besoin d'améliorer le taux de réussite du cache que vous connaîtrez l'importance de cette connaissance.
Concernant les connaissances abordées dans cet article, j'ai résumé une carte mentale des connaissances de base du cache :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- guide d'installation php7 (windows) pour activer Zend Opcache
- Qu'est-ce que le cache ?
- Qu'est-ce qu'OPCache ? Comment utiliser OPCache pour améliorer les performances PHP ?
- Quelle est la différence entre le formatage de la partition de cache et la restauration des paramètres d'usine ?
- Quelles sont les trois méthodes de mappage d'adresses entre la mémoire principale et le cache ?