
Maison >Périphériques technologiques >IA >Le talent visuel des grands modèles de langage : GPT peut également résoudre des tâches visuelles grâce à l'apprentissage contextuel
Le talent visuel des grands modèles de langage : GPT peut également résoudre des tâches visuelles grâce à l'apprentissage contextuel

- 王林avant
- 2023-07-14 15:37:061644parcourir
Actuellement, les grands modèles de langage (LLM) ont déclenché une vague de changements dans le domaine du traitement du langage naturel (NLP). Nous constatons que LLM a de fortes capacités d’émergence et fonctionne bien sur des tâches complexes de compréhension du langage, des tâches de génération et même des tâches de raisonnement. Cela incite les gens à explorer davantage le potentiel du LLM dans un autre sous-domaine de l'apprentissage automatique : la vision par ordinateur (CV).
L'un des grands talents des LLM est leur capacité à apprendre en contexte. L'apprentissage contextuel ne met à jour aucun paramètre du LLM, mais il montre des résultats étonnants dans diverses tâches de PNL. Alors, GPT peut-il résoudre des tâches visuelles grâce à l’apprentissage contextuel ?
Récemment, des chercheurs de Google et de l'Université Carnegie Mellon (CMU) ont publié conjointement un article montrant que tant que nous pouvons convertir des images (ou d'autres modalités non linguistiques) dans un langage que LLM peut comprendre, cela semble réalisable.
 Pictures
Pictures
Adresse du papier : https://arxiv.org/abs/2306.17842
Cet article révèle la capacité de PaLM ou GPT à résoudre des tâches visuelles grâce à l'apprentissage contextuel et propose une nouvelle méthode SPAE ( AutoEncoder de pyramide sémantique). Cette nouvelle approche permet à LLM d'effectuer des tâches de génération d'images sans aucune mise à jour des paramètres. Il s'agit également de la première méthode réussie à utiliser l'apprentissage contextuel pour permettre à LLM de générer du contenu d'image.
Jetons d'abord un coup d'œil aux résultats expérimentaux du LLM dans la génération de contenu d'image grâce à l'apprentissage contextuel.
Par exemple, en fournissant 50 images d'écriture manuscrite dans un contexte donné, l'article demande à PaLM 2 de répondre à des requêtes complexes qui nécessitent de générer des images numériques en sortie : Générer des images réalistes et réelles sans saisie :
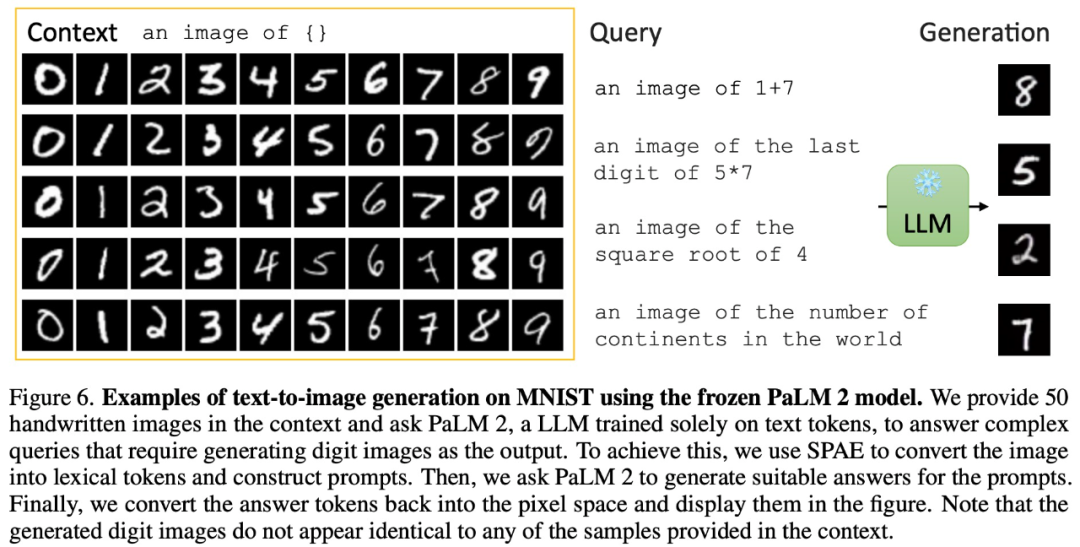 images
images
En plus de générer des images, grâce à l'apprentissage contextuel, PaLM 2 peut également effectuer une description d'image :

Images
peuvent même être débruité pour générer des vidéos :
 Pictures
Pictures
Présentation de la méthode
 En fait, convertir des images dans un langage que LLM peut comprendre est un problème qui a été étudié dans l'article Visual Transformer (ViT). . Dans cet article de Google et de la CMU, ils passent au niveau supérieur : en utilisant de vrais mots pour représenter des images.
En fait, convertir des images dans un langage que LLM peut comprendre est un problème qui a été étudié dans l'article Visual Transformer (ViT). . Dans cet article de Google et de la CMU, ils passent au niveau supérieur : en utilisant de vrais mots pour représenter des images.
Cette approche revient à construire une tour remplie de texte, capturant la sémantique et les détails de l'image. Cette représentation remplie de texte permet de générer facilement des descriptions d'images et permet aux LLM de répondre aux questions liées aux images et même de reconstruire les pixels de l'image.
Plus précisément, cette recherche propose d'utiliser un encodeur entraîné et un modèle CLIP pour convertir l'image en un espace de jeton ; puis d'utiliser LLM pour générer des jetons lexicaux appropriés et enfin d'utiliser un décodeur entraîné pour convertir ces jetons ; reconverti en espace de pixels. Ce processus ingénieux convertit les images dans un langage que LLM peut comprendre, nous permettant d'exploiter la puissance générative de LLM dans les tâches de vision.
Expériences et résultats
Cette étude a comparé expérimentalement SPAE aux méthodes SOTA Frozen et LQAE, et les résultats sont présentés dans le tableau 1 ci-dessous. SPAEGPT surpasse LQAE sur toutes les tâches tout en utilisant seulement 2 % des jetons.
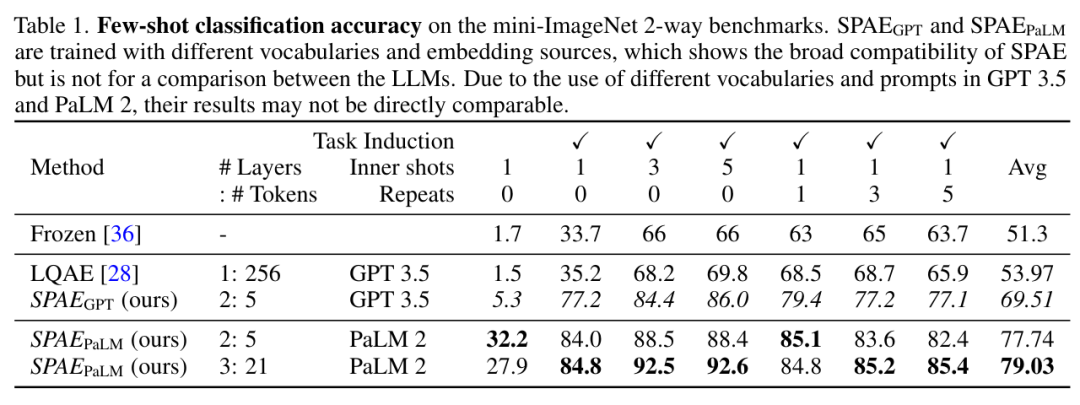 Pictures
Pictures
Globalement, les tests sur le benchmark mini-ImageNet montrent que la méthode SPAE améliore les performances de 25% par rapport à la méthode SOTA précédente.
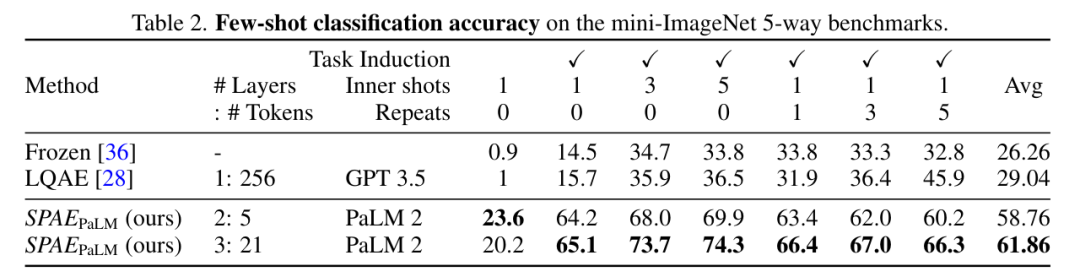 Photos
Photos
Afin de vérifier l'efficacité de la méthode de conception SPAE, cette étude a mené une expérience d'ablation, et les résultats expérimentaux sont présentés dans le tableau 4 et la figure 10 ci-dessous :
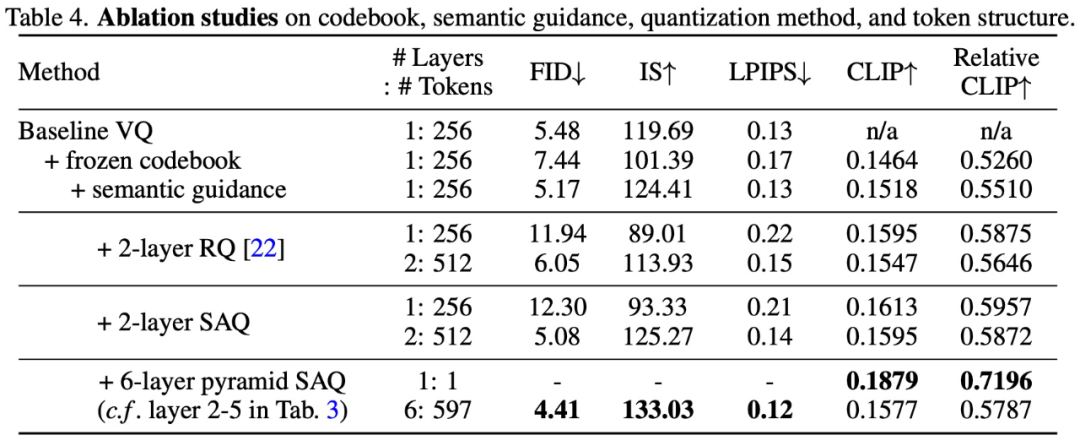 Photos
Photos
 Photos
Photos
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI