
Maison >Périphériques technologiques >IA >Le serveur est surchargé, le grand modèle juridique ChatLaw de l'Université de Pékin est populaire : dites-vous directement comment Zhang San a été condamné
Le serveur est surchargé, le grand modèle juridique ChatLaw de l'Université de Pékin est populaire : dites-vous directement comment Zhang San a été condamné

- PHPzavant
- 2023-07-05 09:21:161505parcourir
Le grand modèle a encore "explosé".
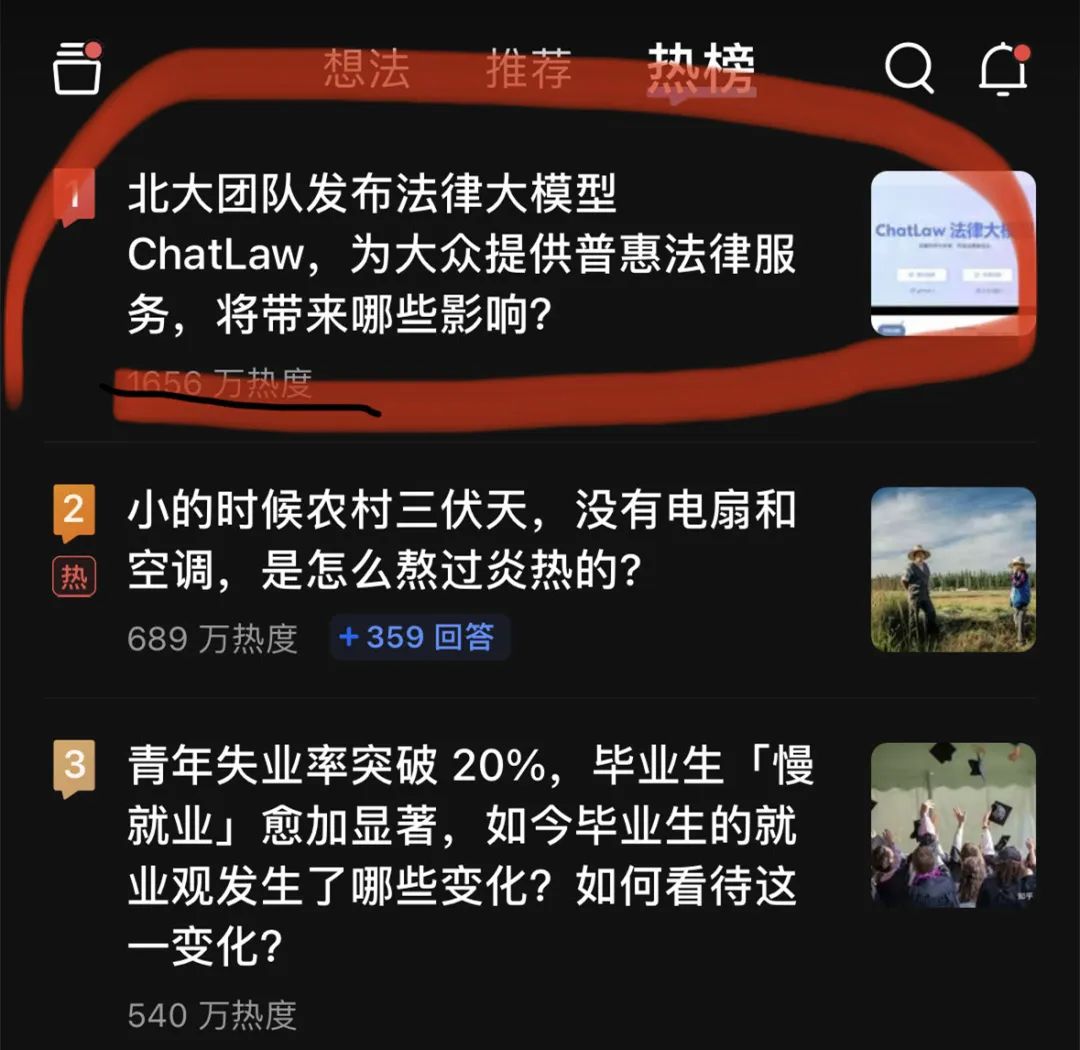
Hier soir, un grand modèle juridique, ChatLaw, était en tête de la liste de recherche chaude de Zhihu. À son apogée, la popularité atteignait environ 20 millions.
Ce ChatLaw est publié par l'équipe de l'Université de Pékin et s'engage à fournir des services juridiques inclusifs. D'une part, il y a actuellement une pénurie d'avocats en exercice dans tout le pays, et l'offre est bien inférieure à la demande juridique ; d'autre part, les gens ordinaires ont un manque naturel de connaissances et de dispositions juridiques et sont incapables d'utiliser armes légales pour se protéger.
La récente montée en puissance des grands modèles linguistiques offre aux gens ordinaires une excellente opportunité de consulter sur des questions juridiques de manière conversationnelle.
Actuellement, il existe trois versions de ChatLaw, comme suit :
- ChatLaw-13B, qui est une version de démonstration académique et est formée sur la base de Jiang Ziya Ziya-LLaMA-13B-v1. Fonctionne très bien en chinois. Cependant, les questions et réponses juridiques logiquement complexes ne sont pas efficaces et doivent être résolues avec un modèle avec des paramètres plus larges.
- ChatLaw-33B, également une version de démonstration académique, est formé sur la base d'Anima-33B et de sa capacité de raisonnement logique ; est grandement amélioré. Cependant, comme Anima dispose de trop peu de corpus chinois, les données en anglais apparaissent souvent lors des questions-réponses.
- ChatLaw-Text2Vec, en utilisant un ensemble de données composé de 930 000 cas de jugement, a entraîné un modèle de correspondance de similarité basé sur BERT, qui peut poser des questions aux utilisateurs. les informations correspondent aux dispositions légales correspondantes.
Selon la démonstration officielle, ChatLaw aide les utilisateurs à télécharger des documents juridiques tels que des documents et des enregistrements, les aidant à résumer et analyser, et à générer des cartes visuelles, des graphiques, etc. De plus, ChatLaw peut générer des conseils juridiques et des documents juridiques basés sur des faits. Le projet compte 1,1k étoiles sur GitHub.
 Photos
Photos
Adresse officielle du site Web : https://www.chatlaw.cloud/
Adresse papier : https://arxiv.org/pdf/2306.16092.pdf
C'est Lien vers le projet GitHub : https://github.com/PKU-YuanGroup/ChatLaw
Actuellement, en raison de la popularité du projet ChatLaw, le serveur est temporairement tombé en panne et la puissance de calcul a atteint la limite supérieure. L'équipe travaille sur un correctif et les lecteurs intéressés peuvent déployer le modèle bêta sur GitHub.
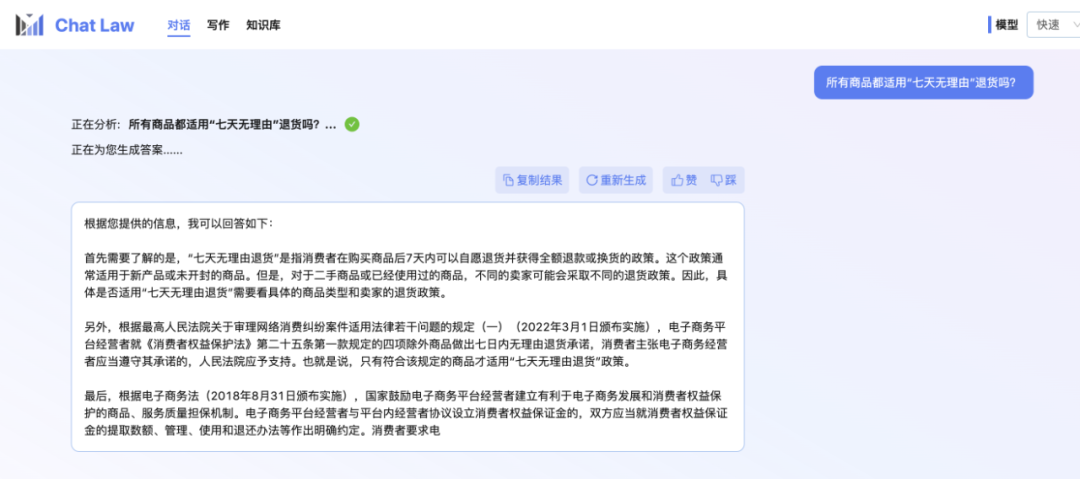
L'éditeur lui-même est toujours dans la file d'attente pour les tests bêta fermés. Voici donc un exemple de conversation officielle fourni par l'équipe ChatLaw, à propos du problème de « retour sans raison sous sept jours » que vous pouvez rencontrer lors de vos achats en ligne. Je dois dire que les réponses de ChatLaw sont assez complètes.
 Photos
Photos
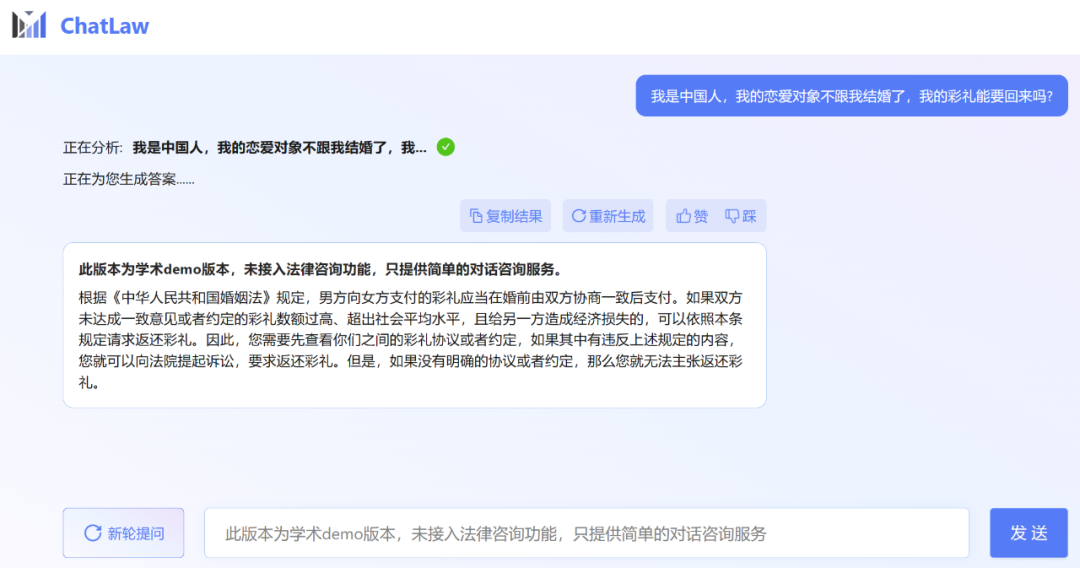
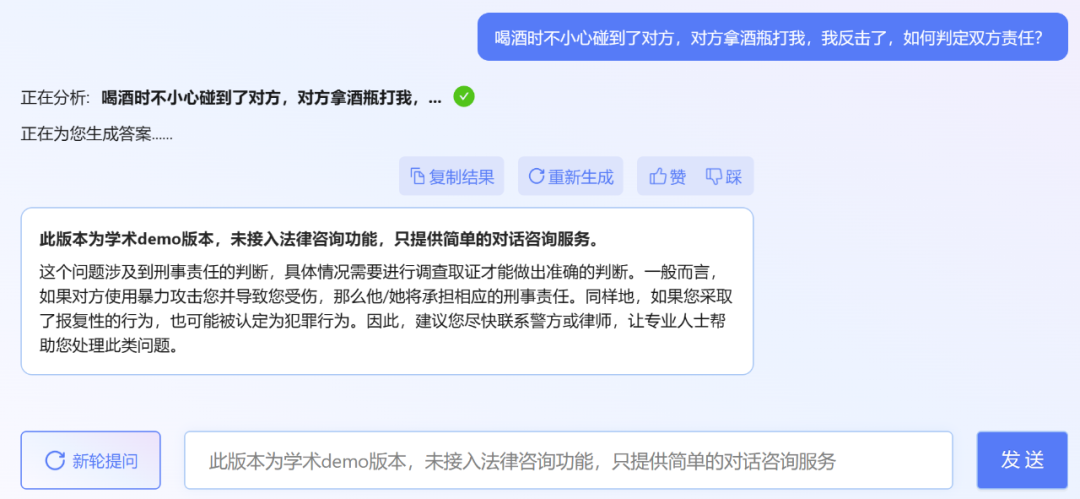
Cependant, l'éditeur a constaté que la version de démonstration académique de ChatLaw peut être essayée. Malheureusement, elle n'a pas accès à la fonction de consultation juridique et ne fournit que de simples services de consultation de dialogue. Voici quelques questions à essayer.
 Photos
Photos
En fait, l'Université de Pékin n'est pas la seule à publier récemment de grands modèles juridiques. À la fin du mois dernier, Power Law Intelligence et Zhipu AI ont publié le modèle vertical juridique PowerLawGLM, doté de 100 milliards de paramètres. Il est rapporté que le modèle a montré des avantages uniques dans son application dans les scénarios juridiques chinois.
Source de données et cadre de formation de ChatLaw
Le premier est la composition des données. Les données ChatLaw sont principalement constituées de forums, d'actualités, de dispositions juridiques, d'interprétations judiciaires, de consultations juridiques, de questions d'examen juridique et de documents de jugement. Les données de conversation sont ensuite construites par nettoyage, amélioration des données, etc. Dans le même temps, en coopérant avec l'École de droit international de l'Université de Pékin et des cabinets d'avocats renommés du secteur, l'équipe ChatLaw peut garantir que la base de connaissances peut être mise à jour en temps opportun tout en garantissant le professionnalisme et la fiabilité des données. Examinons des exemples spécifiques ci-dessous.
Exemples de construction basés sur les lois, règlements et interprétations judiciaires :

Exemple de saisie de données réelles de consultation juridique :

Exemple de construction de questions à choix multiples pour l'examen du barreau :
 Photos
Photos
Ensuite, il y a le niveau modèle. Pour entraîner ChatLAW, l’équipe de recherche l’a peaufiné à l’aide de l’adaptation de bas rang (LoRA) basée sur Ziya-LLaMA-13B. De plus, cette étude introduit également le rôle d'autosuggestion pour atténuer le problème des hallucinations modèles. Le processus de formation est effectué sur plusieurs GPU A100, avec une vitesse profonde réduisant encore les coûts de formation.
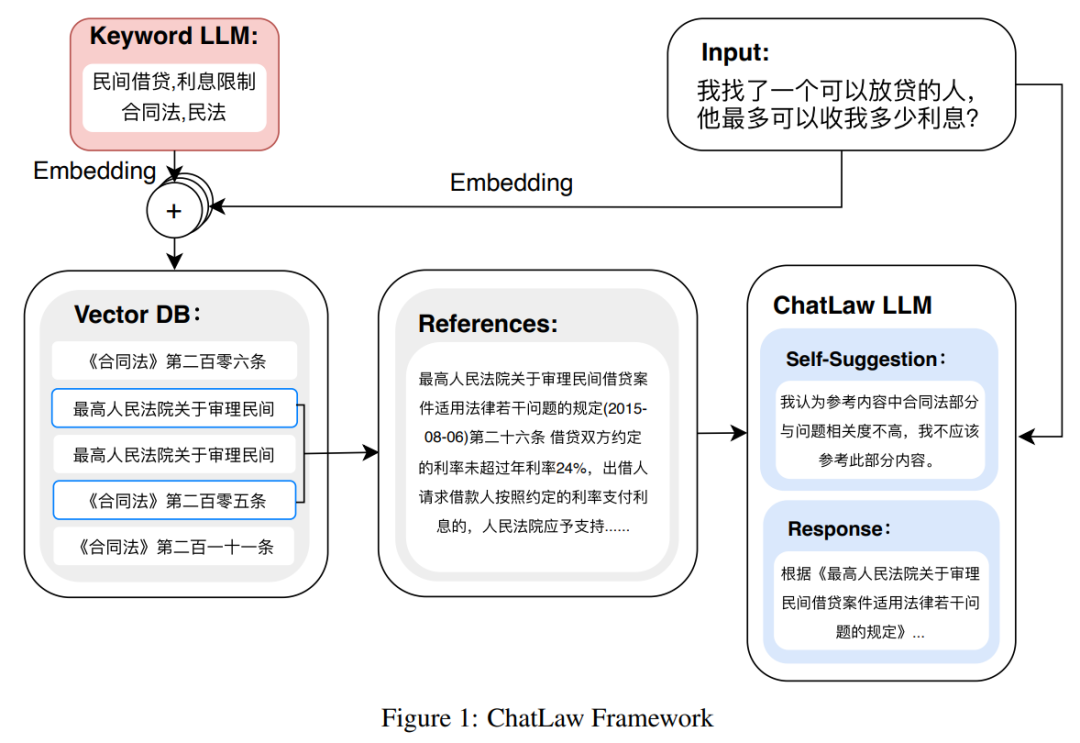
La figure suivante est le schéma d'architecture de ChatLAW. Cette recherche injecte des données juridiques dans le modèle et effectue un traitement spécial et une amélioration de ces connaissances. En même temps, elles introduisent également plusieurs modules lors du raisonnement pour combiner modèle général et professionnel. modèle intégré à la base de connaissances.
Cette étude a également contraint le modèle lors de l'inférence, afin de garantir que le modèle génère des lois et réglementations correctes et de réduire autant que possible les illusions du modèle.
 Photos
Photos
Au début, l'équipe de recherche a essayé des méthodes traditionnelles de développement de logiciels, telles que l'utilisation de MySQL et Elasticsearch pour la récupération, mais les résultats n'ont pas été satisfaisants. Par conséquent, cette recherche a commencé en essayant de pré-entraîner le modèle BERT pour l'intégration, puis en utilisant des méthodes telles que Faiss pour calculer la similarité cosinus et extraire les k principales lois et réglementations liées à la requête de l'utilisateur.
Cette approche produit souvent des résultats sous-optimaux lorsque le problème de l'utilisateur est vague. Par conséquent, les chercheurs extraient les informations clés des requêtes des utilisateurs et conçoivent des algorithmes en utilisant l’intégration vectorielle de ces informations pour améliorer la précision de la correspondance.
Étant donné que les grands modèles présentent des avantages significatifs dans la compréhension des requêtes des utilisateurs, cette étude a affiné LLM pour extraire des mots-clés des requêtes des utilisateurs. Après avoir obtenu plusieurs mots-clés, l’étude a utilisé l’algorithme 1 pour récupérer les dispositions juridiques pertinentes.
 Photos
Photos
Résultats expérimentaux
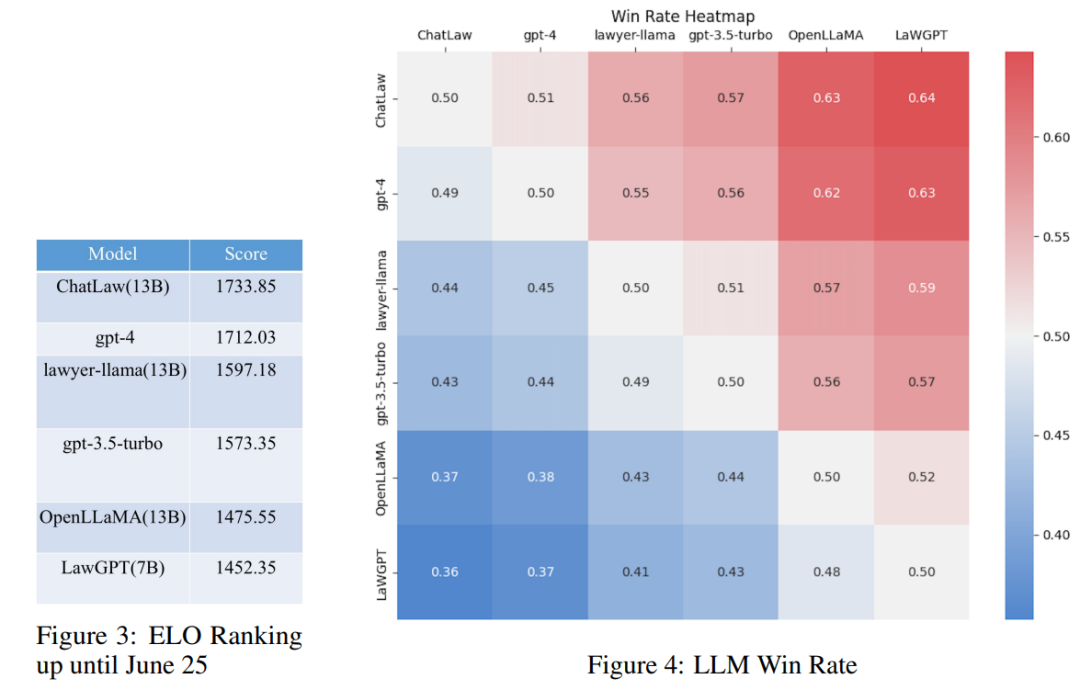
Cette étude a collecté des questions d'examen judiciaire national pendant plus de dix ans et compilé un ensemble de données de test contenant 2000 questions et leurs réponses standard pour mesurer le modèle Capacité à gérer des choix multiples questions juridiques.
Cependant, des recherches ont révélé que la précision de chaque modèle est généralement faible. Dans ce cas, comparer la précision ne signifie pas grand-chose. Par conséquent, cette étude s'appuie sur le mécanisme de correspondance ELO de League of Legends et crée un mécanisme modèle contre ELO pour évaluer plus efficacement la capacité de chaque modèle à gérer les questions juridiques à choix multiples. Voici respectivement les scores ELO et les tableaux des taux de réussite :
 Photos
Photos
En analysant les résultats expérimentaux ci-dessus, nous pouvons tirer les observations suivantes
(1) Présentation des questions et réponses d'ordre juridique et dispositions réglementaires Les données peuvent améliorer dans une certaine mesure les performances du modèle sur les questions à choix multiples ;
(2) Ajoutez des données de types spécifiques de tâches pour la formation, et les performances du modèle sur ce type de tâches seront considérablement améliorées. Par exemple, la raison pour laquelle le modèle ChatLaw est meilleur que GPT-4 est que l'article utilise un grand nombre de questions à choix multiples comme données de formation
(3) Les questions juridiques à choix multiples nécessitent un raisonnement logique complexe, donc ; les modèles avec des paramètres plus grands fonctionnent généralement mieux.
Lien de référence Zhihu :
https://www.zhihu.com/question/610072848
Autres liens de référence :
https://mp.weixin.qq.com/s /bXAFALFY6GQkL30j1sYCEQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI