
Maison >développement back-end >Tutoriel Python >Un article vous guidera à travers la bibliothèque urllib en Python (URL d'exploitation)
Un article vous guidera à travers la bibliothèque urllib en Python (URL d'exploitation)
- Go语言进阶学习avant
- 2023-07-25 14:08:04951parcourir
1. Manipulation des URL
urllib fournit une série de fonctions pour manipuler les URL. Classer le contenu associé.
2. Get()
urllib'srequestrequest模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的URLhttps://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078 le module peut facilement capturer le contenu de l'URL, c'est-à-dire envoyer une requête GET à la page spécifiée, puis renvoyer une réponse HTTP : Par exemple, l'URL de Douban
https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078🎜🎜explorez et renvoyez la réponse : 🎜🎜🎜🎜
from urllib import request
with request.urlopen('https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
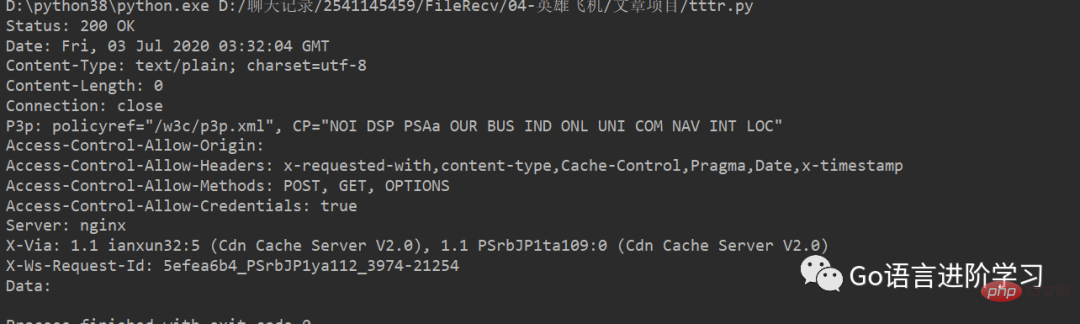
print('Data:', data.decode('utf-8'))Vous pouvez voir les en-têtes et les données JSON de la réponse HTTP :
Si vous souhaitez simuler le navigateur envoyant une requête GET, vous devez utiliser Request对象,通过往Request对象添加HTTP头,就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
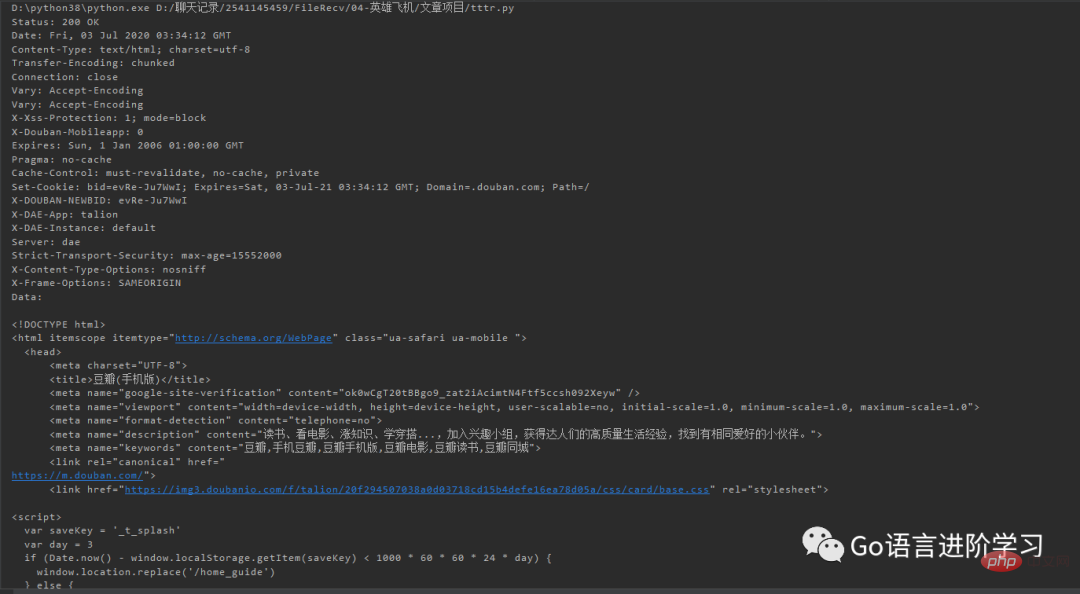
print('Data:', f.read().decode('utf-8'))这样豆瓣会返回适合iPhone的移动版网页:
三、Post()
如果要以POST发送一个请求,只需要把参数dataobjet, en allant dans Requête En ajoutant un en-tête HTTP à l'objet code>
, vous pouvez déguiser la requête en navigateur. Par exemple, simulez l'iPhone 6 pour demander la page d'accueil de Douban :
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))🎜🎜De cette façon, Douban renverra la version mobile de la page Web adaptée à l'iPhone : 🎜🎜🎜🎜 🎜🎜🎜🎜
🎜🎜🎜🎜
🎜Trois, Post()🎜
🎜 🎜
🎜🎜Si vous souhaitez envoyer une requête avec POST, il vous suffit de mettre les paramètres 🎜🎜data🎜🎜 est transmis en octets. 🎜🎜🎜
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
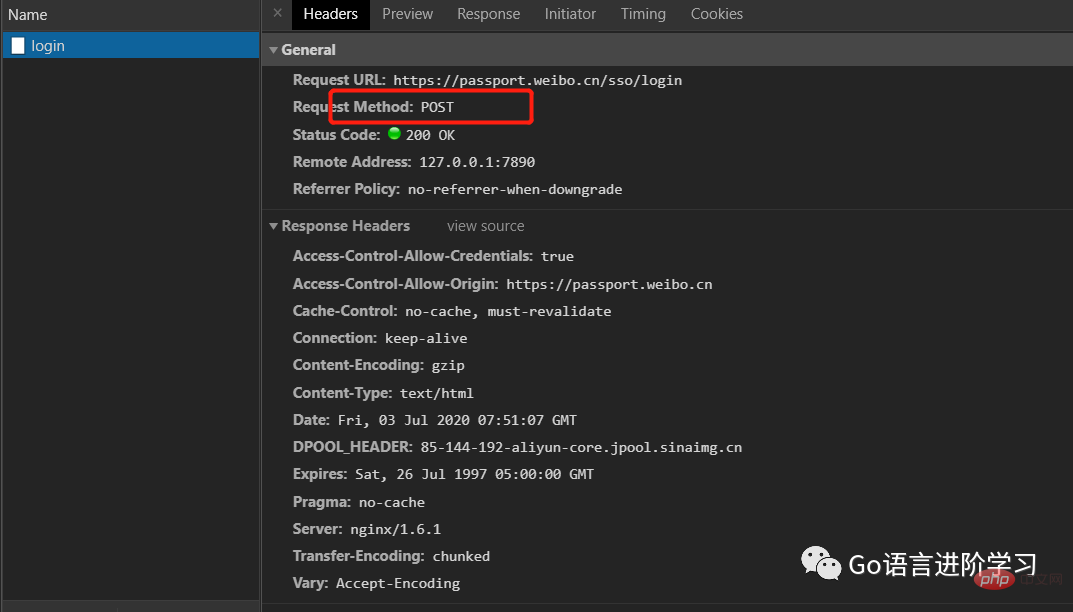
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
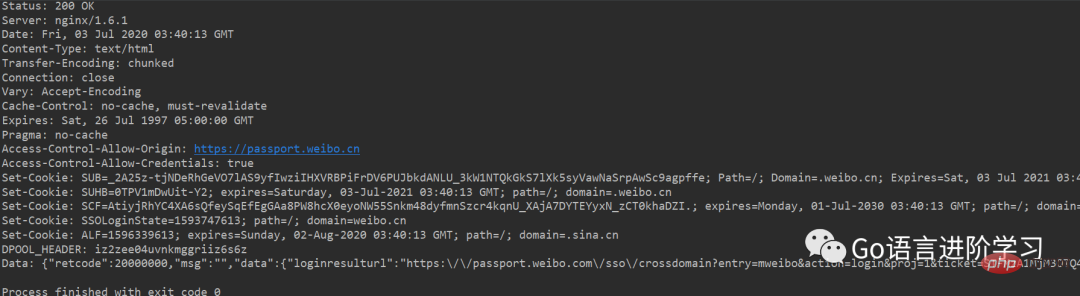
print('Data:', f.read().decode('utf-8'))如果登录成功,获得的响应如下:
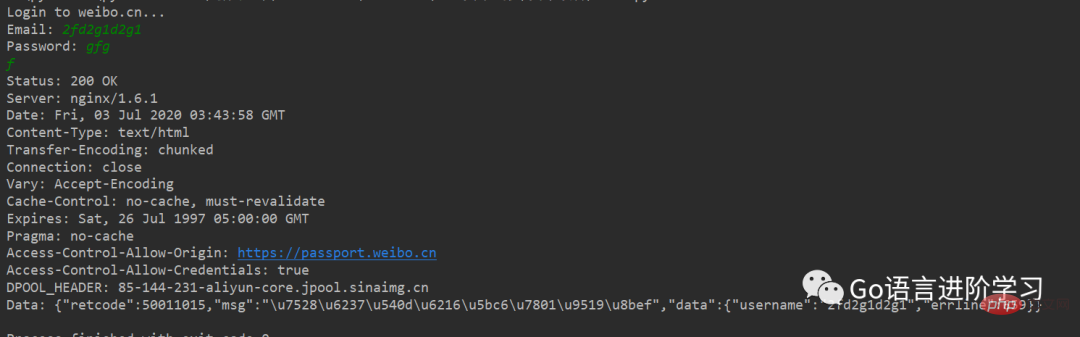
如果登录失败,获得的响应如下:
四、Handler
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,需要利用ProxyHandler来处理,示例代码如下:
import urllib.request
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"https": "27.191.234.69:9999"})
nullproxy_handler = urllib.request.ProxyHandler({})
# 定义一个代理开关
proxySwitch = True
# 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
# 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
# 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urllib.request.urlopen(request)
# 获取服务器响应内容
html = response.read().decode("utf-8")
# 打印结果
print(html)如果代理成功返回网址的信息。
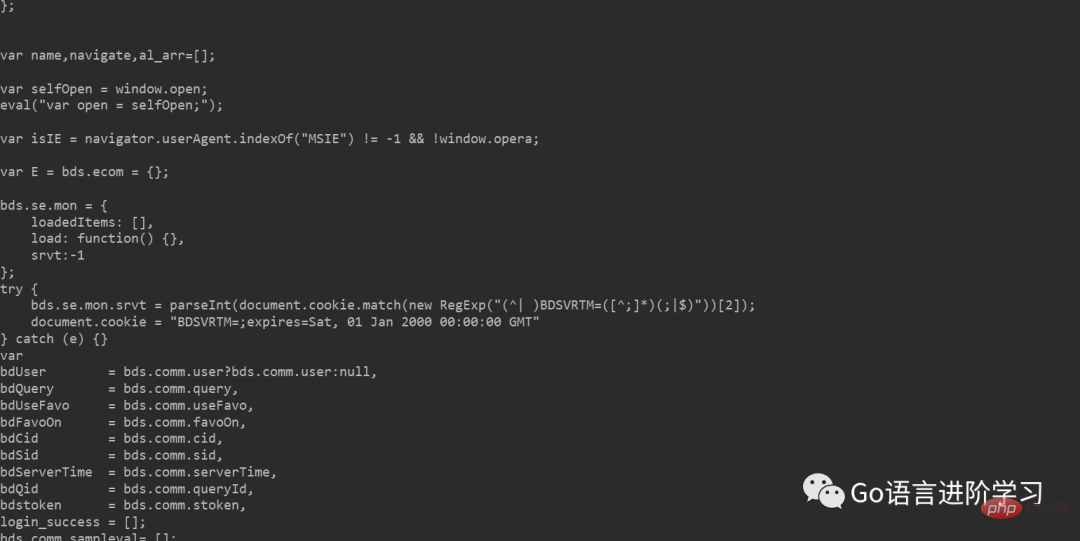
Si l'URL ou l'adresse proxy est erronée, revenez à l'interface ci-dessous.

5. Résumé
L'utilisation du langage Python peut aider tout le monde à mieux apprendre Python. La fonction fournie par urllib est d'utiliser des programmes pour effectuer diverses requêtes HTTP. Si vous souhaitez simuler un navigateur pour remplir une fonction spécifique, vous devez déguiser la demande en navigateur. La méthode de camouflage consiste d'abord à surveiller les requêtes envoyées par le navigateur, puis à les camoufler en fonction de l'en-tête de requête du navigateur. L'en-tête User-Agent est utilisé pour identifier le navigateur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de la solution à l'erreur urlopen dans python3 urllib
- Bases de l'utilisation de la bibliothèque urllib.request
- Explication détaillée de l'utilisation de Python urllib2
- Que dois-je faire si je souhaite utiliser le package urllib2 dans python3.6 ?
- Comment installer la bibliothèque urllib2 en Python