
Maison >Périphériques technologiques >IA >Le coût de formation des grands modèles a été réduit de près de moitié ! Le dernier optimiseur de l'Université nationale de Singapour a été mis en service
Le coût de formation des grands modèles a été réduit de près de moitié ! Le dernier optimiseur de l'Université nationale de Singapour a été mis en service

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-17 22:13:171331parcourir
L'optimiseur occupe une grande quantité de ressources mémoire dans la formation de grands modèles de langage.
Il existe désormais une nouvelle méthode d'optimisation qui réduit de moitié la consommation de mémoire tout en conservant les mêmes performances.
Ce résultat a été créé par l'Université nationale de Singapour. Il a remporté le prix Outstanding Paper Award lors de la conférence ACL et a été mis en application pratique.
 Images
Images
Avec le nombre croissant de paramètres des grands modèles de langage, le problème de consommation de mémoire pendant l'entraînement devient plus grave.
L'équipe de recherche a proposé l'optimiseur CAME, qui a les mêmes performances qu'Adam tout en réduisant la consommation de mémoire.
 Photos
Photos
L'optimiseur CAME a atteint des performances de formation identiques, voire supérieures, à celles de l'optimiseur Adam dans la pré-formation de plusieurs modèles de langage à grande échelle couramment utilisés, et montre une plus grande robustesse aux scénarios de pré-formation par lots importants sexe.
De plus, la formation de grands modèles de langage via l'optimiseur CAME peut réduire considérablement le coût de la formation de grands modèles.
Méthode de mise en œuvre
L'optimiseur CAME est amélioré sur la base de l'optimiseur Adafactor, ce qui entraîne souvent une perte de performances d'entraînement dans les tâches de pré-entraînement des modèles de langage à grande échelle.
L'opération de factorisation matricielle non négative dans Adafactor produira inévitablement des erreurs dans la formation des réseaux de neurones profonds, et la correction de ces erreurs est à l'origine de pertes de performances.
Et par comparaison, on constate que lorsque la différence entre la valeur de départ mt et la valeur actuelle t est faible, la confiance de mt est plus élevée.
 Picture
Picture
Inspirée par cela, l'équipe a proposé un nouvel algorithme d'optimisation.
La partie bleue dans l'image ci-dessous est la partie augmentée de CAME par rapport à Adafactor.
 Picture
Picture
L'optimiseur CAME effectue une correction du montant de la mise à jour en fonction de la confiance de la mise à jour du modèle, et effectue en même temps une opération de décomposition matricielle non négative sur la matrice de confiance introduite.
Au final, CAME a réussi à obtenir l'effet d'Adam avec la consommation d'Adafactor.
Le même effet ne consomme que la moitié des ressources
L'équipe a utilisé CAME pour former respectivement les modèles BERT, GPT-2 et T5.
Les Adam (meilleur effet) et Adafactor (consommation plus faible) précédemment couramment utilisés sont les références pour mesurer les performances du CAME.
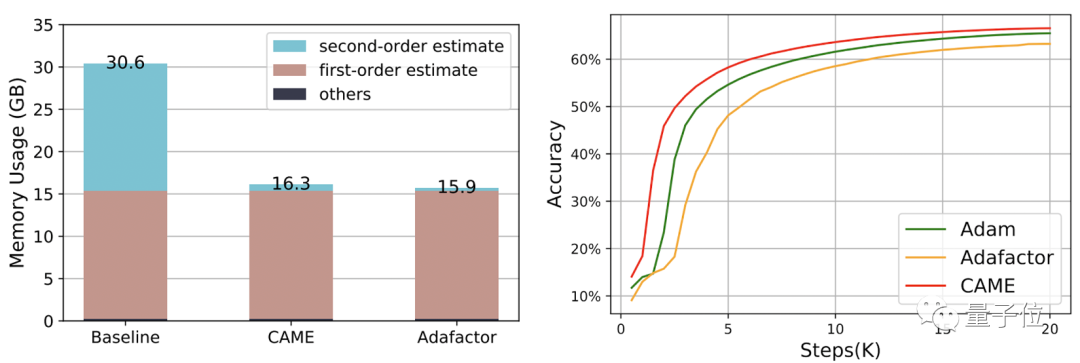
Parmi eux, lors du processus de formation BERT, CAME a atteint la même précision qu'Adafaactor en seulement deux fois moins d'étapes.
 △Le côté gauche est à l'échelle 8K, le côté droit est à l'échelle 32K
△Le côté gauche est à l'échelle 8K, le côté droit est à l'échelle 32K
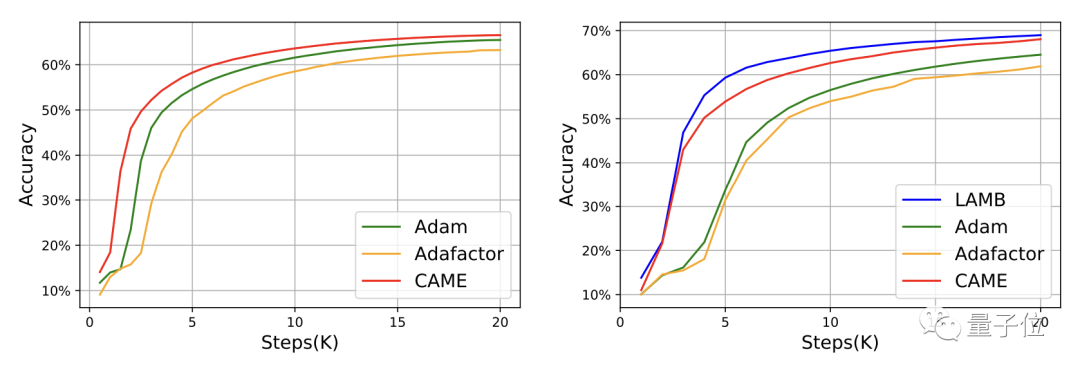
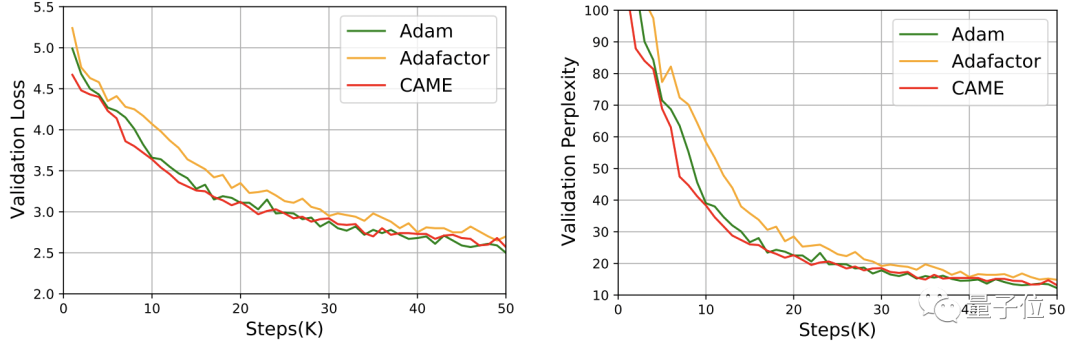
Pour GPT-2, du point de vue de la perte et de la confusion, les performances de CAME sont très proches de celles d'Adam.

Dans la formation du modèle T5, CAME a également montré des résultats similaires.
Quant à la mise au point du modèle, les performances de CAME en termes de précision ne sont pas inférieures à la référence.
En termes de consommation de ressources, lors de l'utilisation de PyTorch pour entraîner BERT avec un volume de données de 4 B, CAME consomme près de la moitié des ressources mémoire par rapport à la ligne de base.
Profil de l'équipe
Le laboratoire HPC-AI de l'Université nationale de Singapour est un laboratoire de calcul haute performance et d'intelligence artificielle dirigé par le professeur You Yang.
Le laboratoire s'engage dans la recherche et l'innovation dans le domaine du calcul haute performance, des systèmes d'apprentissage automatique et du calcul parallèle distribué, et promeut des applications dans des domaines tels que les modèles de langage à grande échelle.
Le chef du laboratoire, You Yang, est le President Young Professor(Presidential Young Professor) du Département d'informatique de l'Université nationale de Singapour.
You Yang a été sélectionné dans la liste Forbes Under 30 Elite (Asie) en 2021 et a remporté le prix IEEE-CS Supercomputing Outstanding Newcomer Award. Ses recherches actuelles portent sur l'optimisation distribuée des algorithmes de formation en apprentissage profond à grande échelle.
Luo Yang, le premier auteur de cet article, est étudiant en master en laboratoire. Ses recherches actuelles portent sur la stabilité et l'efficacité de l'entraînement des grands modèles.
Adresse papier : https://arxiv.org/abs/2307.02047
Page du projet GitHub : https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI