
Maison >Périphériques technologiques >IA >L'image de votre cerveau peut désormais être restaurée en haute définition
L'image de votre cerveau peut désormais être restaurée en haute définition

- 王林avant
- 2023-07-06 19:17:231221parcourir
Ces dernières années, de grands progrès ont été réalisés dans le domaine de la génération d'images, en particulier dans la génération de texte en image : tant que nous utilisons du texte pour décrire nos pensées, l'IA peut générer des images nouvelles et réalistes.
Mais en réalité, nous pouvons aller plus loin : l'étape de conversion des idées dans l'esprit en texte peut être omise et la création d'images peut être contrôlée directement par l'activité cérébrale (comme l'enregistrement EEG (électroencéphalogramme)).
Cette méthode de génération « penser à l'image » a de larges perspectives d'application. Par exemple, il peut grandement améliorer l'efficacité de la création artistique et aider les gens à capter une inspiration éphémère ; il peut également être possible de visualiser les rêves des gens la nuit ; il peut même être utilisé en psychothérapie pour aider les enfants autistes et les patients souffrant de troubles du langage.
Récemment, des chercheurs de l'école supérieure internationale de Shenzhen de l'université Tsinghua, du Tencent AI Lab et du laboratoire Pengcheng ont publié conjointement un document de recherche sur « Penser à l'image », en utilisant des modèles texte-image pré-entraînés (tels que la diffusion stable)' Les puissantes capacités de génération de l'appareil génèrent des images de haute qualité directement à partir des signaux EEG.
 Photos
Photos
Adresse papier : https://arxiv.org/pdf/2306.16934.pdf
Adresse du projet : https://github.com/bbaaii/DreamDiffusion
Metho d aperçu
Certaines recherches récentes (telles que MinD-Vis) tentent de reconstruire des informations visuelles basées sur l'IRMf (signaux d'imagerie par résonance magnétique fonctionnelle). Ils ont démontré la faisabilité d’utiliser l’activité cérébrale pour reconstruire des résultats de haute qualité. Cependant, ces méthodes sont encore loin de l'utilisation idéale des signaux cérébraux pour une création rapide et efficace. Cela est principalement dû à deux raisons :
Premièrement, l'équipement IRMf n'est pas portable et nécessite des professionnels pour fonctionner, donc la capture des signaux IRMf est très importante. difficile ;
Deuxièmement, le coût de la collecte de données IRMf est élevé, ce qui entravera grandement l'utilisation de cette méthode dans la création artistique réelle.
En revanche, l’EEG est une méthode non invasive et peu coûteuse d’enregistrement de l’activité électrique cérébrale, et il existe désormais sur le marché des produits commerciaux portables capables d’obtenir des signaux EEG.
Mais il reste encore deux défis principaux à relever pour parvenir à la génération de « pensée en image » :
1) Les signaux EEG sont capturés par des méthodes non invasives, ils sont donc intrinsèquement bruyants. De plus, les données EEG sont limitées et les différences individuelles ne peuvent être ignorées. Alors, comment obtenir des représentations sémantiques efficaces et robustes à partir de signaux EEG sous autant de contraintes ?
2) Les espaces de texte et d'image dans Stable Diffusion sont bien alignés grâce à l'utilisation de CLIP et à la formation sur un grand nombre de paires texte-image. Cependant, les signaux EEG ont leurs propres caractéristiques et leur espace est très différent du texte et des images. Comment aligner les espaces EEG, texte et image sur des paires EEG - image limitées et bruitées ?
Pour relever le premier défi, cette étude propose d'utiliser de grandes quantités de données EEG pour entraîner les représentations EEG au lieu de seulement de rares paires d'images EEG. Cette étude utilise une méthode de modélisation de signaux masqués pour prédire les jetons manquants sur la base d'indices contextuels.
Contrairement à MAE et MinD-Vis, qui traitent l'entrée comme une image bidimensionnelle et masquent les informations spatiales, cette étude considère les caractéristiques temporelles du signal EEG et approfondit la sémantique derrière les changements temporels dans le cerveau humain. . Cette étude a bloqué aléatoirement une partie des jetons puis a reconstruit ces jetons bloqués dans le domaine temporel. De cette manière, l’encodeur pré-entraîné est capable de développer une compréhension approfondie des données EEG de différents individus et de différentes activités cérébrales.
Pour le deuxième défi, les solutions précédentes affinent généralement directement le modèle de diffusion stable, en utilisant un petit nombre de paires de données bruitées pour l'entraînement. Cependant, il est difficile d’apprendre un alignement précis entre les signaux cérébraux (par exemple, EEG et IRMf) et l’espace de texte en ajustant uniquement la SD de bout en bout jusqu’à la perte finale de reconstruction de l’image. Par conséquent, l’équipe de recherche a proposé d’utiliser une supervision CLIP supplémentaire pour aider à obtenir l’alignement des espaces EEG, texte et image.
Plus précisément, SD lui-même utilise l'encodeur de texte de CLIP pour générer des intégrations de texte, ce qui est très différent des intégrations EEG pré-entraînées masquées de l'étape précédente. Tirez parti de l'encodeur d'image de CLIP pour extraire des intégrations d'images riches qui sont bien alignées avec les intégrations de texte de CLIP. Ces intégrations d'images CLIP ont ensuite été utilisées pour affiner davantage la représentation de l'intégration EEG. Par conséquent, les intégrations améliorées des fonctionnalités EEG peuvent être bien alignées avec les intégrations d'images et de texte de CLIP et sont plus adaptées à la génération d'images SD, améliorant ainsi la qualité des images générées.
Basée sur les deux solutions soigneusement conçues ci-dessus, cette recherche propose une nouvelle méthode DreamDiffusion. DreamDiffusion génère des images réalistes et de haute qualité à partir de signaux d'électroencéphalogramme (EEG).
 Photos
Photos
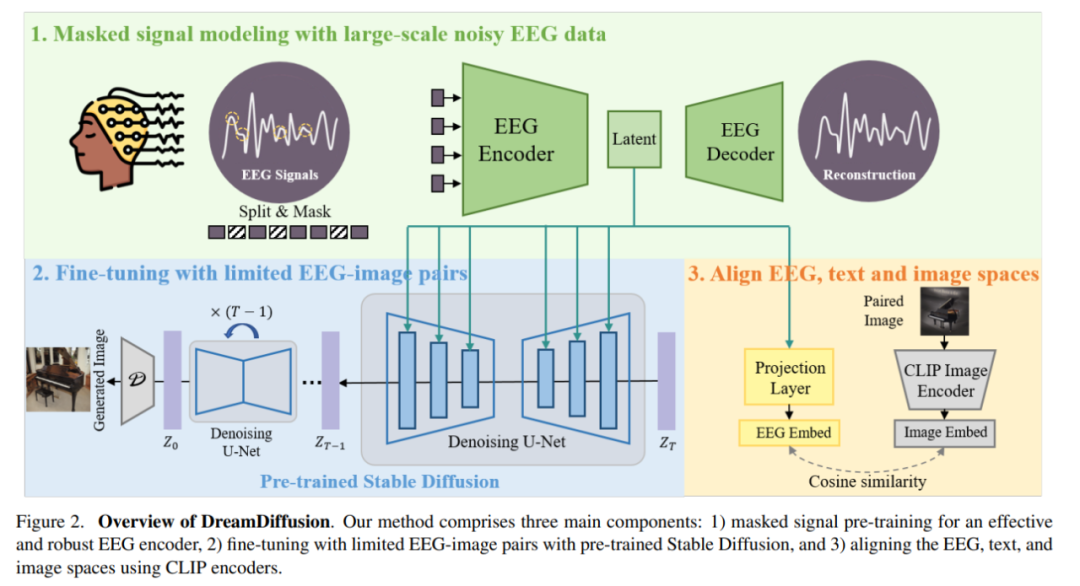
Plus précisément, DreamDiffusion se compose principalement de trois parties :
1) Pré-entraînement au signal de masque pour obtenir un encodeur EEG efficace et robuste
2) Utiliser un pré-entraînement stable ; Diffusion et paires d'images EEG limitées pour un réglage fin ;
3) Utilisez l'encodeur CLIP pour aligner les espaces EEG, texte et image.
Tout d'abord, les chercheurs ont utilisé des données EEG avec beaucoup de bruit et ont utilisé la modélisation du signal de masque pour entraîner l'encodeur EEG et extraire des connaissances contextuelles. L'encodeur EEG résultant est ensuite utilisé pour fournir des caractéristiques conditionnelles pour une diffusion stable via un mécanisme d'attention croisée.
 Photos
Photos
Pour améliorer la compatibilité des fonctionnalités EEG avec la diffusion stable, les chercheurs ont davantage aligné l'EEG, le texte et l'image en réduisant la distance entre l'intégration EEG et l'intégration de l'image CLIP pendant le réglage fin processus.
Expériences et analyses
Comparaison avec Brain2Image
Les chercheurs ont comparé la méthode présentée dans cet article avec Brain2Image. Brain2Image utilise des modèles génératifs traditionnels, à savoir des auto-encodeurs variationnels (VAE) et des réseaux contradictoires génératifs (GAN), pour la conversion de l'EEG en images. Cependant, Brain2Image ne fournit que des résultats pour quelques catégories et ne fournit pas d'implémentation de référence.
Dans cet esprit, cette étude a effectué une comparaison qualitative de plusieurs catégories présentées dans l'article Brain2Image (c'est-à-dire les avions, les citrouilles-lanternes et les pandas). Pour garantir une comparaison équitable, les chercheurs ont utilisé la même stratégie d'évaluation que celle décrite dans l'article Brain2Image et montrent les résultats générés par les différentes méthodes dans la figure 5 ci-dessous.
La première ligne de la figure ci-dessous montre les résultats générés par Brain2Image, et la dernière ligne est générée par DreamDiffusion, la méthode proposée par les chercheurs. On constate que la qualité de l'image générée par DreamDiffusion est nettement supérieure à celle générée par Brain2Image, ce qui vérifie également l'efficacité de cette méthode.
 Photos
Photos
Expérience d'ablation
Le rôle de la pré-entraînement : Pour démontrer l'efficacité de la pré-entraînement des données EEG à grande échelle, cette étude a utilisé des encodeurs non entraînés pour entraîner Validez plusieurs modèles. L'un des modèles était identique au modèle complet, tandis que l'autre modèle ne comportait que deux couches de codage EEG pour éviter un surajustement des données. Au cours du processus de formation, les deux modèles ont été formés avec/sans supervision CLIP, et les résultats sont présentés dans les colonnes 1 à 4 du modèle dans le tableau 1. On peut constater que la précision du modèle sans pré-entraînement est réduite.
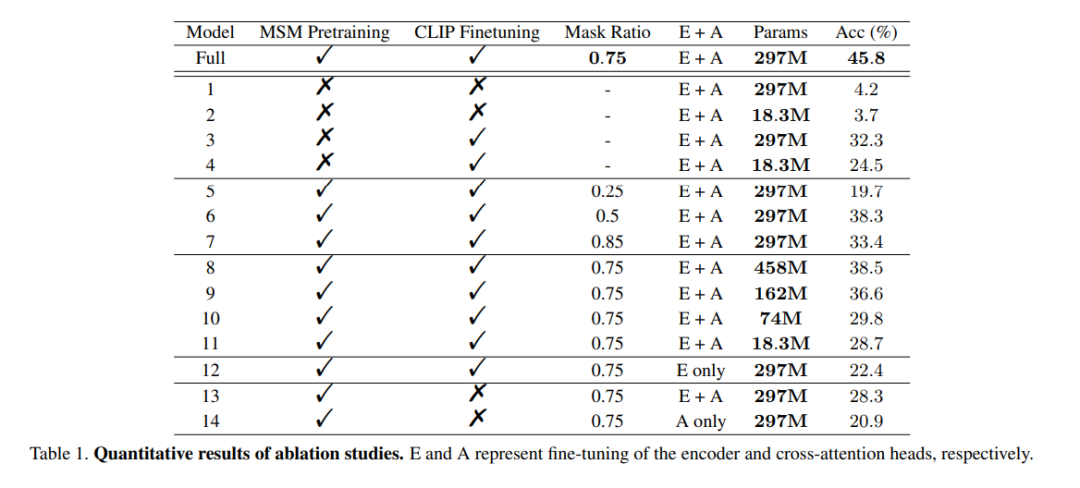
rapport de masque : Cet article étudie également l'utilisation des données EEG pour déterminer le rapport de masque optimal pour la pré-entraînement des HSH. Comme le montrent les colonnes 5 à 7 du modèle du tableau 1, un rapport de masque trop élevé ou trop faible peut nuire aux performances du modèle. La précision globale la plus élevée est obtenue lorsque le rapport de masque est de 0,75. Cette découverte est cruciale car elle suggère que, contrairement au traitement du langage naturel, qui utilise généralement de faibles ratios de masque, des ratios de masque élevés constituent un meilleur choix lors de la réalisation de MSM sur EEG.
Alignement CLIP : L'une des clés de cette méthode est d'aligner la représentation EEG sur l'image via un encodeur CLIP. Cette étude a mené des expériences pour vérifier l'efficacité de cette méthode, et les résultats sont présentés dans le tableau 1. On peut observer que les performances du modèle chutent considérablement lorsque la supervision CLIP n'est pas utilisée. En fait, comme le montre le coin inférieur droit de la figure 6, l'utilisation de CLIP pour aligner les caractéristiques EEG peut toujours donner des résultats raisonnables même sans pré-entraînement, ce qui souligne l'importance de la supervision CLIP dans cette méthode.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI