
Maison >Périphériques technologiques >IA >Le nouveau papier brûlant de Microsoft : Transformer s'étend à 1 milliard de jetons
Le nouveau papier brûlant de Microsoft : Transformer s'étend à 1 milliard de jetons

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-22 15:34:011206parcourir
Alors que chacun continue de mettre à niveau et d'itérer ses propres grands modèles, la capacité du LLM (Large Language Model) à traiter les fenêtres contextuelles est également devenue un indicateur d'évaluation important.
Par exemple, le grand modèle de célébrité GPT-4 prend en charge 32 000 jetons, ce qui équivaut à 50 pages de texte ; Anthropic, fondée par un ancien membre d'OpenAI, a augmenté les capacités de traitement des jetons de Claude à 100 000, soit environ 75 000 mots, ce qui équivaut à peu près à un résumé en un clic de la première partie de "Harry Potter".
Dans les dernières recherches de Microsoft, ils ont cette fois directement étendu Transformer à 1 milliard de jetons. Cela ouvre de nouvelles possibilités pour modéliser des séquences très longues, comme par exemple traiter un corpus entier ou même l'ensemble d'Internet comme une seule séquence.
À titre de comparaison, une personne moyenne peut lire 100 000 jetons en 5 heures environ et peut prendre plus de temps pour digérer, mémoriser et analyser ces informations. Claude peut le faire en moins d'une minute. S’il était converti en cette recherche par Microsoft, ce serait un nombre stupéfiant.
 Photos
Photos
- Adresse papier : https://arxiv.org/pdf/2307.02486.pdf
- Adresse du projet : https://github.com/microsoft/unilm/tree/master
Plus précisément, la recherche propose LONGNET, une variante de Transformer qui peut étendre la longueur des séquences à plus d'un milliard de jetons sans sacrifier les performances sur des séquences plus courtes. L'article propose également une attention dilatée, qui peut élargir de manière exponentielle la plage de perception du modèle.
LONGNET présente les avantages suivants :
1) Il a une complexité de calcul linéaire
2) Il peut être utilisé comme entraîneur distribué pour des séquences plus longues
3) l'attention dilatée peut être ; utilisé sans Seam remplace l'attention standard et peut être intégré de manière transparente aux méthodes d'optimisation existantes basées sur Transformer.
Les résultats expérimentaux montrent que LONGNET présente de solides performances à la fois dans la modélisation de séquences longues et dans les tâches de langage général.
En termes de motivation de la recherche, l'article indique qu'au cours des dernières années, l'extension des réseaux de neurones est devenue une tendance et que de nombreux réseaux performants ont été étudiés. Parmi eux, la longueur de la séquence, en tant que partie du réseau neuronal, devrait idéalement être infinie. Mais la réalité est souvent inverse, donc dépasser la limite de longueur de séquence apportera des avantages significatifs :
- Premièrement, cela fournit au modèle une mémoire et un champ récepteur de grande capacité, lui permettant de communiquer efficacement avec les humains et les monde.
- Deuxièmement, un contexte plus long contient des relations causales et des chemins de raisonnement plus complexes que le modèle peut exploiter dans les données d'entraînement. Au contraire, des dépendances plus courtes introduiront des corrélations plus parasites, ce qui ne favorise pas la généralisation du modèle.
- Troisièmement, une séquence plus longue peut aider le modèle à explorer des contextes plus longs, et des contextes extrêmement longs peuvent également aider le modèle à atténuer le problème catastrophique de l'oubli.
Cependant, le principal défi dans l'extension de la longueur des séquences est de trouver le bon équilibre entre la complexité informatique et la puissance d'expression du modèle.
Par exemple, les modèles de style RNN sont principalement utilisés pour augmenter la longueur des séquences. Cependant, sa nature séquentielle limite la parallélisation lors de l’entraînement, ce qui est crucial dans la modélisation de séquences longues.
Récemment, les modèles spatiaux d'états sont devenus très attrayants pour la modélisation de séquences, qui peuvent être exécutés comme un CNN pendant la formation et convertis en un RNN efficace au moment du test. Cependant, ce type de modèle ne fonctionne pas aussi bien que Transformer aux longueurs régulières.
Une autre façon d'étendre la longueur de la séquence est de réduire la complexité du Transformateur, c'est-à-dire la complexité quadratique de l'attention personnelle. À ce stade, certaines variantes efficaces basées sur Transformer ont été proposées, notamment l'attention de bas rang, les méthodes basées sur le noyau, les méthodes de sous-échantillonnage et les méthodes basées sur la récupération. Cependant, ces approches n'ont pas encore étendu Transformer à l'échelle d'un milliard de jetons (voir Figure 1).
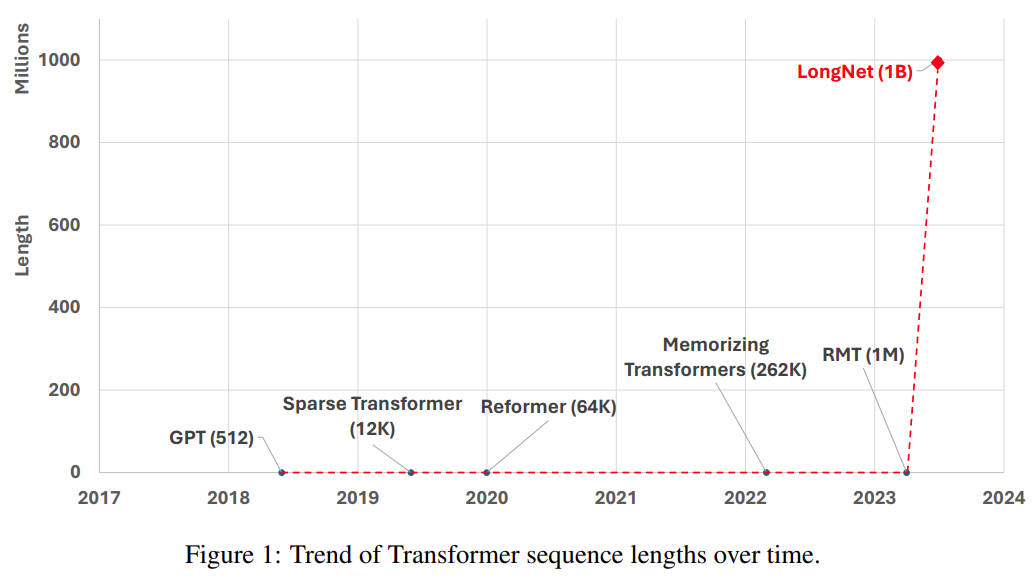 Photos
Photos
Le tableau suivant montre la comparaison de la complexité informatique de différentes méthodes de calcul. N est la longueur de la séquence et d est la dimension cachée.
 photos
photos
Méthode
La solution de recherche LONGNET a réussi à étendre la longueur de la séquence à 1 milliard de jetons. Plus précisément, cette recherche propose un nouveau composant appelé attention dilatée et remplace le mécanisme d'attention de Vanilla Transformer par une attention dilatée. Un principe général de conception est que l’allocation de l’attention diminue de façon exponentielle à mesure que la distance entre les jetons augmente. L'étude montre que cette approche de conception obtient une complexité de calcul linéaire et une dépendance logarithmique entre les jetons. Cela résout le conflit entre les ressources d’attention limitées et l’accès à chaque jeton.
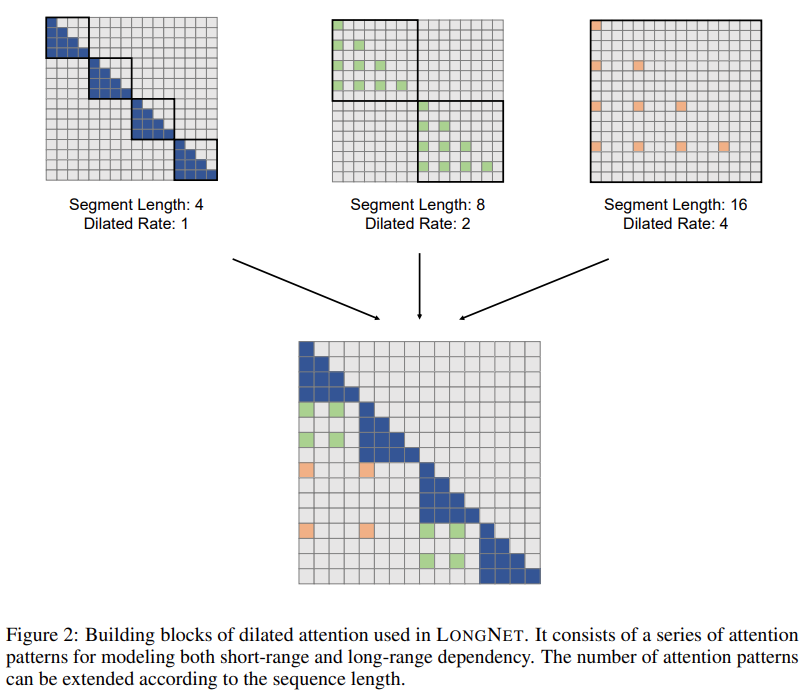 Pictures
Pictures
Pendant la mise en œuvre, LONGNET peut être converti en un transformateur dense pour prendre en charge de manière transparente les méthodes d'optimisation existantes pour les transformateurs (telles que la fusion du noyau, la quantification et la formation distribuée). Tirant parti de la complexité linéaire, LONGNET peut être entraîné en parallèle sur plusieurs nœuds, en utilisant des algorithmes distribués pour briser les contraintes de calcul et de mémoire.
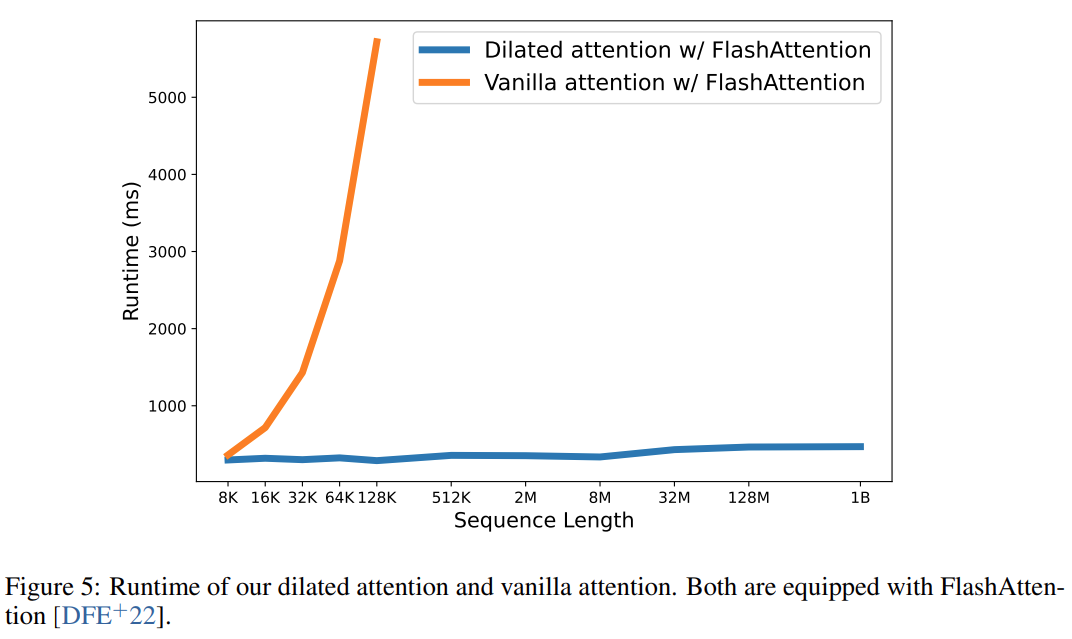
En fin de compte, cette recherche a effectivement étendu la longueur de la séquence à 1 milliard de jetons, et la durée d'exécution était presque constante, comme le montre la figure ci-dessous. En revanche, le temps d'exécution du Transformer Vanilla souffre d'une complexité quadratique.
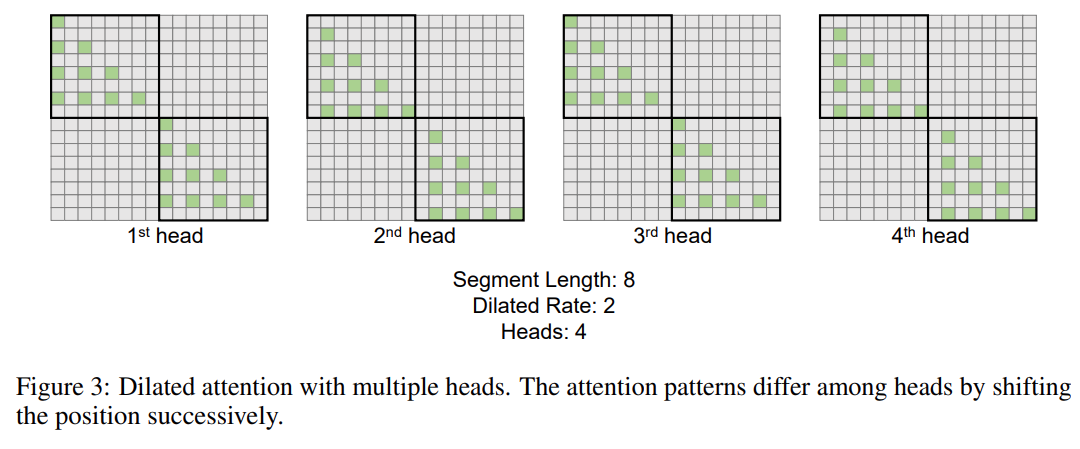
Cette recherche introduit en outre le mécanisme d'attention dilatée à plusieurs têtes. Comme le montre la figure 3 ci-dessous, cette étude effectue différents calculs sur différentes têtes en fragmentant différentes parties des paires requête-clé-valeur.
 Photos
Photos
Formation distribuée
Bien que la complexité informatique de l'attention dilatée ait été considérablement réduite à 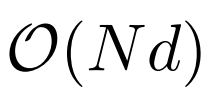 , en raison des limitations de l'informatique et de la mémoire, elle adaptera la longueur de la séquence à des millions n’est pas réalisable. Il existe certains algorithmes de formation distribués pour la formation de modèles à grande échelle, tels que le parallélisme de modèles [SPP+19], le parallélisme de séquences [LXLY21, KCL+22] et le parallélisme de pipeline [HCB+19]. , surtout lorsque la dimension de la séquence est très grande.
, en raison des limitations de l'informatique et de la mémoire, elle adaptera la longueur de la séquence à des millions n’est pas réalisable. Il existe certains algorithmes de formation distribués pour la formation de modèles à grande échelle, tels que le parallélisme de modèles [SPP+19], le parallélisme de séquences [LXLY21, KCL+22] et le parallélisme de pipeline [HCB+19]. , surtout lorsque la dimension de la séquence est très grande.
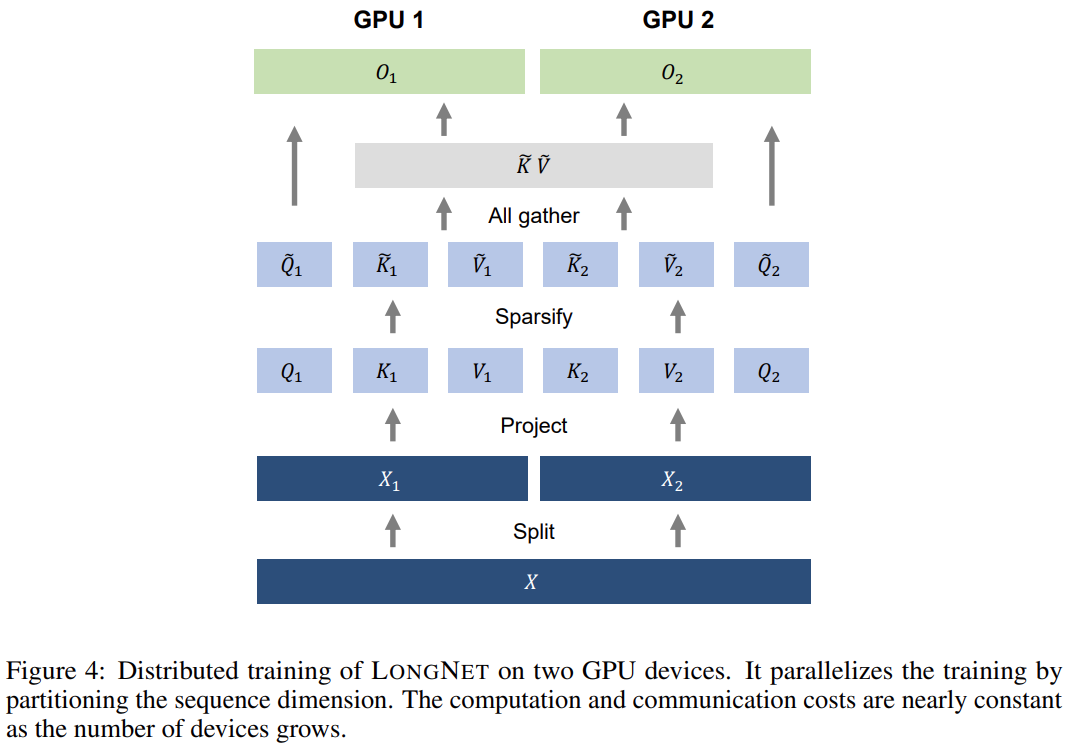
Cette recherche utilise la complexité informatique linéaire de LONGNET pour la formation distribuée des dimensions de séquence. La figure 4 ci-dessous montre l'algorithme distribué sur deux GPU, qui peut être étendu à n'importe quel nombre d'appareils.
Expériences
L'étude a comparé LONGNET avec Vanilla Transformer et Sparse Transformer. La différence entre les architectures réside dans la couche d’attention, tandis que les autres couches restent les mêmes. Les chercheurs ont étendu la longueur de séquence de ces modèles de 2K à 32K, tout en réduisant la taille des lots pour garantir que le nombre de jetons dans chaque lot reste inchangé.
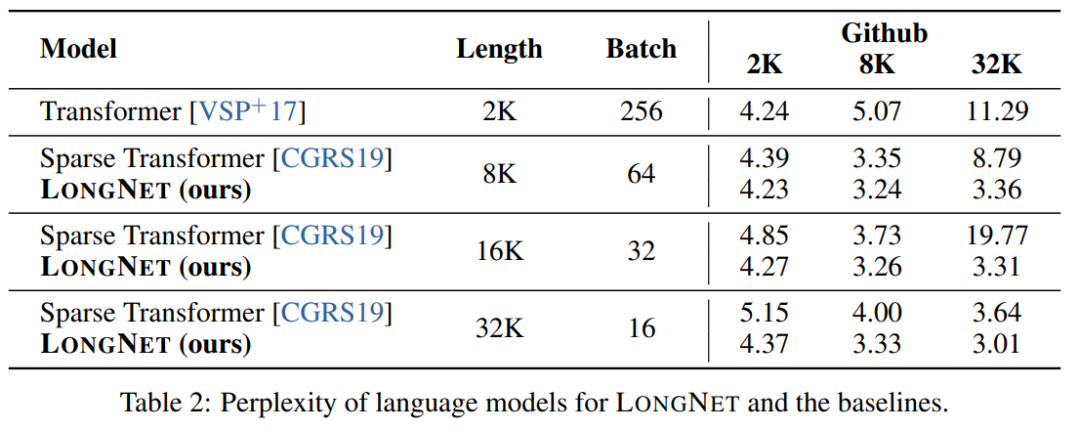
Le Tableau 2 résume les résultats de ces modèles sur l'ensemble de données Stack. La recherche utilise la complexité comme mesure d’évaluation. Les modèles ont été testés en utilisant différentes longueurs de séquence, allant de 2k à 32k. Lorsque la longueur d'entrée dépasse la longueur maximale prise en charge par le modèle, la recherche met en œuvre une attention causale par blocs (BCA) [SDP+22], une méthode d'extrapolation de pointe pour l'inférence de modèle de langage.
De plus, l'étude a supprimé le codage de position absolue. Premièrement, les résultats montrent que l’augmentation de la longueur des séquences au cours de la formation aboutit généralement à de meilleurs modèles de langage. Deuxièmement, la méthode d’extrapolation de la longueur de séquence dans l’inférence ne s’applique pas lorsque la longueur est beaucoup plus grande que celle prise en charge par le modèle. Enfin, LONGNET surpasse systématiquement les modèles de base, démontrant son efficacité dans la modélisation du langage.
Courbe d'expansion de la longueur de la séquence
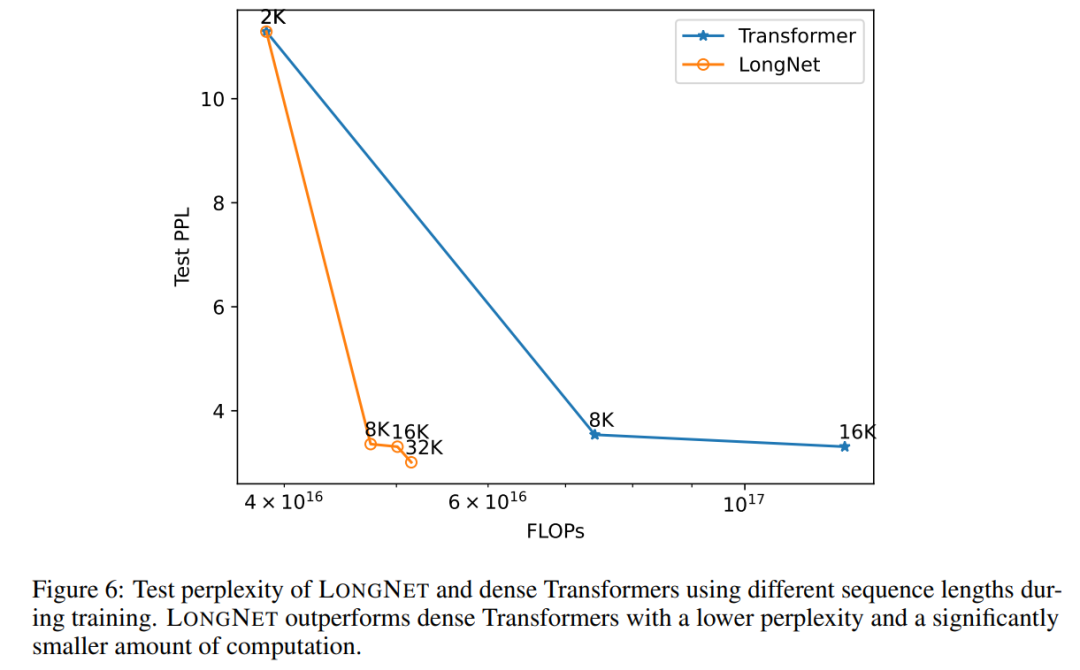
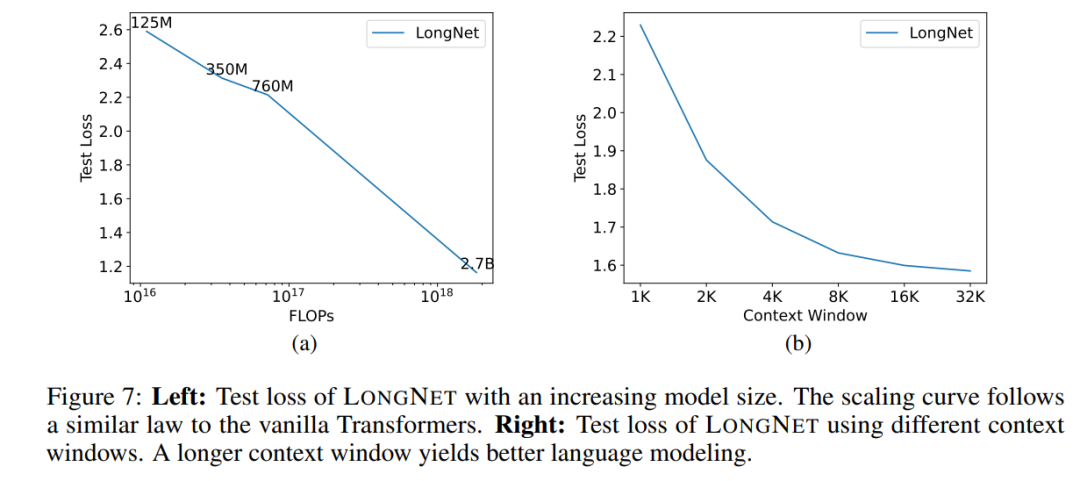
La figure 6 trace les courbes d'expansion de la longueur de séquence du transformateur vanille et de LONGNET. Cette étude estime l'effort de calcul en comptant le total des échecs des multiplications matricielles. Les résultats montrent que Vanilla Transformer et LONGNET atteignent des longueurs de contexte plus grandes grâce à la formation. Cependant, LONGNET peut étendre la longueur du contexte plus efficacement, réduisant ainsi les pertes de test avec moins de calculs. Cela démontre l’avantage d’intrants de formation plus longs par rapport à l’extrapolation. Les expériences montrent que LONGNET est un moyen plus efficace d'étendre la longueur du contexte dans les modèles de langage. En effet, LONGNET peut apprendre plus efficacement des dépendances plus longues. Une propriété importante des grands modèles de langage est que la perte augmente dans une loi de puissance à mesure que la quantité de calcul augmente. Pour vérifier si LONGNET suit toujours des règles de mise à l'échelle similaires, l'étude a formé une série de modèles avec différentes tailles (de 125 millions à 2,7 milliards de paramètres). 2,7 milliards de modèles ont été formés avec 300 milliards de jetons, tandis que les modèles restants ont utilisé environ 400 milliards de jetons. La figure 7 (a) représente la courbe d'échelle de LONGNET par rapport au calcul. L'étude a calculé la complexité sur le même ensemble de tests. Cela prouve que LONGNET peut toujours suivre une loi de puissance. Cela signifie également que Transformer dense n'est pas une condition préalable à l'extension des modèles de langage. De plus, l'évolutivité et l'efficacité sont gagnées avec LONGNET.
Invite contextuelle longue
L'invite est un moyen important de guider le modèle de langage et de lui fournir des informations supplémentaires. Cette étude valide expérimentalement si LONGNET peut bénéficier de fenêtres d'indication de contexte plus longues.Cette étude a retenu un préfixe (préfixes) comme invite et a testé la perplexité de ses suffixes (suffixes). De plus, au cours du processus de recherche, l’invite a été progressivement étendue de 2K à 32K. Pour faire une comparaison équitable, la longueur du suffixe est maintenue constante tandis que la longueur du préfixe est augmentée jusqu'à la longueur maximale du modèle. La figure 7 (b) rapporte les résultats sur l'ensemble de test. Cela montre que la perte de test de LONGNET diminue progressivement à mesure que la fenêtre de contexte augmente. Cela prouve la supériorité de LONGNET dans l'utilisation complète du contexte long pour améliorer les modèles de langage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI