
Maison >base de données >SQL >Pourquoi les spécifications de code exigent-elles que les instructions SQL ne comportent pas trop de jointures ?
Pourquoi les spécifications de code exigent-elles que les instructions SQL ne comportent pas trop de jointures ?
- Java学习指南avant
- 2023-07-26 16:51:041257parcourir
Envoyer la sous-question
Intervieweur : Avez-vous déjà utilisé Linux ?
Moi :Oui
Intervieweur :Quelle commande dois-je utiliser pour vérifier l'utilisation de la mémoire
Moi :gratuit ou top
Intervieweur :Pouvez-vous me dire quelles informations vous pouvez voir en utilisant la commande gratuite
Moi :Eh bien, comme le montre la figure ci-dessous, vous pouvez voir l'utilisation de la mémoire et du cache
total total mémoire
utilisée mémoire utilisée
libre mémoire libre
buff/cache cache utilisé
-
mémoire disponible

Intervieweur : Alors, savez-vous comment vider le cache utilisé (buff/cache)
Moi : em... Je ne sais pas
Intervieweur : sync; echo 3 > /proc/sys/vm/drop_caches Ensuite, nous pouvons vider le buff/le cache. Pouvez-vous me dire si je peux exécuter cette commande en ligne

Moi : (Envoyer le sous-sujet, je suis très content) Les bénéfices sont grands. Après avoir vidé le cache, nous aurons plus d'espace mémoire disponible Tout comme la petite fusée de xx Guardian sur PC, beaucoup de mémoire sera libérée avec. un clic
Intervieweur : em…., revenez en arrière et attendez la notification
Parlons de SQL Rejoignez-nous à nouveau
Intervieweur :Changez de sujet et parlez de votre compréhension de join
Moi : D'accord (si vous répondez encore mal, c'est fini) Saisissez l'opportunité)
Révision
La participation à SQL peut combiner des tables spécifiées selon certaines conditions et renvoyer les données au client
Il existe des moyens de rejoindre
jointure intérieure jointure intérieure
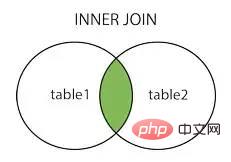
rejoindre à gauche rejoindre à gauche
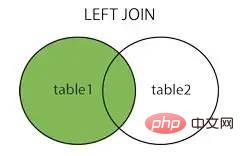
rejoindre à droite rejoindre à droite
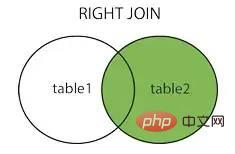
adhésion complète

Source de l'image : https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
Intervieweur : Si vous devez utiliser des instructions de jointure pendant le développement d'un projet, comment optimiser et améliorer les performances ?
Moi : Il existe deux situations, une avec une petite taille de données et une avec une grande taille de données.
Intervieweur : Alors ?
Moi : Pour
1 Si la taille des données est petite, mettez-les simplement en mémoire et c'est tout
2 Si la taille des données est grande
. , vous pouvez augmenter l'index Optimiser la vitesse d'exécution des instructions de jointure
Vous pouvez réduire le nombre de jointures grâce à des informations redondantes
Essayez de réduire le nombre de connexions de table Le nombre de connexions de table. pour une instruction SQL ne doit pas dépasser 5 fois
Intervieweur : On peut résumer que l'instruction join est relativement gourmande en performances, n'est-ce pas ?
Moi : Oui
Intervieweur : Pourquoi ?
Buffer
Moi : Il doit y avoir un processus de comparaison lors de l'exécution de l'instruction de jointure
Intervieweur : Oui
Moi :Il est relativement lent de comparer deux tables une par une, donc nous pouvons. lisez les données des deux tables dans un bloc de mémoire en séquence. En prenant le moteur InnoDB de MySQL comme exemple, nous pouvons certainement trouver la zone de mémoire appropriée en utilisant l'instruction suivanteshow variables like '%buffer%'
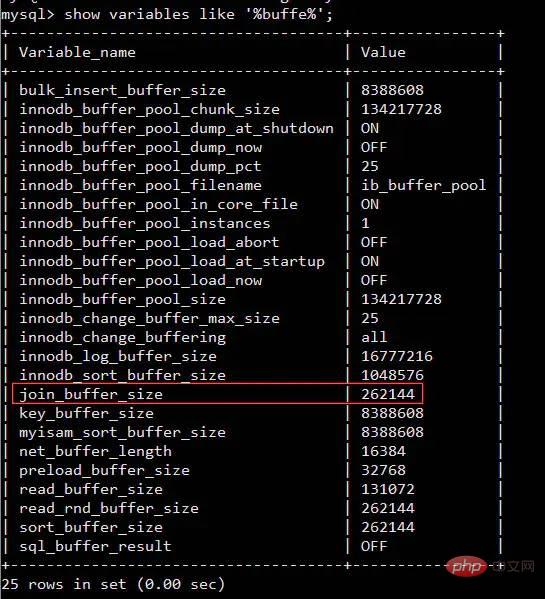
join_buffer_size comme indiqué dans la figure. La taille affectera la performance d'exécution de notre déclaration de jointure
Intervieweur : Quoi d'autre ?
Une prémisse majeure
Moi :Tout projet finira par être mis en ligne, et il est inévitable de générer des données, des données L'échelle ne peut pas être trop small
Intervieweur : Ça y est
Moi :La plupart des données de la base de données seront éventuellement enregistrées sur le disque dur et stockées sous forme de fichiers.
Prenons l'exemple du moteur InnoDB de MySQL
InnoDB utilise la page comme unité d'E/S de base, et la taille de chaque page est de 16 Ko
InnoDB créera un stockage pour chaque fichier de données .ibd de table
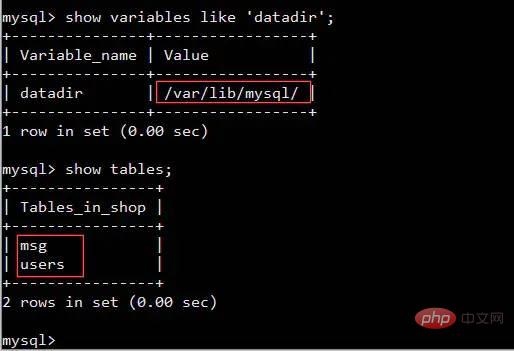
Vérification
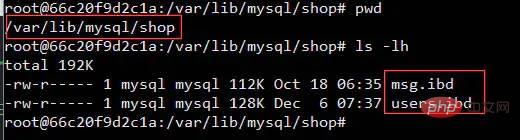
Moi :Cela signifie que nous devons lire autant de fichiers qu'il y a de tables à connecter. Bien que des index puissent être utilisés, des déplacements fréquents restent inévitables. La tête magnétique de. le disque dur
Intervieweur :C'est-à-dire que les mouvements fréquents de la tête magnétique affecteront les performances, n'est-ce pas ?
Moi :Oui, les frameworks open source actuels n'aiment-ils pas dire qu'ils améliorent considérablement les performances via la lecture et l'écriture séquentielles ? , comme hbase, kafka
Intervieweur : C'est vrai, pensez-vous que Linux a optimisé cela ? Astuce, vous pouvez réexécuter la commande gratuite pour jeter un œil
Moi : C'est étrange comme ça le cache est occupé Plus de 1,2G


Source de l'image : https://www.linuxatemyram.com/
Intervieweur : Avez-vous déjà pensé à
buff/ stocké dans le cache Quoi est?
Pourquoi buff/cache occupe-t-il autant de mémoire, et la mémoire disponible est disponible et il y a encore 1,1G ?
Pourquoi pouvez-vous nettoyer la mémoire occupée par buff/cache via deux commandes, mais vous ne pouvez libérer l'utilisé qu'en mettant fin au processus ?
Épinglez, réfléchissez bien s'il vous plaît
Quelques minutes plus tard
Moi : Libérer la mémoire occupée par buff/cache avec tant de désinvolture signifie que ce n'est pas important et la vider n'affectera pas le fonctionnement du système
Intervieweur : Pas tout à fait raison
Moi : Est-ce que ça pourrait être le cas ? Je pense à une phrase dans "CSAPP" (Compréhension approfondie des systèmes informatiques)
L'essence de la hiérarchie de la mémoire est que chaque couche de périphérique de stockage est le cache du périphérique de couche inférieure
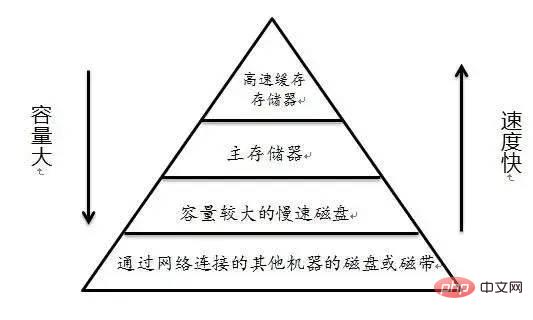
En langage profane termes, C'est-à-dire que Linux traitera la mémoire comme le cache du disque dur
Informations associées : http://tldp.org/LDP/sag/html/buffer-cache.html
Intervieweur : Maintenant, je sais que Comment dois-je répondre à la question des points
Moi :Je...

Algorithme d'adhésion
Intervieweur :Vous donner une autre chance, que feriez-vous si on vous le demandait implémenter l'algorithme Join ?
Moi : S'il n'y a pas d'index, la boucle imbriquée sera terminée. S'il existe un index, vous pouvez utiliser le index pour améliorer les performances.
Intervieweur : De retour à join_buffer, qu'est-ce qui, à votre avis, est stocké dans join_buffer ?
Moi : Pendant le processus d'analyse, la base de données sélectionnera une table et mettra les données qu'elle souhaite renvoyer et qu'elle devra comparer avec d'autres tables. . join_buffer
Intervieweur : Comment gérer ça quand il y a un index ?
Moi : C'est relativement simple, il suffit de lire directement les arbres d'index des deux tables pour comparaison et c'est tout. Laissez-moi vous présenter la méthode de traitement sans index
Nested Loop Join
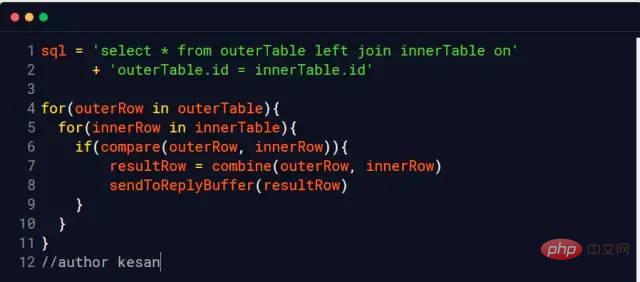
Bloquer la boucle imbriquée
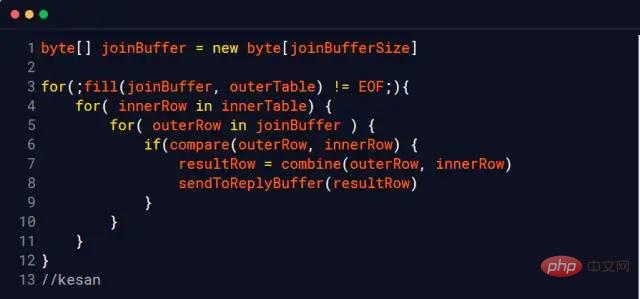
MySQL InnoDB utilisera cet algorithme lorsqu'aucun index ne peut être utilisé
Considérez les deux tables suivantes t_a et t_b
Lorsque l'index ne peut pas être utilisé pour effectuer une opération de jointure, InnoDB utilisera automatiquement l'algorithme de boucle imbriquée Block

Résumé
Quand j'étais à l'école, le professeur de base de données aimait le plus passer le test de paradigme de base de données. Ce n'est qu'au travail que j'ai appris que tout devait être basé sur la performance si cela pouvait être redondant. , utilisez-le s'il ne peut pas être redondant, rejoignez-le si la jointure affecte vraiment les performances. Essayez d'augmenter votre join_buffer_size ou passez à un disque SSD.
Références
"Compréhension approfondie des systèmes informatiques" - Chapitre 6 Hiérarchie de la mémoire
"Expériences et plaisir avec le cache disque Linux" L'auteur utilise plusieurs exemples pour illustrer l'impact du cache disque dur sur les performances d'exécution du programme
"Linux a mangé mon bélier》Explication des paramètres gratuits
Comment vider le buffer/pagecache (cache disque) sous Linux Explication de la commande sous-question au début de l'article
Comment MySQL fonctionne : Comprendre MySQL depuis la racine
Bloquer meilleure boucle de MariaDB Le document officiel explique l'implémentation de l'algorithme Block-Nested-Loop
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Conseils d'optimisation MySQL : Comment améliorer l'efficacité des instructions SQL
- Optimisation des instructions de requête MySql : comment localiser rapidement les problèmes de performances des instructions SQL
- Instructions SQL de MySql : comment optimiser et reconstruire
- Objet DbCommand dans le framework Yii : appeler directement les instructions SQL
- Pratique des expressions régulières PHP : correspondance des instructions SQL