
Maison >Périphériques technologiques >IA >GPT-4 utilise des grands modèles hybrides ? La recherche prouve que le réglage des instructions MoE+ améliore effectivement les performances des grands modèles
GPT-4 utilise des grands modèles hybrides ? La recherche prouve que le réglage des instructions MoE+ améliore effectivement les performances des grands modèles

- 王林avant
- 2023-07-17 16:57:251517parcourir
Depuis l'avènement de GPT-4, les gens ont été étonnés par ses puissantes capacités d'émergence, notamment d'excellentes capacités de compréhension du langage, de génération, de raisonnement logique, etc. Ces capacités font de GPT-4 l’un des modèles les plus avancés en matière d’apprentissage automatique. Cependant, OpenAI n’a jusqu’à présent divulgué aucun détail technique de GPT-4.
Le mois dernier, George Hotz a mentionné GPT-4 dans une interview avec un podcast sur la technologie de l'IA appelé Latent Space, affirmant que GPT-4 est en fait un modèle hybride. Plus précisément, George Hotez a déclaré que GPT-4 utilise un système intégré composé de 8 modèles experts, chacun comportant 220 milliards de paramètres (un peu plus que les 175 milliards de paramètres de GPT-3), et que ces modèles sont formés sur différentes données et tâches. distributions.

Interview de Latent Space.
Ce n'est peut-être qu'une spéculation de George Hotz, mais ce modèle a une certaine légitimité. Récemment, un article publié conjointement par des chercheurs de Google, de l'UC Berkeley, du MIT et d'autres institutions a confirmé que la combinaison d'un modèle expert hybride (MoE) et du réglage des instructions peut améliorer considérablement les performances des grands modèles de langage (LLM).
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2305.14705.pdf
Le modèle expert mixte clairsemé est une architecture de réseau neuronal spéciale qui peut réduire les coûts d'inférence sans augmenter le coût Dans ce cas, ajoutez des paramètres apprenables pour les grands modèles de langage (LLM). Le réglage des instructions est une technique permettant de former LLM à suivre les instructions. L'étude a révélé que les modèles MoE bénéficiaient davantage du réglage des instructions que les modèles denses, et a donc proposé de combiner MoE et le réglage des instructions.
L'étude a été menée empiriquement dans trois contextes expérimentaux, notamment
- ajustement direct sur une seule tâche en aval sans réglage des instructions
- tâche en aval après le réglage des instructions Effectuer quelques plans ou en contexte ; généralisation sans tir ; affiner davantage les tâches individuelles en aval après le réglage des instructions
- .
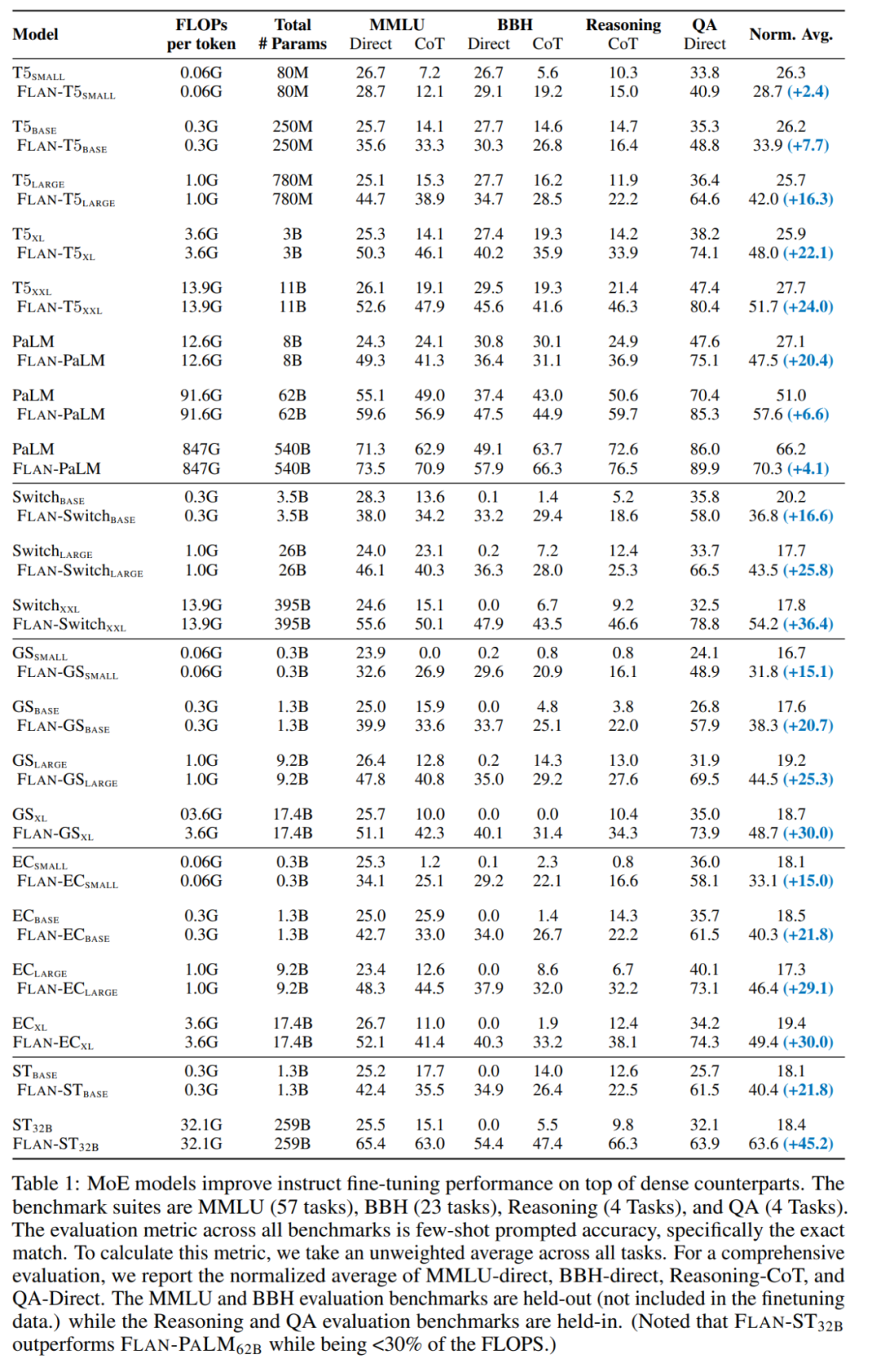
Dans le premier cas, les modèles MoE sont généralement inférieurs aux modèles denses ayant la même puissance de calcul. Cependant, avec l'introduction du réglage des instructions (les deuxième et troisième cas), FLAN-MoE_32B (Fine-tuned LANguage Net, en abrégé Flan) est un modèle optimisé par les instructions, et Flan-MoE est le modèle de réglage des instructions Excellent. surpasse FLAN-PALM_62B sur quatre tâches de référence, mais n'utilise qu'un tiers des FLOP.
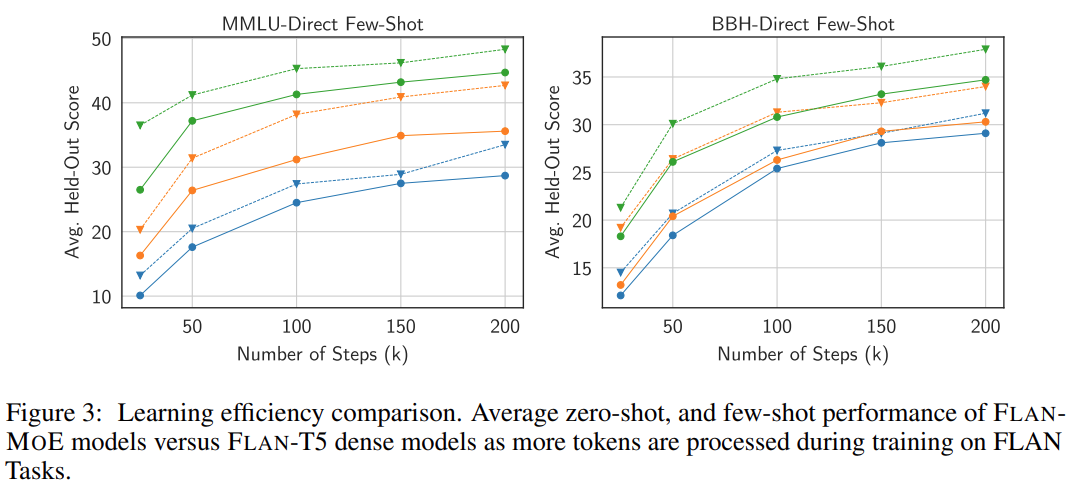
Comme le montre la figure ci-dessous, avant d'utiliser le réglage des instructions, MoE → FT n'est pas aussi bon que T5 → FT. Après réglage des instructions, Flan-MoE → FT surpasse Flan-T5 → FT. Le bénéfice du MoE du réglage des instructions (+15,6) est supérieur à celui du modèle dense (+10,2) :
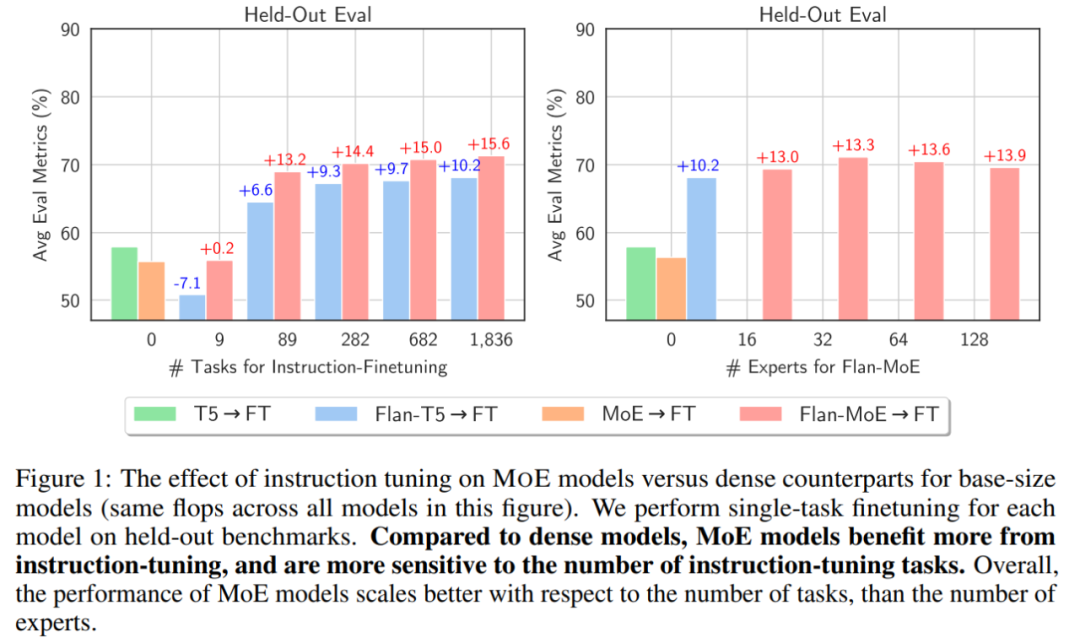 Photo
Photo
Il semble que GPT-4 ait une certaine base pour adopter un modèle hybride. Bénéficiez du réglage des instructions. Obtenez de plus grands avantages grâce aux meilleurs :
 Photos
Photos
Aperçu de la méthode
Les chercheurs ont utilisé le MoE d'activation clairsemé dans le FLAN-MOE (un ensemble de modèles experts mixtes clairsemés et affinés). avec instructions) modèle (mélange d'experts). De plus, ils ont remplacé les composants de rétroaction des autres couches Transformer par des couches MoE.
Chaque couche MoE peut être comprise comme un "expert". Ensuite, ces experts sont modélisés à l'aide de la fonction d'activation softmax pour obtenir une distribution de probabilité.
Bien que chaque couche MoE ait de nombreux paramètres, les experts sont peu activés. Cela signifie que pour un jeton d’entrée donné, seul un sous-ensemble limité d’experts peut accomplir la tâche, offrant ainsi une plus grande capacité au modèle.
Pour une couche MoE avec des experts E, cela fournit effectivement O (E^2) différentes combinaisons de réseaux de rétroaction, permettant une plus grande flexibilité de calcul.
Étant donné que FLAN-MoE est un modèle adapté aux instructions, le réglage des instructions est très important. Cette étude a affiné FLAN-MOE sur la base de l'ensemble de données collectives FLAN. De plus, cette étude a ajusté la longueur de la séquence d'entrée de chaque FLAN-MOE à 2048 et la longueur de sortie à 512.
Expériences et analyses
En moyenne, Flan-MoE surpasse son homologue dense (Flan-T5) à toutes les échelles de modèle sans ajouter de calcul supplémentaire.
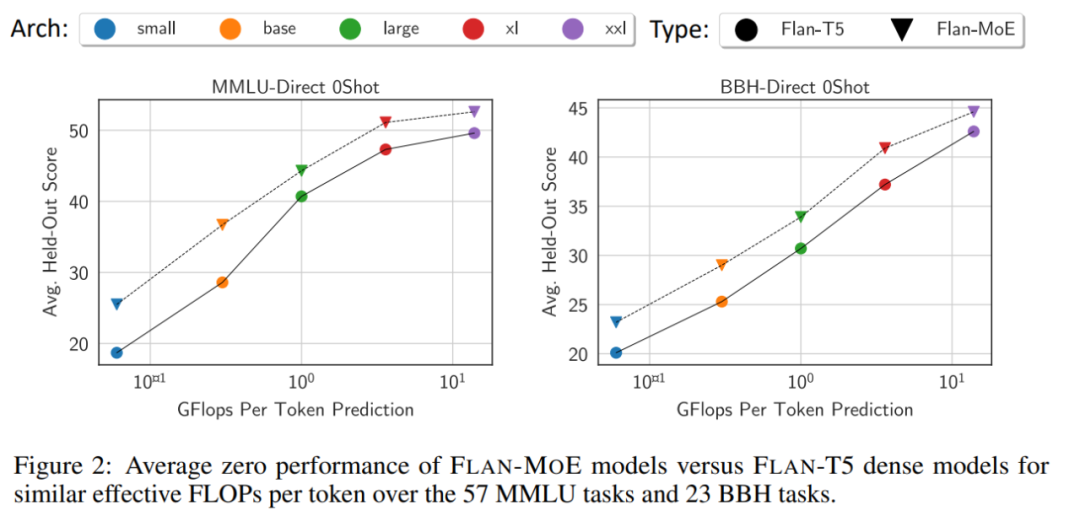 Photos
Photos
Nombre d'experts. La figure 4 montre qu'à mesure que le nombre d'experts augmente, le modèle bénéficie initialement d'un ensemble plus riche de sous-réseaux spécialisés, chacun capable de gérer une tâche ou un aspect différent dans l'espace du problème. Cette approche rend le MoE hautement adaptable et efficace dans la gestion de tâches complexes, améliorant ainsi les performances globales. Cependant, à mesure que le nombre d’experts continue d’augmenter, les gains de performances du modèle commencent à diminuer, pour finalement atteindre un point de saturation.
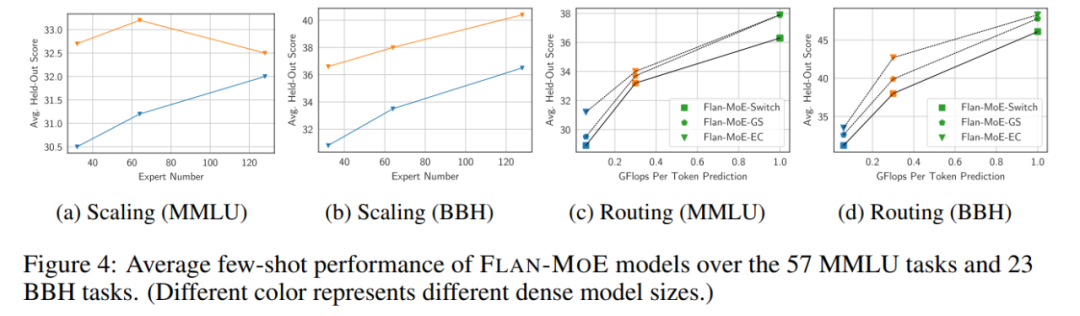 Photos
Photos
La figure 3 et le tableau 1 étudient en détail comment différentes décisions de routage affectent les performances de réglage des instructions : grâce à la comparaison entre les stratégies FLAN-Switch et FLAN-GS, on peut conclure que l'activation de davantage d'experts améliore les performances. à travers quatre critères. Parmi ces benchmarks, le modèle MMLU-Direct présente l'amélioration la plus significative, passant de 38,0 % à 39,9 % pour les modèles de taille BASE/LARGE.
Notamment, le réglage des instructions a considérablement amplifié les performances du modèle MoE en matière de préservation du MMLU, du BBH et des références internes d'assurance qualité et d'inférence par rapport aux modèles denses de capacité équivalente. Ces avantages sont encore amplifiés pour les modèles MoE plus grands. Par exemple, le réglage des instructions améliore les performances de 45,2 % pour ST_32B, alors que pour FLAN-PALM_62B, cette amélioration est relativement faible, à environ 6,6 %.
Lors des extensions de modèle, Flan-MoE (Flan-ST-32B) surpasse Flan-PaLM-62B.
 Photos
Photos
De plus, l'étude a mené des expériences analytiques en gelant la fonction de déclenchement, le module expert et les paramètres MoE du modèle donné. Comme le montre le tableau 2 ci-dessous, les résultats expérimentaux montrent que le gel du module expert ou du composant MoE a un impact négatif sur les performances du modèle.
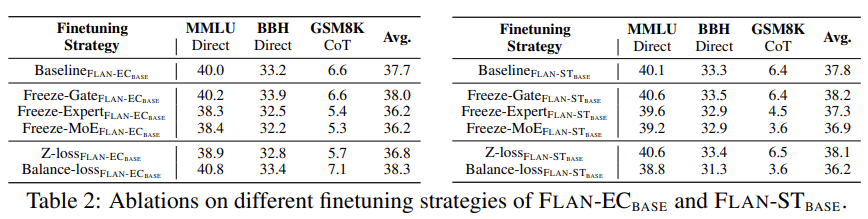
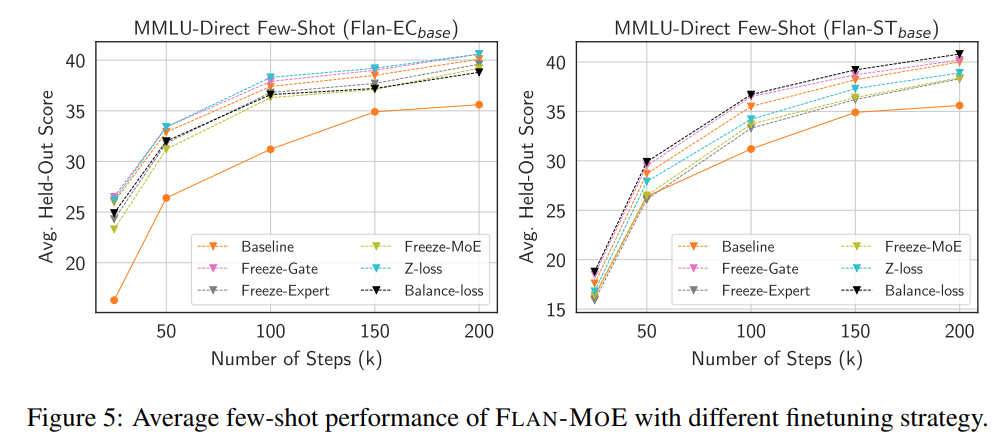
En revanche, la fonction freeze gating améliorera légèrement les performances du modèle, même si ce n'est pas évident. Les chercheurs supposent que cette observation est liée au sous-ajustement du FLAN-MOE. L’étude a également mené des expériences d’ablation pour explorer l’étude d’ablation sur l’efficacité des données décrite dans la figure 5 ci-dessous.
Enfin, afin de comparer l'écart entre le réglage fin direct du MoE et le FLAN-MOE, cette étude a mené des expériences sur le réglage fin du MoE à une seule tâche, le réglage précis du FLAN-MoE à une seule tâche et modèles denses. Les résultats sont les suivants Comme le montre la figure 6 :
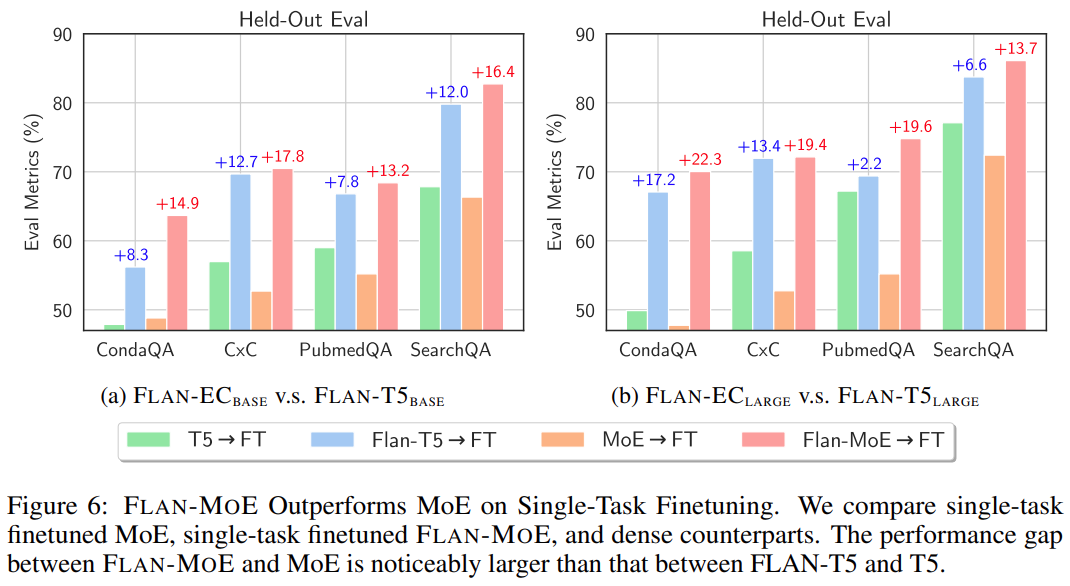
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI