Les collections Java, également appelées conteneurs, sont principalement composées de Dérivé de deux interfaces principales (Interface) : 两大接口 (Interface) 派生出来的: Collection 和 MapCollection et Carte
Comme son nom l'indique, les conteneurs sont utilisés pour stocker des données.
Ensuite, la différence entre ces deux interfaces est la suivante :
Collection stocke un seul élément ;
Map stocke les paires clé-valeur.
C'est-à-dire que les célibataires sont placés dans la collection et les couples sont placés dans la carte. (Alors, quelle est votre place ?
En apprenant ces frameworks de collection, je pense qu'il y a 4 objectifs :
Effacer la correspondance entre chaque interface et classe ;
Être familier avec les API couramment utilisées pour chaque interface et classe ;
Être capable de choisir des structures de données appropriées et d'analyser les avantages et les inconvénients pour différents scénarios
Apprendre la conception du code source et être capable de répondre à des entretiens
À propos de Map, l'article précédent. sur HashMap en a déjà parlé. C'est très complet et détaillé, je n'entrerai donc pas dans les détails dans cet article. Si vous n'avez pas encore lu cet article, veuillez vous rendre sur le compte officiel et répondre "HashMap" à. lire l'article~
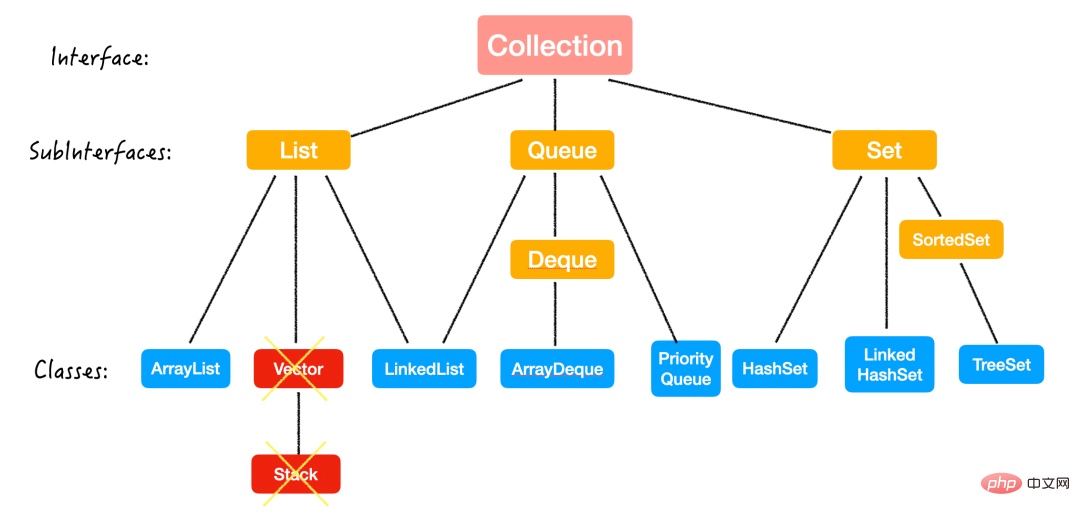
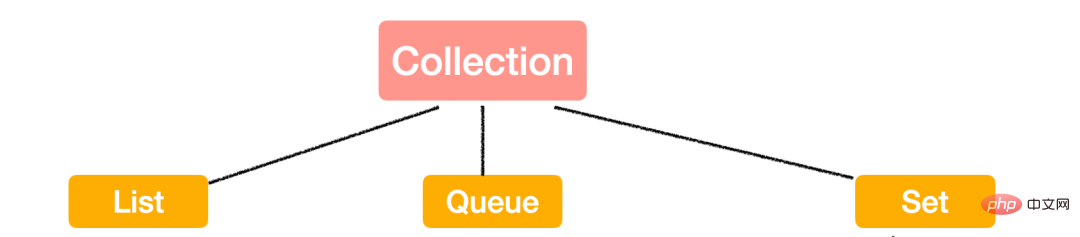
Collection
Regardons d'abord la Collection de niveau supérieur.
Collection définit également de nombreuses méthodes, qui sont également héritées de diverses sous-interfaces et classes d'implémentation. L'utilisation de ces API est également un test courant dans le travail quotidien et les entretiens, examinons donc d'abord ces méthodes.
L'ensemble d'opérations n'est rien de plus que les quatre catégories "Ajouter, Supprimer, Modifier et Vérifier", également appelées CRUD :
Créer, Lire, Mettre à jour et Supprimer.
Ensuite, je divise également ces API en ces quatre catégories :
Fonction
méthode
add
add()/addAll()
delete
remove()/removeAll()
changer
Non disponible dans l'interface de collection
Check
contains()/containsAll()
Autres
isEmpty()/size()/toArray()
Regardez-le en détail ci-dessous :
Ajouté :
boolean add(E e);
add() Le type de données transmis doit être Object, donc lors de l'écriture du type de données de base, le boxing automatique et le déballage automatique seront effectués. add() 方法传入的数据类型必须是 Object,所以当写入基本数据类型的时候,会做自动装箱 auto-boxing 和自动拆箱 unboxing。
还有另外一个方法 addAll(),可以把另一个集合里的元素加到此集合中。
boolean addAll(Collection<? extends E> c);
删:
boolean remove(Object o);
remove()是删除的指定元素。
那和 addAll() 对应的, 自然就有removeAll()
Il existe une autre méthode
boolean removeAll(Collection<?> c);
Supprimer :
boolean contains(Object o);
remove() est l'élément spécifié qui est supprimé. 🎜🎜Nahe addAll ( ) En conséquence, il y a naturellement removeAll() consiste à supprimer tous les éléments de l'ensemble B. 🎜
boolean containsAll(Collection<?> c);
🎜🎜🎜Changement : 🎜🎜🎜🎜Il n'y a pas d'opération directe pour modifier des éléments dans l'interface de collection. Quoi qu'il en soit, la suppression et l'ajout peuvent compléter le changement ! 🎜
查:
查下集合中有没有某个特定的元素:
boolean contains(Object o);
查集合 A 是否包含了集合 B:
boolean containsAll(Collection<?> c);
还有一些对集合整体的操作:
判断集合是否为空:
boolean isEmpty();
集合的大小:
int size();
把集合转成数组:
Object[] toArray();
以上就是 Collection 中常用的 API 了。
在接口里都定义好了,子类不要也得要。
当然子类也会做一些自己的实现,这样就有了不同的数据结构。
那我们一个个来看。
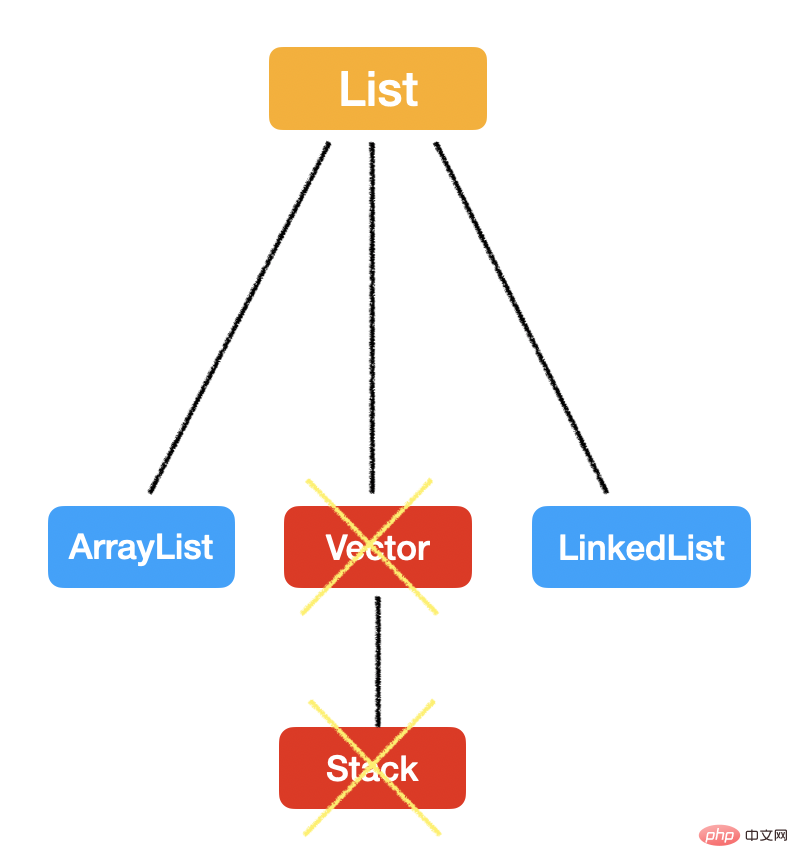
List
List 最大的特点就是:有序,可重复。
看官网说的:
An ordered collection (also known as a sequence).
Unlike sets, lists typically allow duplicate elements.
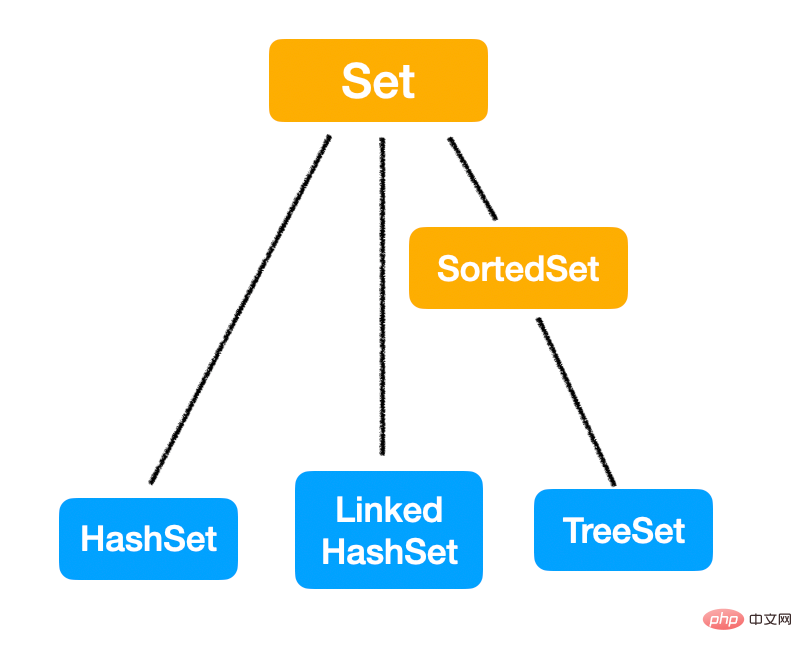
Cette fois, j'ai également mentionné les caractéristiques de Set. C'est complètement à l'opposé de List is 无序,不重复.
List peut être implémenté de deux manières : LinkedList et ArrayList. La question la plus fréquemment posée lors des entretiens est de savoir comment choisir entre ces deux structures de données.
Pour ce type de problème de sélection : La première consiste à déterminer si la structure de données peut remplir les fonctions requises ; Si les deux peuvent être complétées, la seconde consiste à déterminer laquelle est la plus efficace ;
(Tout est comme ça.
Regardons spécifiquement les API de ces deux classes et leur complexité temporelle :
Fonction
Méthode
ArrayList
LinkedList
add(E e)
O(1)
O(1)
augmenter
ajouter(int index, E e)
O(n)
O(n)
delete
remove(int index)
O(n)
O(n)
delete
remove( E e)
O(n)
O(n)
change
set(int index, E e)
O(1)
O(n)
check
get (int index )
O(1)
O(n)
Quelques explications :
add(E e) ajoute des éléments à la queue. Bien qu'ArrayList puisse s'étendre, la complexité temporelle amortie est toujours O(1). add(E e) 是在尾巴上加元素,虽然 ArrayList 可能会有扩容的情况出现,但是均摊复杂度(amortized time complexity)还是 O(1) 的。
add(int index, E e)是在特定的位置上加元素,LinkedList 需要先找到这个位置,再加上这个元素,虽然单纯的「加」这个动作是 O(1) 的,但是要找到这个位置还是 O(n) 的。(这个有的人就认为是 O(1),和面试官解释清楚就行了,拒绝扛精。
add(int index, E e) consiste à ajouter un élément à une position spécifique. LinkedList doit d'abord trouver cette position, puis ajouter cet élément. Bien que la simple action "ajouter" soit O(1), elle doit trouver. this La position est toujours O(n). (Certaines personnes pensent que c'est O(1). Expliquez-le simplement clairement à l'intervieweur et refusez d'assumer la responsabilité.
remove(int index) consiste à supprimer l'élément à cet index, donc
ArrayList trouve cet élément. est O(1), mais après la suppression, les éléments suivants doivent être avancés d'une position, donc la complexité amortie est O(n)
LinkedList doit également trouver l'index en premier, et ce processus est O(n); ), donc le tout est aussi O(n)
remove(E e) est le premier élément vu par Remove, puis
ArrayList doit d'abord trouver cet élément. Ce processus est O(n), puis se déplace Après la division, vous devez avancer d'une position, qui est O(n), et le total est toujours O(n) LinkedList doit également être trouvée en premier, ce processus est O(n), puis supprimé, ce processus est O (1) et le total est O (n). avec un tableau
La plus grande différence entre les tableaux et les listes chaînées est que
les tableaux sont accessibles de manière aléatoire (accès aléatoire).
Cette fonctionnalité permet d'obtenir le nombre à n'importe quelle position du tableau en un temps O(1) via l'abonnement, mais cela ne peut pas être fait avec la liste chaînée, et il ne peut être parcouru qu'un par un à partir du début.
🎜C'est-à-dire qu'en termes de deux fonctions "modification et recherche", parce que le tableau est accessible de manière aléatoire, ArrayList est très efficace. 🎜
Qu'en est-il de « l'ajout et la suppression » ?
Si le temps nécessaire pour trouver cet élément n'est pas pris en compte,
En raison de la continuité physique du tableau, lors de l'ajout ou de la suppression d'éléments, tout va bien à la queue, mais d'autres endroits entraîneront le déplacement des éléments suivants, donc le l'efficacité est moindre ; et les listes liées peuvent facilement se déconnecter de l'élément suivant, insérer directement de nouveaux éléments ou supprimer d'anciens éléments.
Mais, en fait, il faut considérer le temps pour retrouver les éléments. . . Et s'il est exploité à la queue, ArrayList sera plus rapide lorsque la quantité de données est importante.
Donc :
Modifiez et sélectionnez ArrayList ;
Ajoutez et supprimez la ArrayList sélectionnée à la fin
Dans d'autres cas, si la complexité temporelle est la même ; , il est recommandé de choisir ArrayList car la surcharge est plus petite ou l'utilisation de la mémoire est plus efficace.
Vector
Comme dernier point de connaissance sur List, parlons de Vector. C’est aussi un article révélateur d’âge, utilisé par tous les grands.
Ensuite, Vector, comme ArrayList, hérite également de java.util.AbstractList, et la couche inférieure est également implémentée à l'aide de tableaux.
Mais il est désormais obsolète car... il ajoute trop de synchronisation !
Chaque avantage a un coût. Le coût de la sécurité des threads est une faible efficacité, ce qui peut facilement devenir un goulot d'étranglement dans certains systèmes. Nous n'ajoutons donc plus de synchronisation au niveau de la structure des données, mais transférons cette tâche à notre programme. ==
Donc, la question courante d'entretien : quelle est la différence entre Vector et ArrayList ? Répondre à cette question n'est pas très complet.
Jetons un coup d'œil aux réponses les plus votées sur le débordement de pile :
La première est le problème de sécurité des threads qui vient d'être mentionné. La seconde est la différence dans l'ampleur de l'expansion lors de l'expansion.
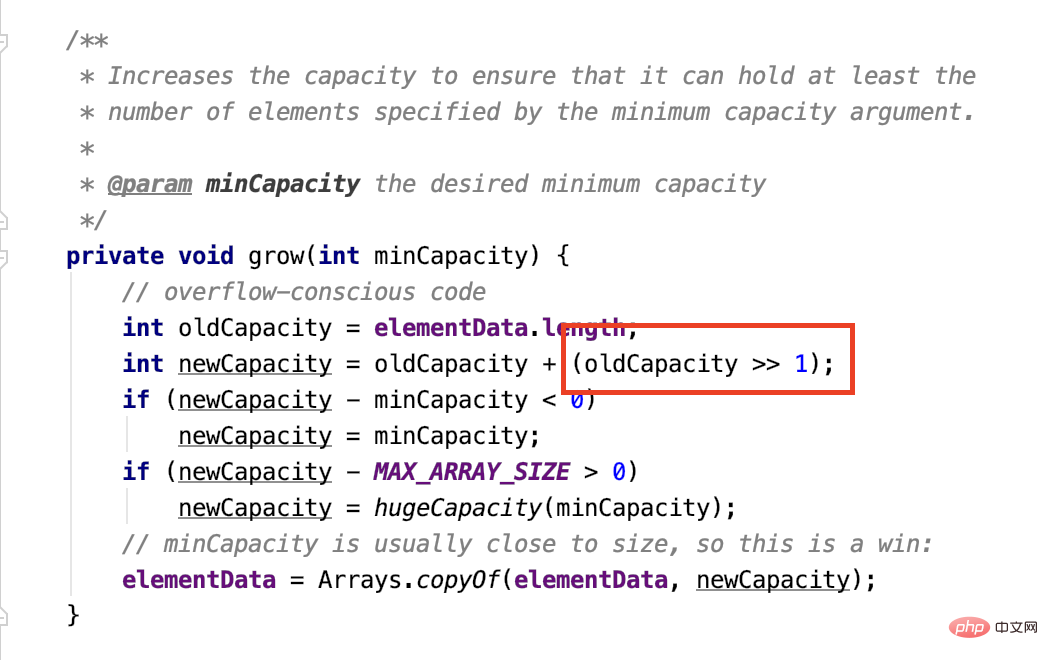
Vous devez regarder le code source pour cela :
Il s'agit d'une implémentation d'extension d'ArrayList. Cette opération de décalage arithmétique vers la droite consiste à déplacer le nombre binaire de ce nombre d'un bit vers la droite, et le bit de signe complémentaire le plus à gauche, mais comme il n'y a pas de nombre négatif dans la capacité, nous ajoutons donc toujours 0.
L'effet du déplacement d'une position vers la droite est de diviser par 2, alors la nouvelle capacité définie est 1,5 fois de la capacité d'origine.
Regardons à nouveau Vector :
Parce qu'habituellement,capacitéIncrement n'est pas défini par nous, donc par défaut il est étendu deux fois.
Si vous répondez à ces deux points, tout ira bien.
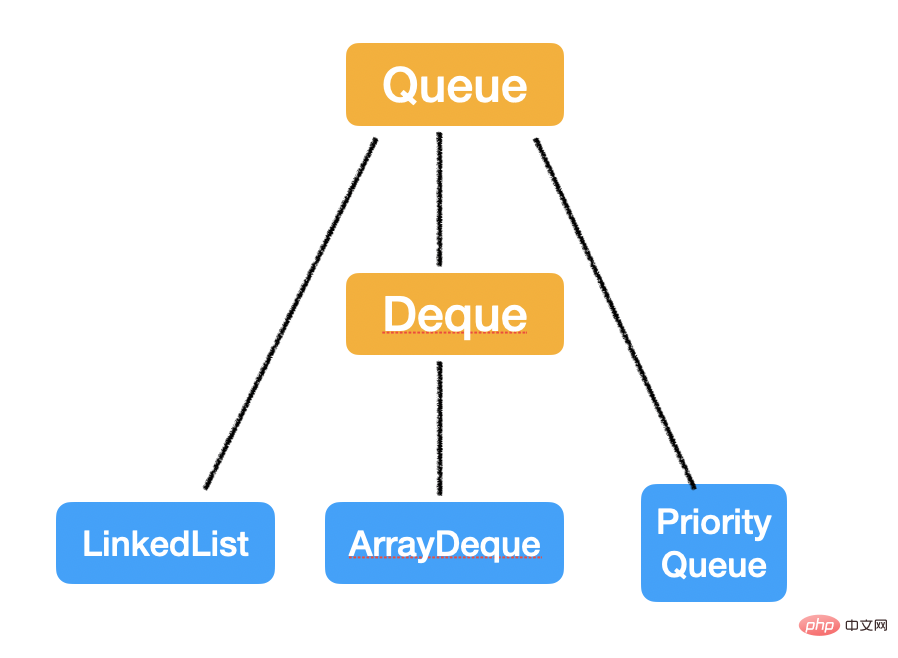
Queue & Deque
Queue est une structure de données linéaire qui entre à une extrémité et sort à l'autre extrémité tandis que Deque peut entrer et sortir aux deux extrémités ;
Queue
L'interface Queue en Java est un peu déroutante. De manière générale, la sémantique des files d'attente est First in first out (FIFO).
Mais il y a une exception ici, c'est-à-dire que PriorityQueue, également appelé tas, ne sort pas dans l'ordre de l'heure d'entrée, mais sort selon la priorité spécifiée, et son fonctionnement n'est pas O(1), le calcul de complexité temporelle C'est un peu compliqué, nous en discuterons donc dans un article séparé plus tard.
La méthode Queuesite officiel[1] a été résumée. Elle comporte deux ensembles d'API et les fonctions de base sont les mêmes, mais :
.
Un groupe lancera une exception ;
L'autre groupe renverra une valeur spéciale.
Fonction
Lancer une exception
Valeur de retour
Ajouter
ajouter(e)
offre(e)
Supprimer
remove()
sondage()
Regardez
element()
peek()
Pourquoi lève-t-il une exception ?
Par exemple, si la file d'attente est vide, alors remove() lèvera une exception, mais poll() renverra null ; element() lèvera une exception et peek() renverra simplement null.
Comment se fait-il que add(e) lève une exception ?
Certaines files d'attente ont des limites de capacité, comme BlockingQueue Si elle a atteint sa capacité maximale et ne sera pas étendue, une exception sera levée mais si offre(e), elle retournera faux.
Donc. comment choisir ? :
Tout d'abord, si vous souhaitez l'utiliser, utilisez le même ensemble d'API, et l'avant et l'arrière doivent être unifiés
Deuxièmement, selon les besoins ; Si vous en avez besoin pour lancer des exceptions, utilisez celui qui génère des exceptions ; mais il n'est fondamentalement pas utilisé pour résoudre des problèmes d'algorithme, alors choisissez simplement celui qui renvoie des valeurs spéciales.
Deque
Deque peut être entré et sorti des deux extrémités. Naturellement, il y a des opérations pour le premier côté et des opérations pour le dernier côté. Ensuite, il y a deux groupes à chaque extrémité, un groupe lance. une exception et l'autre groupe Renvoie une valeur spéciale :
fonction
lève une exception
valeur de retour
add
addFirst(e)/ addLast(e)
offerFirst(e)/ offerLast(e)
Delete
removeFirst()/ removeLast()
pollFirst()/ pollLast()
Look
getFirst()/ getLast()
peekFirst()/ peekLast()
Il en va de même lors de son utilisation. Si vous souhaitez l'utiliser, utilisez le même groupe.
Ces API de Queue et Deque ont une complexité temporelle de O(1), pour être précis, c'est une complexité temporelle amortie.
Classes d'implémentation
Il existe trois classes d'implémentation :
Donc,
Si vous souhaitez implémenter la sémantique de la "file d'attente normale - premier entré, premier sorti", utilisez LinkedList ou ArrayDeque To réaliser ;
Si vous souhaitez implémenter la sémantique de "file d'attente prioritaire", utilisez PriorityQueue
Si vous souhaitez implémenter la sémantique de "pile", utilisez ArrayDeque ;
Jetons un coup d'œil un par un.
Lors de l'implémentation d'une file d'attente commune, Comment choisir entre LinkedList ou ArrayDeque ?
Jetons un coup d'œil à la réponse la plus votée sur StackOverflow[2] :
En résumé, il est recommandé d'utiliser ArrayDeque en raison de sa grande efficacité, tandis que LinkedList aura d'autres frais supplémentaires (aérien).
Quelles sont les différences entre ArrayDeque et LinkedList ?
Toujours avec la même question tout à l'heure, voici le meilleur résumé à mon avis :
ArrayDeque est un tableau extensible, LinkedList est une structure de liste chaînée
ArrayDeque ne peut pas stocker de valeurs nulles, mais LinkedList peut ;
ArrayDeque est plus efficace lors de l'exécution des opérations d'ajout et de suppression au début et à la fin, mais LinkedList ne supprime qu'un élément au milieu lorsqu'il doit être supprimé et que l'élément a été trouvé. O( 1);
ArrayDeque est plus efficace en termes d'utilisation de la mémoire.
Donc, tant que vous n'avez pas à stocker de valeurs nulles, choisissez ArrayDeque !
Ensuite, si un intervieweur très expérimenté vous demande, dans quelles circonstances devriez-vous choisir d'utiliser LinkedList ?
La valeur est placée sur la clé dans la carte, et un PRESENT est placé sur la valeur. C'est un objet statique, équivalent à un espace réservé, et chaque clé pointe vers cet objet.
Le principe de mise en œuvre spécifique, ajouter, supprimer, modifier, vérifierquatre opérations, ainsi que hash conflict, hashCode()/equals() et d'autres problèmes ont tous été abordés dans l'article HashMap. , ici je n'entrerai pas dans les détails. Les amis qui ne l'ont pas lu peuvent répondre à « HashMap » en arrière-plan du compte officiel pour obtenir l'article~
Résumé
Allons-y. revenons à l'image du début, est-ce clair ?
Il y a en fait beaucoup de contenu sous chaque structure de données, comme PriorityQueue. Cet article n'entre pas dans les détails, car ce type mettra beaucoup de temps à en parler. .
Si vous pensez que l'article est bon, le like à la fin de l'article est de retour, N'oubliez pas de me donner un "j'aime" et une "lecture"~
Enfin, de nombreux lecteurs m'ont posé des questions sur le groupe de communication, par considération j’ai un décalage horaire et c’est dur à gérer donc je ne l’ai pas encore fait.
Mais maintenant, j'ai trouvé un administrateur professionnel pour le gérer avec moi, donc "La base secrète de Sister Qi" est en préparation, et j'inviterai de grands noms du pays et de l'étranger à se joindre à nous pour vous apporter une perspective différente.
L'ouverture de la première phase du groupe d'échange est prévue mi-début juillet. J'enverrai alors des invitations dans le cercle d'amis, alors restez connectés !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Cet article est reproduit dans:. en cas de violation, veuillez contacter admin@php.cn Supprimer