
Maison >développement back-end >Tutoriel Python >Faire le point sur les bases des chaînes en Python
Faire le point sur les bases des chaînes en Python
- Go语言进阶学习avant
- 2023-07-25 16:14:491376parcourir
Pourquoi avons-nous besoin de ficelles ?
Lorsque vous appelez un navigateur pour vous connecter à certains sites Web, vous devez saisir un mot de passe. Une fois que le navigateur a transmis le mot de passe au serveur, le serveur vérifiera le mot de passe. Le processus de vérification consiste à transmettre le mot de passe précédemment enregistré. celui-ci. Comparez les mots de passe. S'ils sont égaux, alors le mot de passe est considéré comme correct, sinon il est considéré comme incorrect puisque le serveur veut stocker ces mots de passe, il peut utiliser une base de données (comme MySQL) pour y parvenir.
Bien sûr, par souci de simplicité, on peut d'abord trouver une variable pour stocker le mot de passe alors comment stocker les mots de passe avec des lettres ? C'est là que les chaînes sont utilisées.
1. Le format des chaînes en Python
La variable a définie ci-dessous stocke une valeur de type numérique.
a = 100
La variable b définie ci-dessous stocke une valeur de type chaîne.
b = "hello itcast.cn"
或者
b = 'hello itcast.cn'Petit résumé :
Les données entre guillemets doubles ou simples sont une chaîne
二、字符串输出
例:
name = 'ming'
position = '讲师'
address = '中山市平区建材城西路金燕龙办公楼1层'
print('--------------------------------------------------')
print("姓名:%s"%name)
print("职位:%s"%position)
print("公司地址:%s"%address)
print('--------------------------------------------------')结果:
--------------------------------------------------
姓名:ming
职位:讲师
公司地址:中山市昌平区建材城西路金燕龙办公楼1层
--------------------------------------------------
三、字符串输入
input通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存。
例:
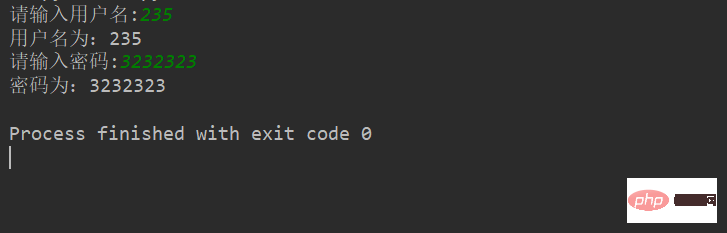
userName = input('请输入用户名:')
print("用户名为:%s"%userName)
password = input('请输入密码:')
print("密码为:%s"%password)结果:(根据输入的不同结果也不同)
4. Indices et découpage
1. Index des indices
soi-disant"Subscript"“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间。
生活中的 "下标"
超市储物柜

字符串中"下标"的使用
列表与元组支持下标索引好理解,字符串实际上就是字符的数组,所以也支持下标索引。
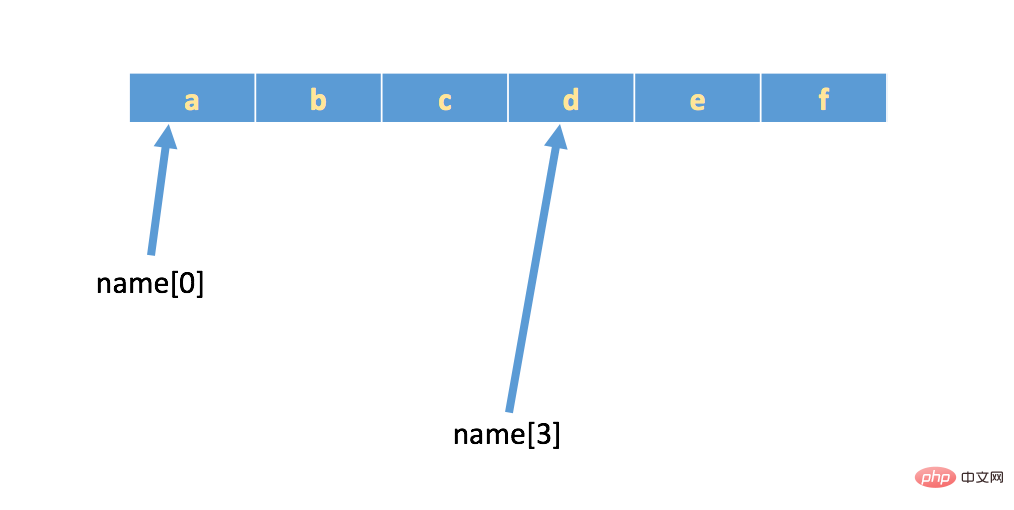
如果有字符串:name = 'abcdef',在内存中的实际存储如下:
如果想取出部分字符,那么可以通过下标 est le numéro, tout comme le numéro de l'armoire de stockage dans le supermarché. Vous pouvez trouver l'espace de stockage correspondant grâce à ce numéro.
"subscript" in life
🎜Casiers de supermarché🎜🎜
 🎜
🎜
🎜L'utilisation de "subscript" dans les chaînes🎜🎜
🎜Les listes et les tuples prennent en charge l'indexation en indice pour une compréhension facile. Les chaînes sont en fait des caractères. Les tableaux, donc l'indexation en indice est également prise en charge . 🎜🎜
🎜S'il y a une chaîne :🎜🎜name = 'abcdef'🎜🎜, en mémoire Le stockage réel est le suivant : 🎜🎜
 🎜
🎜
🎜Si vous souhaitez supprimer quelques caractères, alors vous pouvez passer 🎜🎜indice🎜🎜 Méthode, (notez que les indices en Python commencent à 0)🎜🎜🎜 name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])
运行结果:

2. 切片的概念:
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
3. 切片的语法:[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中,使用 :
例:
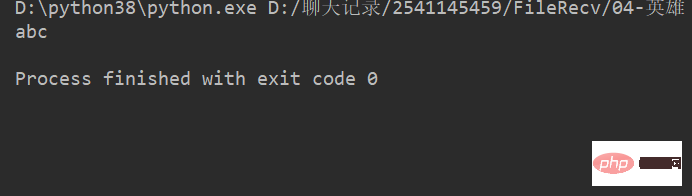
name = 'abcdef'
print(name[0:3]) # 取 下标0~2 的字符运行结果 :
例:
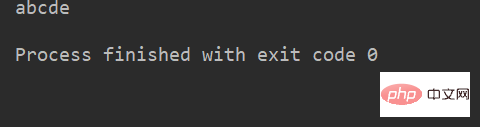
name = 'abcdef'
print(name[0:5]) # 取 下标为0~4 的字符运行结果:
例:
name = 'abcdef'
print(name[3:5]) # 取 下标为3、4 的字符运行结果:
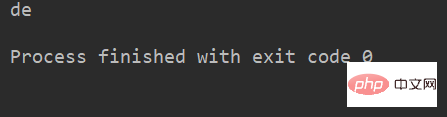
例:
name = 'abcdef'
print(name[2:]) # 取 下标为2开始到最后的字符运行结果:
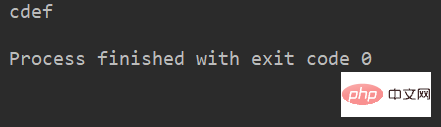
例:
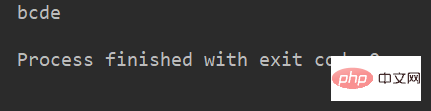
name = 'abcdef'
print(name[1:-1]) # 取 下标为1开始 到 最后第2个 之间的字符运行结果:
>>> a = "abcdef" >>> a[:3] #运行结果 'abc' >>> a[::2] #运行结果 'ace' >>> a[5:1:2] '' #运行结果 >>> a[1:5:2] 'bd' #运行结果 >>> a[::-2] 'fdb' #运行结果 >>> a[5:1:-2] 'fd' #运行结果
五、字符串常见16种操作
以字符串'lstr = 'welcome to Beijing Museumitcpps fdsfs',为例。
介绍字符常见的操作。
f35d6e602fd7d0f0edfa6f7d103c1b57 find
检测 str 是否包含在 lstr中,如果是返回开始的索引值,否则返回-1。
语法:
lstr.find(str, start=0, end=len(lstr))
例:
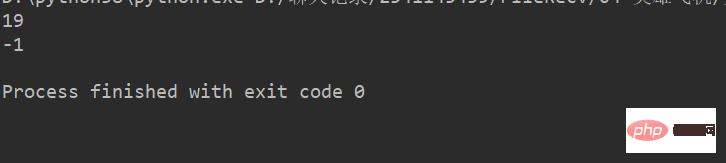
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.find("Museum"))
print(lstr.find("dada"))运行结果:
2cc198a1d5eb0d3eb508d858c9f5cbdb index
跟find()方法一样,只不过如果str不在 lstr中会报一个异常。
语法:
lstr.index(str, start=0, end=len(lstr))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.index("dada"))运行结果:

5bdf4c78156c7953567bb5a0aef2fc53 count
返回 str在start和end之间 在 lstr里面出现的次数
语法:
lstr.count(str, start=0, end=len(lstr))
例:
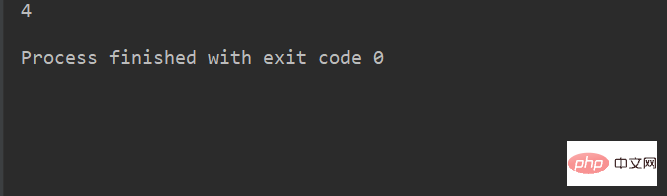
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.count("s"))运行结果:
23889872c2e8594e0f446a471a78ec4c replace
把 lstr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
1str.replace(str1, str2, 1str.count(str1))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.replace("s", "ttennd"))运行结果:

43ad812d3a971134e40facaca816c822 split
以 str 为分隔符切片 lstr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
1str.split(str=" ", 2)
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'
print(lstr.split("to", 5))运行结果:

efbfa0de8737dc86eae413541a49df20 capitalize
把字符串的第一个字符大写。
1str.capitalize()
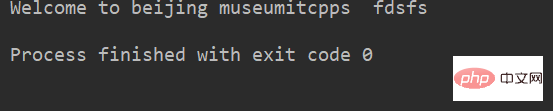
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.capitalize())
运行结果:
40107655ec554331c1c6222ab67a141c title
把字符串的每个单词首字母大写。
>>> a = "hello itcast" >>> a.title() 'Hello Itcast' #运行结果
37cd6113a8c348d99fa846f2c6fcea98 startswith
检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
1str.startswith(obj)
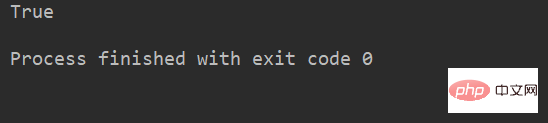
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.startswith('we'))
运行结果:
c161494dba5e0dd0fb25d890c74e408d endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.
1str.endswith(obj)
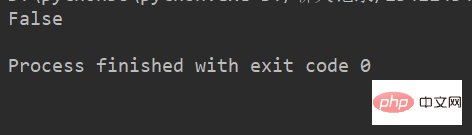
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.endswith('hfs'))
运行结果:
eebe431eeb58984ec8915354762c30c6 lower
转换 lstr 中所有大写字符为小写
1str.lower()
例:
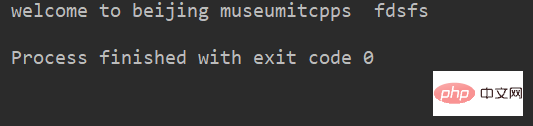
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.lower())
运行结果:
8494a7152f0ce9541779ac435cbe6aab upper
转换 lstr 中的小写字母为大写
1str.upper()
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.upper())
运行结果:

8141c42af04c24b6c356713ee262f06a strip
删除lstr字符串两端的空白字符。
>>> a = "\n\t itcast \t\n" >>> a.strip() 'itcast' #运行结果
686111046a42eeee58032dc06d5f19ff rfind
类似于 find()函数,不过是从右边开始查找。
1str.rfind(str, start=0,end=len(1str) )
例:
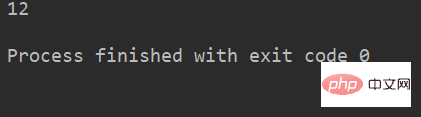
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.rfind('eijing'))
运行结果:
636f057c96f4f4778f19692abc05b2ee rindex
类似于 index(),不过是从右边开始。
1str.rindex( str, start=0,end=len(1str))
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.rindex('eijing'))
运行结果:
96da73a672242ebd5ff412f183fa77ab partition
把lstr以str分割成三部分,str前,str和str后。
1str.partition(str)
例:
lstr = 'welcome to Beijing Museumitcpps fdsfs' print(lstr.partition('eijing'))
运行结果:

600cc0b653b1411e40248dd4d217d958 join
mystr 中每个字符后面插入str,构造出一个新的字符串。
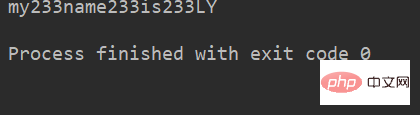
lstr = 'welcome to Beijing Museumitcpps fdsfs' str='233' lstr.join(str) li=["my","name","is","LY"] print(str.join(li))
运行结果:
六、总结
本文详细的讲解了Python基础 ( 字符串 )。介绍了有关字符串,切片的操作。下标索引。以及在实际操作中会遇到的问题,提供了解决方案。希望可以帮助你更好的学习Python。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Utilisez Python pour supprimer tous les fichiers du disque en un seul clic, arrêter automatiquement et laisser les portes dérobées
- Tout ce que vous devez savoir sur les listes Python
- Un article pour vous guider à travers les fonctions anonymes de Python
- Un article pour vous aider à comprendre l'interface de processus distribué de Python
- Un article vous apprend à utiliser trois fonctions simples en Python
- Choses à faire le point sur la liste des bases de Python