
Maison >Périphériques technologiques >IA >Fuite de l'architecture du modèle GPT-4 : contient 1 800 milliards de paramètres et utilise un modèle expert hybride
Fuite de l'architecture du modèle GPT-4 : contient 1 800 milliards de paramètres et utilise un modèle expert hybride

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-16 11:53:22870parcourir

Selon les informations du 13 juillet, les médias étrangers Semianalysis ont récemment révélé le grand modèle GPT-4 publié par OpenAI en mars de cette année, y compris l'architecture du modèle GPT-4, l'infrastructure de formation et d'inférence, le volume des paramètres et les données de formation. ensemble, nombre de jetons, coût, mélange d'experts et autres paramètres et informations spécifiques.
▲ Source de l'image Semianalysis
Les médias étrangers ont déclaré que GPT-4 contient un total de 1,8 billion de paramètres dans 120 couches, tandis que GPT-3 ne contient qu'environ 175 milliards de paramètres. Afin de maintenir des coûts raisonnables, OpenAI utilise un modèle expert hybride pour construire.
IT Home Remarque : Le mélange d'experts est une sorte de réseau neuronal. Le système sépare et entraîne plusieurs modèles en fonction des données. Après la sortie de chaque modèle, le système intègre et génère ces modèles en une seule tâche.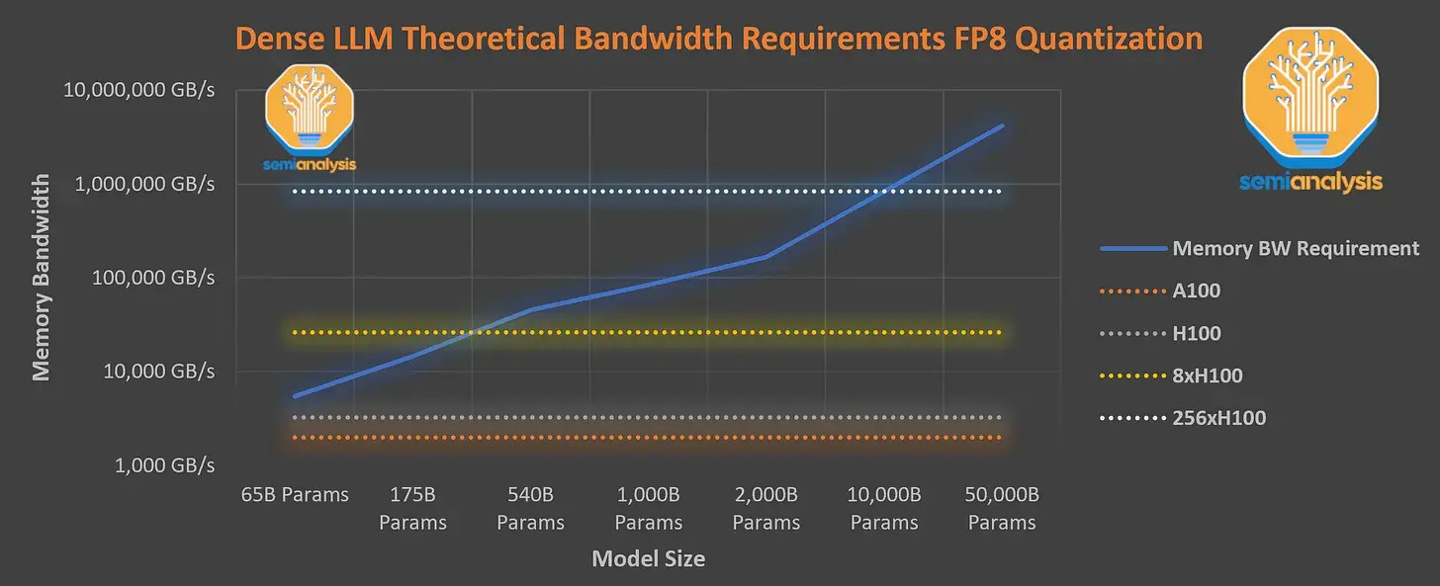
GPT-4 utilise 16 modèles experts mixtes (mélange d'experts), chacun avec 111 milliards de paramètres, et chaque itinéraire de passage avant passe par deux modèles experts .
De plus, il dispose de 55 milliards de paramètres d'attention partagés et a été formé à l'aide d'un ensemble de données contenant 13 000 milliards de jetons. Les jetons ne sont pas uniques et comptent comme davantage de jetons en fonction du nombre d'itérations. La longueur du contexte de l'étape de pré-formation GPT-4 est de 8k, et la version 32k est le résultat d'un réglage fin de 8k. Les médias étrangers ont déclaré que8x H100 ne peuvent pas fournir la densité requise à un moment donné. vitesse de 33,33 jetons par seconde. Modèle paramétrique, donc la formation de ce modèle nécessite des coûts d'inférence extrêmement élevés, calculés à 1 $ US par heure pour la machine physique H100, le coût d'une formation s'élève à 63 millions de dollars US (environ 451 millions de yuans). ).
À cet égard,OpenAI a choisi d'utiliser le GPU A100 dans le cloud pour entraîner le modèle, réduisant ainsi le coût final de formation à environ 21,5 millions de dollars américains (environ 154 millions de yuans), ce qui a pris un peu plus de temps pour réduire le coût de formation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI