
Maison >Périphériques technologiques >IA >Analyse complète des données en une phrase, le nouvel assistant de données pour grands modèles de l'Université du Zhejiang élimine le besoin de collecte
Analyse complète des données en une phrase, le nouvel assistant de données pour grands modèles de l'Université du Zhejiang élimine le besoin de collecte

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-13 22:01:051456parcourir
Pour traiter les données, cet seul outil d'IA suffit !
En vous appuyant sur le grand modèle de langage (LLM) qui se cache derrière, il vous suffit de décrireles données que vous souhaitez voir en une phrase, et de lui laisser le reste !
Le traitement, l'analyse et même la visualisation peuvent être effectués facilement, Vous n'avez même pas besoin de faire la collecte vous-même.
 Pictures
Pictures
Cet assistant de données d'IA basé sur LLM s'appelle Data-Copilot et a été développé par l'équipe de l'Université du Zhejiang.
La prépublication de l'article concerné a été publiée.
Le contenu suivant est fourni par le contributeur
Divers secteurs tels que la finance, la météorologie et l'énergie génèrent chaque jour une grande quantité de données hétérogènes. Il existe un besoin urgent d’un outil permettant de gérer, traiter et afficher efficacement ces données.
DataCopilot gère et traite de manière autonome des données massives en déployant de grands modèles de langage pour répondre aux divers besoins des utilisateurs en matière de requêtes, de calculs, de prédictions, de visualisation et autres.
Il vous suffit de saisir du texte pour indiquer à DataCopilot les données que vous souhaitez voir, sans opérations fastidieuses, Pas besoin d'écrire votre propre code, DataCopilot transforme de manière autonome les données d'origine en un résultat de visualisation qui répond au mieux à l'intention de l'utilisateur.
Afin de parvenir à un cadre universel couvrant diverses formes de tâches liées aux données, l'équipe de recherche a proposé Data-Copilot.
Ce modèle résout les problèmes de risque de fuite de données, de faible puissance de calcul et d'incapacité à gérer des tâches complexes causées par la simple utilisation de LLM.
 Photos
Photos
Lors de la réception de demandes complexes, Data-Copilot concevra et planifiera indépendamment des interfaces indépendantes pour construire un flux de travail répondant aux intentions de l'utilisateur.
Sans assistance humaine, il peut transformer habilement des données brutes provenant de différentes sources et dans différents formats en sortie humanisée telle que des graphiques, des tableaux et du texte.
 Photos
Photos
Les principales contributions du projet Data-Copilot incluent :
- Connecter des sources de données dans différents domaines et divers besoins des utilisateurs, réduisant ainsi le travail fastidieux et les connaissances professionnelles.
- Permet une gestion, un traitement, une analyse, une prédiction et une visualisation autonomes des données, et peut transformer les données brutes en résultats informatifs qui répondent au mieux aux intentions des utilisateurs. Les
- Tools ont la double identités de designer et scheduler, comprenant deux processus : le processus de conception de l'outil d'interface (designer) et le processus de planification (scheduler).
- Data-Copilot Demo est construit sur la base des données du marché financier chinois.
Concevez et exécutez le workflow de manière indépendante
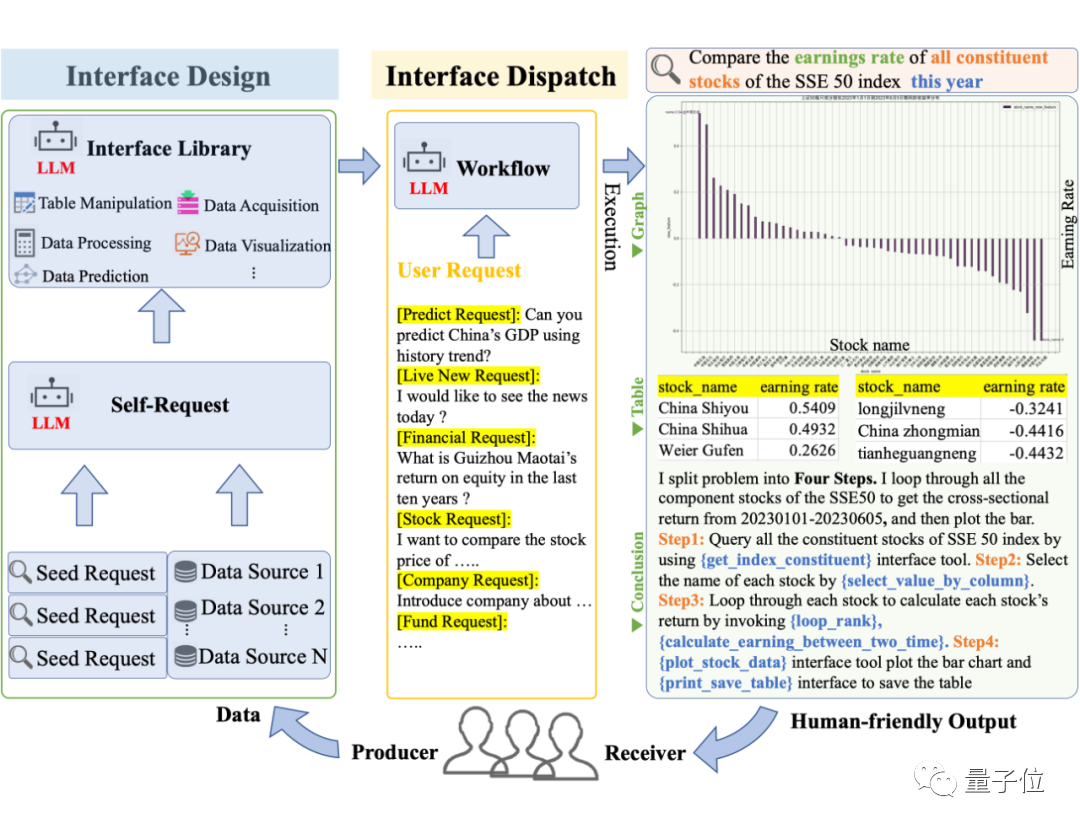
Autant prendre l'exemple suivant pour voir les performances de Data-Copilot :
Quel est le taux de croissance d'une année sur l'autre du bénéfice net de tous les titres constitutifs du Indice Shanghai Stock Exchange 50 au premier trimestre de cette année
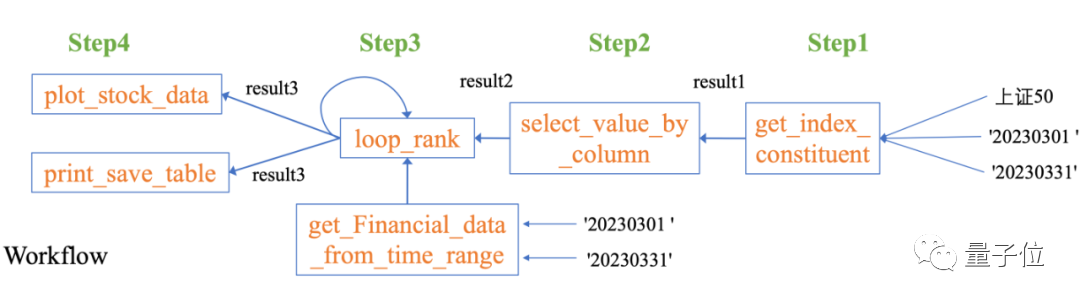
Data-Copilot Nous avons conçu indépendamment un tel flux de travail :
 Photos
Photos
Pour résoudre ce problème complexe, Data-Copilot utilise l'interface loop_rank pour implémenter plusieurs requêtes en boucle .
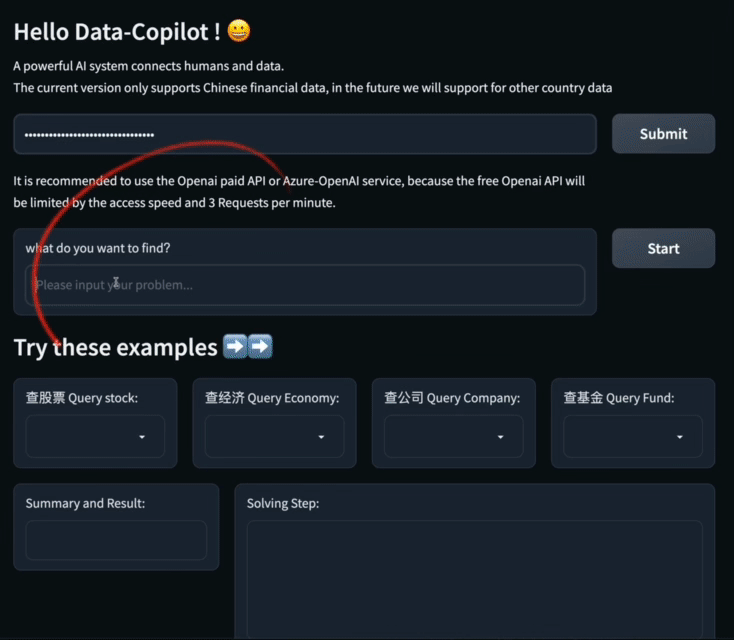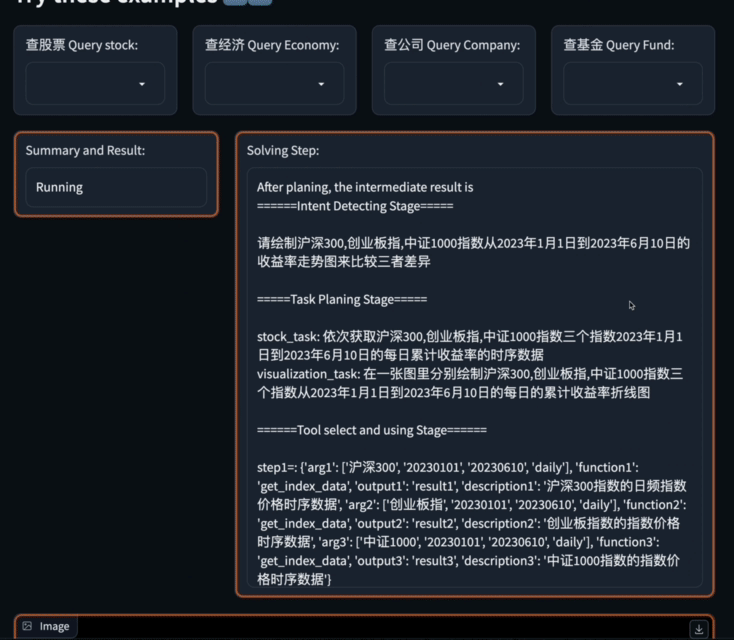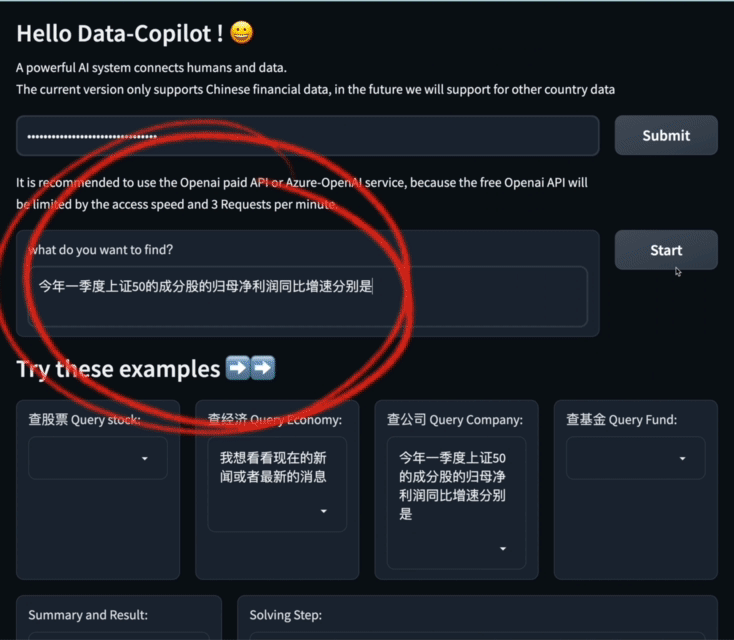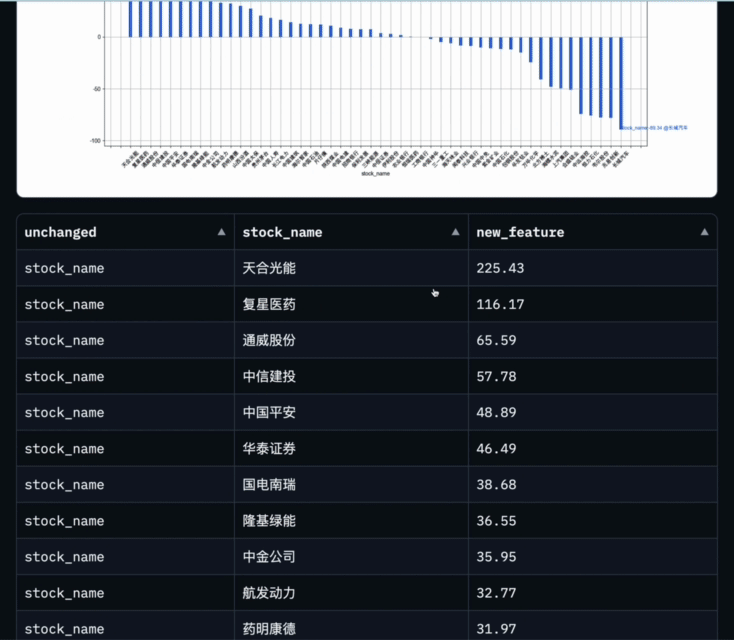
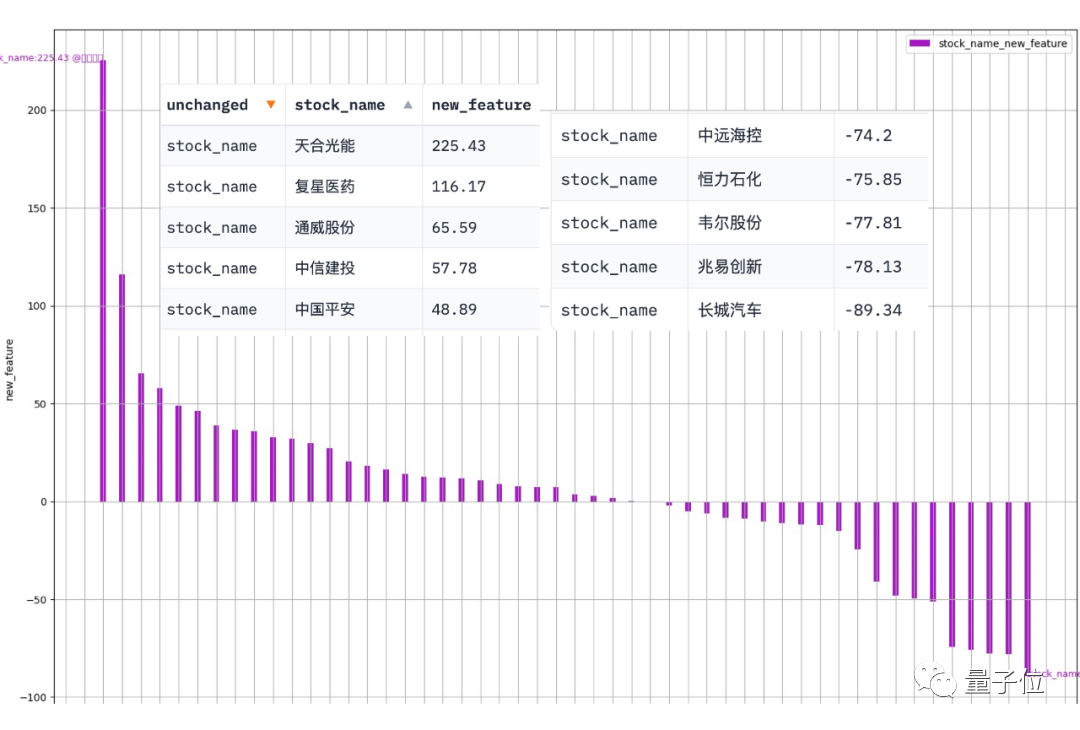
Data-Copilot a obtenu ce résultat après avoir exécuté ce workflow :
L'abscisse est le nom de chaque stock de composants, et l'ordonnée est le taux de croissance d'une année sur l'autre du bénéfice net au premier trimestre
 Photos
Photos
En plus des processus généraux de traitement des données, Data-Copilot peut également générer une grande variété de flux de travail.
L'équipe de recherche a testé Data-Copilot dans deux modes de flux de travail : prédictif et parallèle.
Flux de travail de prévision
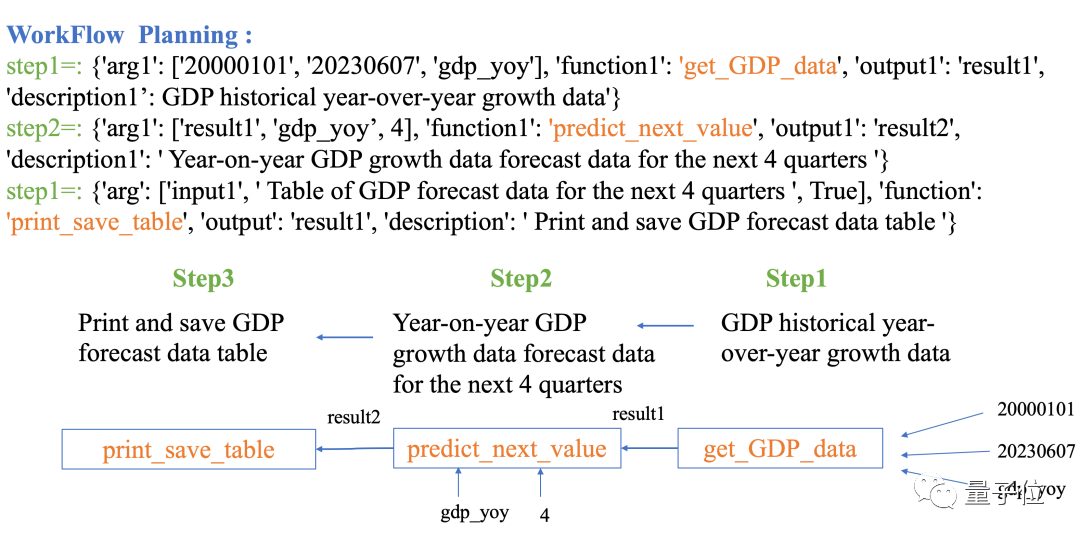
Data-Copilot peut également prédire des parties autres que les données connues. Par exemple, saisissez la question suivante :
Prédire le PIB trimestriel de la Chine au cours des quatre trimestres suivants
Data-Copilot déploie ce flux de travail :
Obtenir l'historique. Données PIB → Utiliser un modèle de régression linéaire pour prédire l'avenir → Tableau de sortie
 image
image
Les résultats après exécution sont les suivants :
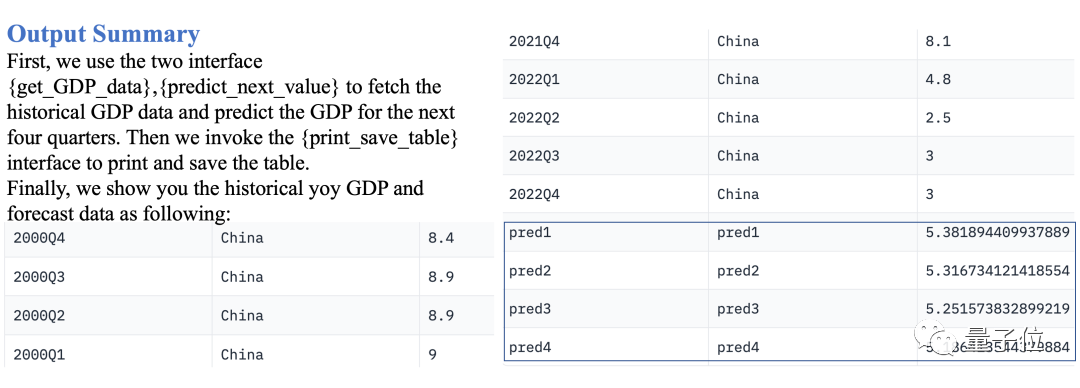 Photos
Photos
Flux de travail parallèle
Je veux voir les ratios cours/bénéfice de CATL et Kweichow Moutai au cours des trois dernières années
Le flux de travail correspondant est :
Obtenir les données sur le cours des actions → Calculer les indices associés → Générer des graphiques
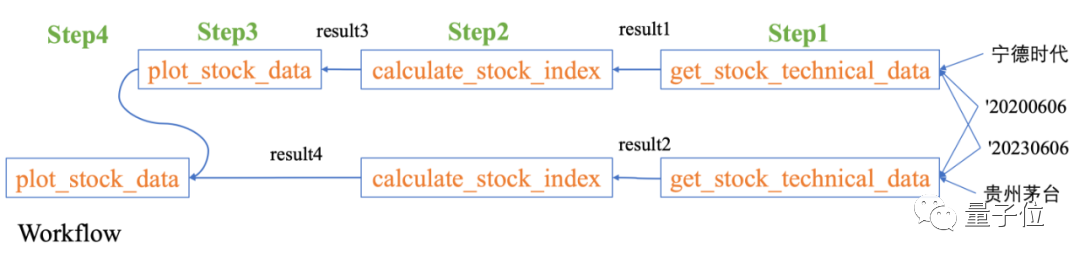 Image
Image
Le travail lié des deux actions est parallèle en même temps, et le graphique final est le suivant :
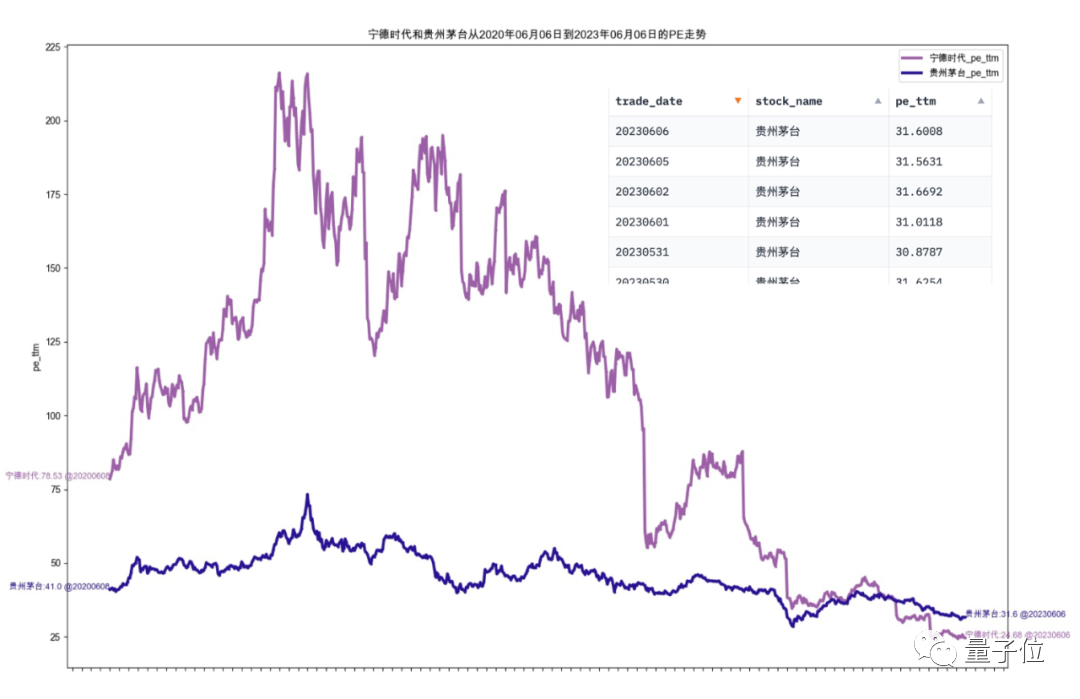 Image
Image
Méthode principale
Data-Copilot est une méthode générale grand système de modèle de langage avec conception d'interface et Il y a deux étapes principales dans la planification de l'interface.
- Conception de l'interface : l'équipe de recherche a conçu un processus d'auto-demande pour permettre à LLM de générer de manière autonome suffisamment de demandes à partir d'un petit nombre de demandes de semences. Ensuite, LLM conçoit et optimise de manière itérative l’interface en fonction des requêtes générées. Ces interfaces sont décrites en langage naturel, ce qui les rend faciles à étendre et à transférer entre différentes plateformes.
- Planification de l'interface : après avoir reçu les demandes des utilisateurs, LLM planifie et appelle des outils d'interface basés sur des descriptions d'interface auto-conçues et des démonstrations en contexte, déploie un flux de travail qui répond aux besoins des utilisateurs et présente les résultats aux utilisateurs sous plusieurs formes.
Data-Copilot réalise un traitement et une visualisation hautement automatisés des données en générant automatiquement des requêtes et en concevant indépendamment des interfaces pour répondre aux besoins des utilisateurs et afficher les résultats aux utilisateurs sous diverses formes.
 Photos
Photos
Conception de l'interface
Comme le montre l'image ci-dessus, la gestion des données doit être mise en œuvre en premier et la première étape nécessite des outils d'interface.
Data-Copilot concevra un grand nombre d'interfaces comme outils de gestion de données. Les interfaces sont des modules composés de langage naturel (description fonctionnelle) et de code (implémentation), qui sont responsables de tâches telles que l'acquisition et le traitement des données.
- Tout d'abord, LLM utilise un petit nombre de requêtes de seed et génère indépendamment un grand nombre de requêtes (explorer les données par auto-demande) pour couvrir autant que possible divers scénarios d'application.
- Ensuite, LLM conçoit les interfaces correspondantes à ces requêtes (définition de l'interface : inclut uniquement la description et les paramètres), et optimise progressivement la conception de l'interface (fusion d'interfaces) à chaque itération.
- Enfin, les chercheurs ont utilisé les puissantes capacités de génération de code de LLM pour générer du code spécifique (implémentation d’interface) pour chaque interface de la bibliothèque d’interfaces. Ce processus sépare la conception de l'interface de la mise en œuvre spécifique, créant ainsi un ensemble polyvalent d'outils d'interface pouvant satisfaire la plupart des demandes.
Comme indiqué ci-dessous : Outil d'interface conçu par Data-Copilot pour le traitement des données
 image
image
Planification de l'interface
Au cours de l'étape précédente, les chercheurs ont obtenu divers outils pour l'acquisition, le traitement et la visualisation des données. Outils d'interface communs. Chaque interface possède une description fonctionnelle claire et explicite. Comme le montre la figure ci-dessus pour les deux requêtes, Data-Copilot forme un flux de travail allant des données aux résultats sous plusieurs formulaires en planifiant et en appelant différentes interfaces dans des requêtes en temps réel.
- Data-Copilot effectue d'abord une analyse d'intention pour comprendre avec précision la demande de l'utilisateur.
- Une fois l'intention de l'utilisateur comprise avec précision, Data-Copilot planifiera un flux de travail raisonnable pour traiter la demande de l'utilisateur. Data-Copilot générera un JSON au format fixe qui représente chaque étape de la planification, tel que step={"arg":"", "function":"", "output":""", "description":""} .
Guidé par des descriptions d'interfaces et des exemples, Data-Copilot orchestre la planification des interfaces au sein de chaque étape, soit séquentiellement, soit en parallèle.
Data-Copilot réduit considérablement la dépendance à l'égard d'un travail et d'une expertise fastidieux en intégrant des LLM à chaque étape des tâches liées aux données, transformant automatiquement les données brutes en résultats de visualisation conviviaux basés sur les demandes des utilisateurs.
Page du projet GitHub : https://github.com/zwq2018/Data-Copilot
Adresse papier : https://arxiv.org/abs/2306.07209
HuggingFace DÉMO : https://huggingface .co/spaces/zwq2018/Data-Copilot
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI